Download

1 / 15
150 likes | 288 Vues
Algoritmus k-means. Ivan Pirner 2007/2008. C íle mého snažení:. naprogramovat v MATLABu algoritmus k-means vymyslet funkce popisující vzdálenost ve 40dimenzionálním prostoru a použít je v algoritmu zjistit, která z funkcí se nejlépe hodí k použití časová náročnost

E N D
Algoritmus k-means Ivan Pirner 2007/2008
Cíle mého snažení: • naprogramovat v MATLABu algoritmus k-means • vymyslet funkce popisující vzdálenost ve 40dimenzionálním prostoru a použít je v algoritmu • zjistit, která z funkcí se nejlépe hodí k použití • časová náročnost • „vhodné“ rozdělení prvků
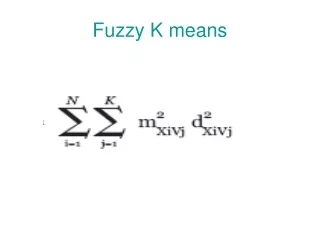
Co je k-means K-means, neboli k-středů, je metoda shlukové analýzy uvedená Johnem MacQueenem v roce 1967. Jejím úkolem je rozdělit množinu vektorů dimenze n do k podmnožin tak, aby byla nejmenší suma vzdáleností jednotlivých vektorů od středu příslušné podmnožiny. Následující skutečnost můžeme zapsat jako minimalizaci veličiny V.
Popis algoritmu Zadáme k a množinu všech vektorů. Zvolíme k výchozích středů podmnožin. Na základě funkce vzdálenosti každý z vektorů přiřadíme do shluku, jehož střed má nejmenší vzálenost. Vypočítáme u každé podmnožiny nový střed coby „těžiště“ množiny Návrat na krok 2. Zastavovací podmínka: Přiřazení žádného prvku se v předchozím kroku nezměnilo.
Ilustrace funkce 1. 2. 3. 4.
Problém volby středů Počáteční volbu můžeme provést libovolným způsobem, ale projeví se to pak na výsledku shlukování. Vyzkoušel jsem: k náhodných vektorů Vzít prvních k vektorů z množiny. Vzít náhodných k vektorů z množiny. Při další práci jsem využil možnosti číslo 2.
Vzdálenostní funkce • V původním algoritmu se jako míra vzdálenosti používá eukleidovská vzdálenost. To mě inspirovalo k několika úvahám: • Nestačil by kvadrát eukleidovské vzdálenosti? (méně počítání) • Jak nám výsledek ovlivní normy L1, L3, L4, max norma? • Neměli bychom jednotlivé složky vážit?
Statistika Zjistil jsem, že jednotlivé složky se zřejmě řídí normálním rozdělením.
Statistika Zjistil jsem směrodatné odchylky jednotlivých složek na reprezentativním vzorku vektorů. Ze zjištěných údajů vyplývá jednak to, že vážení má smysl, neboť první tři složky ovlivňují shlukování výrazně více než ostatní.
Vzdálenostní funkce seznam, popis Mějme vektory Eukleidovská norma Vážená eukleidovská norma Kvadrát eukleidovské normy Kvadrát vážené normy Max norma Max norma vážená L1 norma L3 norma L4 norma L1 vážená L3 vážená L4 vážená kvadráty
Závěr To, že se přiřazení u jednotlivých funkcní liší ještě nutně neznamená, že je to špatně. Každopádně můžeme usuzovat, že norma L1 je pro nás zajímavá z toho důvodu, že přiřazení se liší relativně málo, kdežto výpočetní nároky jsou mnohem menší.
Použitá literatura • obrázky z http://en.wikipedia.org/wiki/K-means • Mluvíme s počítačem česky • Josef Psutka, Jindřich Matoušek, Luděk Müller, Vlasta Radová