Download
1 / 12
120 likes | 261 Vues
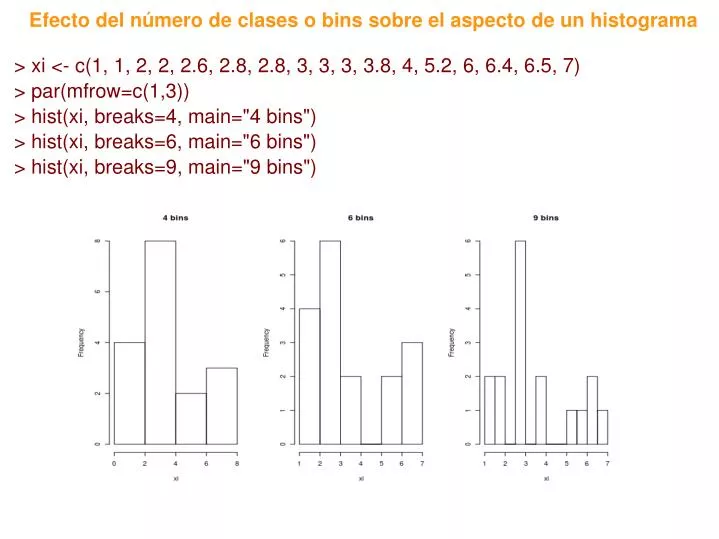
Efecto del número de clases o bins sobre el aspecto de un histograma. > xi <- c(1, 1, 2, 2, 2.6, 2.8, 2.8, 3, 3, 3, 3.8, 4, 5.2, 6, 6.4, 6.5, 7) > par(mfrow=c(1,3)) > hist(xi, breaks=4, main="4 bins") > hist(xi, breaks=6, main="6 bins") > hist(xi, breaks=9, main="9 bins").

E N D
Efecto del número de clases o bins sobre el aspecto de un histograma > xi <- c(1, 1, 2, 2, 2.6, 2.8, 2.8, 3, 3, 3, 3.8, 4, 5.2, 6, 6.4, 6.5, 7) > par(mfrow=c(1,3)) > hist(xi, breaks=4, main="4 bins") > hist(xi, breaks=6, main="6 bins") > hist(xi, breaks=9, main="9 bins")
Efecto del cambio de los límites de las clases > par(mfrow=c(2,2)) > hist(xi, breaks=seq(0,7,1)) > hist(xi, breaks=0.25+seq(0,7,1)) > hist(xi, breaks=0.5+seq(0,7,1)) > hist(xi, breaks=0.75+seq(0,7,1))
¿Qué pasa si “promediamos” los histogramas del paso anterior? Al realizar un gráfico que promedia los valores de densidad de cada uno de los histogramas anteriores, obtenemos un “average shifted histogram (ASH)”. En los histogramas originales tenemos un ancho de bin, h=1, y en ASH promediamos 4 desplazamientos (m=4), determinando un δ= h/m = ¼ = 0.25.
Otra forma de ver la función ASH es como un histograma con ancho de bin δ, y luego se calcula el histograma de ancho de clase h agregando los recuentos de de m clases adyacentes. Si llamamos a los recuentos vk, podemos definir el valor de la función ASH para un punto x como: Ahora, si el número de desplazamientos tiende a infinito obtenemos: Que es un estimador de densidad kernel con un kernel triangular.
La forma más general de un estimador kernel de densidad es: Donde K es el kernel y h el ancho de banda. Algunas opciones comunes de función kernel son: Gausiana Epanechnikov Triangular Existen varios métodos para determinar el valor de h. En general estos métodos buscan minimizar la integral del error cuadrático medio, normalmente por validación cruzada. Tiene un efecto más importante la selección del ancho de banda que la del kernel
Kernel Gaussiano > par(mfrow=c(1,3)) > plot(density(xi), main="ancho de banda (bw) optimizado") > plot(density(xi, bw=0.3), main="bw=0.3") > plot(density(xi, bw=2), main="bw=2")
Kernel Epanechnikov > par(mfrow=c(1,3)) > plot(density(xi, kernel="epanechnikov"), main="ancho de banda (bw) optimizado") > plot(density(xi, kernel="epanechnikov", bw=0.3), main="bw=0.3") > plot(density(xi, kernel="epanechnikov", bw=2), main="bw=2")
Variantes Se puede usar un ancho de banda variable, este tipo de técnicas se conocen como estimadores de densidad kernel adaptativos. Esto es útil, por ejemplo, para aumentar el suavizado en las puntas de la distribución donde hay menos datos, y reducirlo en las proximidades de la moda. Las técnicas de estimación kernel se pueden extender al caso multivariado. No vamos a analizar la teoría en profundidad, pero vamos a considerar algunos puntos importantes: La maldición de la dimensionalidad: es muy fácil llegar a una situación donde a pesar de contar con una cantidad masiva de datos, los histogramas multidimensionales son ralos. Para evitar esta situación se puede reducir el número de clases, pero esto aumenta el sesgo. En el caso de estimadores multidimensionales de densidad, una opción frecuente es el “kernel producto” con anchos de banda específicos por dimensión
Un ejemplo en dos dimensiones # white es una matriz de 12 variables medidas sobre 1599 vinos blancos # se puede obtener del UCI Machine Learning Repository > names(white) [1] "fixed.acidity" "volatile.acidity" "citric.acid" [4] "residual.sugar" "chlorides" "free.sulfur.dioxide" [7] "total.sulfur.dioxide" "density" "pH" [10] "sulphates" "alcohol" "quality" > plot(white$alcohol, white$fixed.acidity, col="red", pch=19, cex=.6, xlab="alcohol", ylab="acidez")
> library(MASS) > w1 <- kde2d(white$alcohol, white$fixed.acidity) > image(w1, col=heat.colors(7), xlab="alcohol", ylab="acidez")
> contour(w1, col=topo.colors(10), xlab="alcohol", ylab="acidez") > persp(w1, xlab="alcohol", ylab="acidez", theta=45, phi=15, r=15)
Un ejemplo en tres dimensiones > install.packages(“ks”) # ks es un paquete para trabajar con hasta 6 dimensiones > library(ks) > hpi_white <- Hpi(white[,c(2:4)]) > hpi_white [,1] [,2] [,3] [1,] 0.0019032436 -0.0006616945 0.0008355655 [2,] -0.0006616945 0.0013947287 0.0010294581 [3,] 0.0008355655 0.0010294581 0.0512672349 > hpi_white_diag <- Hpi.diag(white[,c(2:4)], pilot="samse") > hpi_white_diag [,1] [,2] [,3] [1,] 0.001659523 0.000000000 0.00000000 [2,] 0.000000000 0.001123971 0.00000000 [3,] 0.000000000 0.000000000 0.04499433 > install.packages("misc3d") > install.packages("rgl") > fhat_white <- kde(x=white[,c(2:4)], H=hpi_white) > plot(fhat_white) > fhat_white_diag <- kde(x=white[,c(2:4)], H=hpi_white_diag) > plot(fhat_white_diag)


