Download

1 / 35
350 likes | 546 Vues
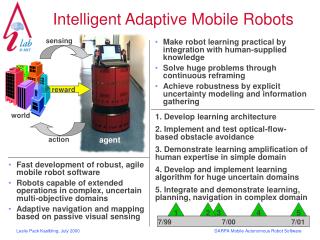
Adaptive Intelligent Mobile Robotics William D. Smart, Presenter Leslie Pack Kaelbling, PI Artificial Intelligence Laboratory MIT. Progress to Date. Fast bootstrapped reinforcement learning algorithmic techniques demo on robot Optical-flow based navigation flow algorithm implemented

E N D
Adaptive Intelligent Mobile Robotics • William D. Smart, Presenter • Leslie Pack Kaelbling, PI • Artificial Intelligence Laboratory • MIT
Progress to Date • Fast bootstrapped reinforcement learning • algorithmic techniques • demo on robot • Optical-flow based navigation • flow algorithm implemented • pilot navigation experiments on robot • pilot navigation experiments in simulation testbed
Making RL Really Work • Typical RL methods require far too much data to be practical in an online setting. Address the problem by • strong generalization techniques • using human input to bootstrap • Let humans do what they’re good at • Let learning algorithms do what they’re good at
JAQL • Learning a value function in a continuous state and action space • based on locally weighted regression (fancy version of nearest neighbor) • algorithm knows what it knows • use meta-knowledge to be conservative about dynamic-programming updates
Problems with Q-Learning on Robots • Huge state spaces/sparse data • Continuous states and actions • Slow to propagate values • Safety during exploration • Lack of initial knowledge
Value Function Approximation • Use a function approximator instead of a table • generalization • deals with continuous spaces and actions • Q-learning with VFA has been shown to diverge, even in benign cases • Which function approximator should we use to minimize problems? s Q(s,a) F a
Locally Weighted Regression • Store all previous data points • Given a query point, find k nearest points • Fit a locally linear model to these points, giving closer ones more weight • Use KD-trees to make lookups more efficient • Fast learning from a single data point
Locally Weighted Regression • Original function
Locally Weighted Regression • Bandwidth = 0.1, 500 training points
Problems with ApproximateQ-Learning • Errors are amplified by backups
Independent Variable Hull • Interpolation is safe; extrapolation is not, so • construct hull around known points • do local regression if the query point is within the hull • give a default prediction if not
Recap • Use LWR to represent the value function • generalization • continuous spaces • Use IVH and “don’t know” • conservative predictions • safer backups
Incorporating Human Input • Humans can help a lot, even if they can’t perform the task very well. • Provide some initial successful trajectories through the space • Trajectories are not used for supervised learning, but to guide the reinforcement-learning methods through useful parts of the space • Learn models of the dynamics of the world and of the reward structure • Once learned models are good, use them to update the value function and policy as well.
Give Some Trajectories • Supply an example policy • Need not be optimal and might be very wrong • Code or human-controlled • Used to generate experience • Follow example policy and record experiences • Shows learner “interesting” parts of the space • “Bad” initial policies might be better
Environment Supplied Control Policy Two Learning Phases Phase One R O A Learning System
Environment Supplied Control Policy Two Learning Phases Phase Two R O A Learning System
What does this Give Us? • Natural way to insert human knowledge • Keeps robot safe in early stages of learning • Bootstraps information into the Q-function
Corridor-Following • 3 continuous state dimensions • corridor angle • offset from middle • distance to end of corridor • 1 continuous action dimension • rotation velocity • Supplied example policy • Average 110 steps to goal
Corridor-Following • Experimental setup • Initial training runs start from roughly the middle of the corridor • Translation speed has a fixed policy • Evaluation on a number of set starting points • Reward • 10 at end of corridor • 0 everywhere else
Corridor-Following Phase 1 Phase 2 Average training “Best” possible
Conclusions • VFA can be made more stable • Locally weighted regression • Independent variable hull • Conservative backups • Bootstrapping value function really helps • Initial supplied trajectories • Two learning phases
Optical Flow • Get range information visually by computing optical flow field • nearer objects cause flow of higher magnitude • expansion pattern means you’re going to hit • rate of expansion tells you when • elegant control laws based on center and rate of expansion (derived from human and fly behavior)
Balance Strategy • Simple obstacle-avoidance strategy • compute flow field • compute average magnitude of flow in each hemi-field • turn away from the side with higher magnitude (because it has closer objects)
Next Steps • Extend RL architecture to include model-learning and planning • Apply RL techniques to tune parameters in optical-flow • Build topological maps using visual information • Build highly complex simulated environment • Integrate planning and learning in multi-layer system











![ARTIFICIAL INTELLIGENCE [INTELLIGENT AGENTS PARADIGM]](https://cdn2.slideserve.com/3770213/artificial-intelligence-intelligent-agents-paradigm-dt.jpg)

![ARTIFICIAL INTELLIGENCE [INTELLIGENT AGENTS PARADIGM]](https://cdn2.slideserve.com/5086381/artificial-intelligence-intelligent-agents-paradigm-dt.jpg)

![ARTIFICIAL INTELLIGENCE [INTELLIGENT AGENTS PARADIGM]](https://cdn2.slideserve.com/5183642/artificial-intelligence-intelligent-agents-paradigm-dt.jpg)





