Download

1 / 16
160 likes | 293 Vues
Mo17 shotgun project. Goal: sequence Mo17 “gene space” with inexpensive new technologies Datasets in progress: Four-phases of 454-FLX sequencing to max of ~12X Include ~3kb paired-end sequencing (for short-range structural variation) Ultra-short-read Solexa or ABI-SOLID (for polishing)

E N D
Mo17 shotgun project • Goal: sequence Mo17 “gene space” with inexpensive new technologies • Datasets in progress: • Four-phases of 454-FLX sequencing to max of ~12X • Include ~3kb paired-end sequencing (for short-range structural variation) • Ultra-short-read Solexa or ABI-SOLID (for polishing) • Preparation of methyl-spanning linkers to augment IBM map integration, detect rearrangements (Sanger end-sequence) • (Ideally would add Mo17 BAC-ends from DuPont, if available)
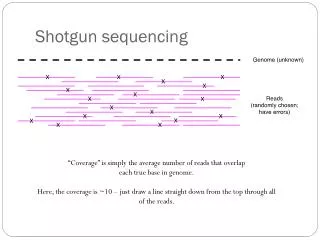
Shotgun • Independent of tiling path -Can detect non-repetitive gene space even within otherwise complex regions that may not be in tiling path • Disadvantages of short-reads -Can’t expect to recover repetitive sequences
Four Phases of Sequencing Complete in 2007 • Sequencing contract established with 454/Roche. Four Phases, including “collaborative” runs at no cost in P2-4. • Phase I underway (30 FLX runs.) Library QC and initial assessment of data quality (30 FLX runs). • 10 FLX runs totaling 1 Gb (~0.4X) • 20 FLX pair runs spanning 12 Gb (~5X span in 3kb inserts) • Assess quality, coverage, contamination, chimerism, accuracy • Phase II. (80 runs plus 30 runs from Roche, total 110 runs). Rough draft stage. • 40 FLX-pair runs spanning 36 Gb (total 48 Gb~10X span) • 70 FLX runs for 7 Gb (total 8Gb ~3.5X sequence) • Assess rough draft assembly (3 methods), compare B73, sorghum
Phases III and IV • Phase III (50 runs + 20 contributed) • 20 FLX-pair runs (total spanning cover ~20X) • 50 FLX runs (total 13 Gb sequence ~5.5X) • Draft assembly. Rough annnotation. Assessment of structural • variation based on 20X “clone” cover. Assessment complete by • end of 2007. • Phase IV (60 runs + 30 contributed) • 90 FLX runs (to reach total 22 Gb ~10X) • Data collection complete by end of 2007. • Early ‘08. Final assembly. Integration with MSSL ends and IBM • map. Proceed to annotation and full analysis. • Note: Later phases may use next FLX release with longer • read lengths. To be conservative, sequence from FLX-pair • reads not included in sequence coverage estimates. • Total sequencing cost for Phase I-IV: $1.6M
454-FLX reads are typically either mostly masked, or mostly clean ~29% of reads have < quarter of positions masked ~58% of reads have > 2/3 of positions masked 0 0.5 1.0 Percent masked by over-rep’d 16mers
Mo17 454 unique full length alignments vs. B73 MAGIs show high quality of unique alignments Residual repeats in MAGIs with multiple hits in 454 data Unique full alignments
SNPs and indels of 454 reads relative to MAGIs consistent with few % variation of Mo17/B73 (combines variation with sequencing errors) SNPs or indels per base Frequency of reads
Multiple assembly alternate plans • Divide and conquer • Reduce ~100 million reads to ~50K unique gene • spaces of ~thousands of reads each (~10kb) by • clustering based on various comparisons • Plan A: De novo clustering of masked reads • Plan B: map to B73, assemble (de novo for remainder) • Plan C: sorghum-assisted • Use various assemblers to lay-out and produce • consensus for each cluster (454 assembly team engaged) • Polish sequence with Solexa or SOLID for • accuracy • Link with MSSL pairs, integrate with map
Backup analyses vs. B73 reference • SNP/variation detection by alignment to B73 sequence -454/Solexa/Solid (various successful models in other species at JGI, elsewhere) • Structural variation detection via paired-end placements -Needs to be tolerant of chimerism rate -Model of successful human structural analysis done with 454 (unpublished)
Timeline • Phase I in progress, complete by end of month. Analysis to OK phase II ~10 days. • Phase II: October • Phase III: November • Phase IV: December • 454 sequencing complete by end of year
Outreach Dick McCombie
Types of Outreach • Public presentations • Collaborations • CSHL DNA Learning Center
Collaborations • “The Maize Genetics and Genomics Database.” --Letter • for Carolyn Lawrence-MaizeGDB • MaizeGDB-web site text, links to data • Gramene • EBI Ensembl • Affymetrix Maize Pilot Expression Array Project • Optical map • TWINSCAN • Vmatch • Full-Length cDNA Project
CSHL DNA Learning Center http://www.dnalc.org/maize/maize.html