Download

1 / 12
120 likes | 227 Vues
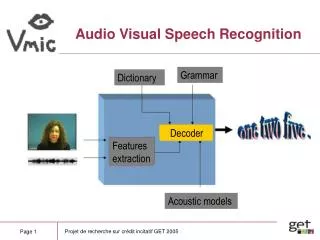
AudioVisual-SpeechRecognition (AVSR). Speech is bimodal essentially. Acoustic and Visual cues. H. McGurk and J. MacDonald, ''Hearing lips and seeing voices'', Nature, pp. 746-748, December 1976.

E N D
AudioVisual-SpeechRecognition (AVSR) • Speech is bimodal essentially. • Acoustic and Visual cues. H. McGurk and J. MacDonald, ''Hearing lips and seeing voices'', Nature, pp. 746-748, December 1976. T. Chen and R. Rao, ''Audio-visual integration in multimodal communication'', Proceedings of the IEEE, Special issue in Multimedia Signal Processing, vol. 86, pp. 837-852, May 1998. D.B. Stork and M.E. Hennecke editors, ''Speechreading by Hummans and Machines. Springer, Berlin Germany, 1996. • Through their integration (fusion), the aim is: • To increase the robustness and performance. There are too many papers, so lets see a few... but from the point of view of integration most of them.
AudioVisual-SpeechRecognition (AVSR) • Tutorials. G. Potamianos, C. Neti, G. Gravier, A. Garg and A.W. Senior. Recent advances in the authomatic recognition of audio-visual speech. ''Proceedings of the IEEE, vil. 91(9), pp. 1306-1326, September 2003. G. Potamianos, C. Neti, J. Luettin and I. Mattews, ''Audio-visual automatic speech recognition: An overview'' In G. Bailly, E. Vatikiotis-Bateson and P. Perrier, edts. Issues in Visual and Audio-visual Speech Processing, Chapter 10. MIT Press, 2004. • Real Conditions. G. Potamianos and C. Neti, ''Audio-visual speech recognition in challenging environments'', In proc. European conference on Speech Technology, pp. 1293-1296, 2003. G. Potamianos, C. Neti, J. Huang, J.H. Connell, S. Chu, V. Libal, E. Marcheret, N. Haas and J. Jiang, ''Towards practical deployement of audio-visual speech recognition'', ICASSP'04, vol. 3, pp. 777-780, Montreal Canada, 2004.
AudioVisual-SpeechRecognition (AVSR) • Increase Robustness and Performance Based on the fact: • Visual modality is independent to most of the lost of acoustic quality. • Visual and Acoustic modalities work in a complementary manner. B. Dodd and R. Campbell, eds, ''Hearing by Eye: The psychology of Lipreading''. London, England. Laurence Erlbaum Associates Ltd., 1987. • But, if the integrations is not well done: Catastrofic fusion. J.R. Movellan and P. Mineiro, ''Modularity and catastrophic fusion: A bayesian approach with applications to audio-visual speech recognition'', Tech. Rep. 97.01, Departement of Cognitive Science, UCSD, San Diego, CA, 1997.
AVSR Integration (Fusion) • Early Integration (EI): • In the feature level, concatenate the features. • But features are not synchronous (VOT)! S. Dupont and J. Luettin, ''Audio-visual speech modeling for continuos speech recognition'', IEEE Transactions on Multimedia, vol. 2, pp. 141-151, September 2000. C. C. Chibelushi, J.S. Mason and F. Deravi, ''Integration of acoustic and visual speech for speaker recognition'', Eurospeech'93, Berlin,pp.157-160, September 1993. voice onset time (VOT)
AVSR Integration (Fusion) • Late Integration (LI): • In the decision level, combine the scores. • Lost of all temporal information! A. Adjoudani and C. Benoit, ''Audio-visual speech recognition compared acroos two architectures'', Eurospeech'95, Madrid Spain, pp. 1563-1566, September 1995. S. Dupont and J. Luettin, ''Audio-visual speech modeling for continuos speech recognition'', IEEE Transactions on Multimedia, vol. 2, pp. 141-151, September 2000. M. Heckmann, F. Berthommier and K. Kroschel, ''Noise adaptive stream weighting in audio-visual speech recognition'', EUROASIP Journal of Applied Signal Processing, vol. 1, pp. 1260-1273, November 2002.
AVSR Integration (Fusion) • Middle Integration (MI) allows: • Specific word or sub-word models. • Synchronous continuous speech recognition. J. Luettin, G. Potamianos and C. Neti, ''Asynchronous stream modeling for large vocabulary audio-visual speech recognition'', ICASSP'01, vol. 1, pp. 169-172, Salt Lake City USA, May 2001. G. Potamianos, J. Luettin and C. Neti, '' Hierarchical discriminant features for audio-visual LVCSR'', ICASSP'01, vol. 1, pp. 165-168, Salt Lake City USA, May 2001.
AVSR Integration, Dynamic Bayesian Networks • Multistream HMM • State synchrony • Weighting the observations A.V. Nefian, L. Liang, X. Pi, X. Liu and K. Murphy, ''Dynamic Bayesian Networks for audio-visual speech recognition'',EURASIP Journal on Applied Signal Processing, vol. 11, pp. 1-15, 2002. G. Potamianos, C. Neti, J. Luettin and I. Mattews, ''Audio-visual automatic speech recognition: An overview'' In G. Bailly, E. Vatikiotis-Bateson and P. Perrier, edts. Issues in Visual and Audio-visual Speech Processing, Chapter 10. MIT Press, 2004. t=T t=0 t=1 t=2
AVSR Integration, Dynamic Bayesian Networks • Product HMM • Asynchrony between the streams • Too many parameters I am not sure about this graphical representation G. Gravier, G. Potamianos and C. Neti, ''Asynchrony modeling for audio-visual speech recognition'', In Human Language Technology Conference, 2002. t=T t=1 t=0 t=2
AVSR Integration, Dynamic Bayesian Networks • Factorial HMM • Transition probabilities are independents for each stream. Z. Ghahramani and M.I. Jordan, ''Factorial hidden markov models'', In Proc. Advances in Neural Information Processing Systems, vol. 8 pp. 472-478, 1985. t=T t=1 t=0 t=2
AVSR Integration, Dynamic Bayesian Networks • Coupled HMM (1/2) • The backbones have a dependence. M. Brand, N. Oliver and A. Pentland, ''Coupled hidden markov models for complex action recognition'', In Proc. IEEE Conf. on Computer Vision and Pattern Recognition, pp. 994-999, 1997. S. Chu and T. Huang, ''Audio-visual speech modeling using coupled hidden markov models'', ICASSP'02, pp. 2009-2012, 2002. t=T t=0 t=1 t=2
AVSR Integration, Dynamic Bayesian Networks • Coupled HMM (2/2) A.V. Nefian, L. Liang, X. Pi, X. Liu and K. Murphy, ''Dynamic Bayesian Networks for audio-visual speech recognition'',EURASIP Journal on Applied Signal Processing, vol. 11, pp. 1-15, 2002. A. Subramanya, S. Gurbuz, E. Patterson, and J.N. Gowdy, ''Audiovisual speech integration using coupled hidden markov models for continous speech recognition'', ICASSP'03, 2003.
AVSR Integration, Dynamic Bayesian Networks • Implicite Modeling J.N. Gowdy, A. Subramanaya, C. Bartels and Jeff Bilmes, ''DBN based Multi-stream models for audio-visula speech recognition'', ICASSP'04, Montreal Canada, 2004. X. Lei, G. Ji, T. Ng, J. Bilmes and M. Ostendorf, ''DBN based Multi-stream for Mandarin Toneme Recognition'', ICASSP'05, Filadelphie USA, 2005.