Download

1 / 12
140 likes | 274 Vues
Using Processor-Cache Affinity Information in Shared-Memory Multiprocessor Scheduling. Squillante & Lazowska, IEEE TPDS 4(2), February 1993. Affinity. On which processor should the next ready task run? Might be more efficient to choose one over another (but what does “efficient” mean)

E N D
Using Processor-Cache Affinity Information in Shared-Memory Multiprocessor Scheduling Squillante & Lazowska, IEEE TPDS 4(2), February 1993
Affinity • On which processor should the next ready task run? • Might be more efficient to choose one over another (but what does “efficient” mean) • Affinity captures this notion of efficiency • What is it? • M-w.com: “sympathy marked by community of interest” • Processor speed/type, resource availability • This paper considers affinity based on processor caches
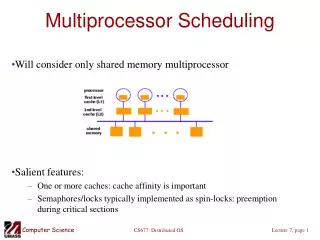
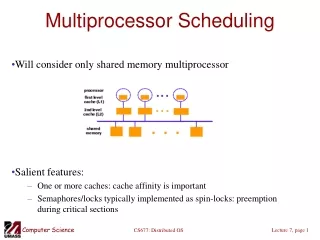
Cache affinity • What happens when a task starts on a processor? • A set of cache misses • Number of misses depends on amount of task working set in cache • Cache sizes trending upward => longer reload times when tasks are scheduled • Also performance hits due to bus contention, write-invalidations • How to reduce cache misses? • Run task on processor with most “affinity” • Why not just glue a task to a processor?
Analyzing cache affinity • This paper explores the solution space in order to gain understanding • Analytically model cache reload times • Determine how different scheduling policies perform with affinity information • Propose policies that make use of affinity information
Cache reload time • Is it significant? • Well, the paper got published, so…. • Intuitively, we believe this might be true, but need evidence • Experiments • Task execution time on cold cache vs. warm cache up to 69% worse • When bus contention and write-invalidations are considered, up to 99% worse • Rising cache sizes, cache-miss costs… • Why do cache sizes keep going up, anyway?
Modeling cache behavior • Terminology • Cache-reload transient: time delay due to initial burst of cache misses • Footprint: group of cache blocks in active use by a task • Closed queuing network model used to model system • M processors, N tasks, exponential random distributions • Assumes that cache footprints remain fairly static (in a single “footprint phase”)
Cache-reload transients • How much of task T’s footprint must be reloaded when a task is rescheduled on a processor P? • How much footprint got evicted since T last ran? • How many tasks ran on P since T last ran? • Expected cache-reload miss ratio for T • How much of T’s footprint must be reloaded when scheduled on P, as a function of the number of other tasks executed on P since T last ran • This is a function of two random variables and the footprint size • Ratio increases rapidly with number of intervening tasks • Effective scheduling intervention can only happen early if at all • Bus interference depends on scheduling policy
Scheduling policies • Abstract policies for evaluation of affinity • FCFS – ignore affinity, use first available CPU • Fixed – tasks permanently assigned to one CPU • Last processor – simple affinity, CPUs look for tasks they’ve run before • Minimum intervening – each CPU remembers number of intervening tasks since T, choose min • Limited minimum intervening – only consider a subset of CPUs • LMI-Routing – min( number of intervening tasks + number of tasks already assigned to that CPU )
Evaluation • Vary CRT for heavy/light loads, measure throughput • FCFS only good for light load, low CRT • FP not good for light loads, but as load/CRT increase, CRT dominates load-balancing penalties • LP very similar to FCFS on light loads, and almost as good as FP for heavy loads • Even simple affinity information is beneficial • Others • MI better than LP, but requires more state • LMI requires less state than MI, performance almost as good • Both MI/LMI ignore fairness, though • LMIR reduces variance in response time, improving fairness, throughput similar to MI
Bus traffic evaluation • Bus contention occurs when tasks are switched • So minimizing CRT is important • LP directly minimizes CRT • Not much better performance than FCFS at light loads • Under heavy load, very significant improvement over FCFS • Much higher CRT penalties at heavy load in FCFS
Practical policies • Queue-based • Use different task queues to represent affinity information • Priority-based • Use affinity information as a component in computing task-priority • Expensive at runtime – precompute a table of expected CRTs indexed by footprint size
Conclusions • As with everything else in CS, there are tradeoffs • Amount of affinity state vs. marginal effect on performance • “Greedy” schedulers (low CRT) give high throughput and low response times, but can be unfair & produce high variance in response time • Adaptive behavior is important • Footprint size, system load • A good example of an “understanding” paper