Download

1 / 63
630 likes | 756 Vues
Machine Learning in the Study of Protein Structure. Rui Kuang Columbia University Candidacy Exam Talk May, 2004. Table of contents. Introduction to protein structure and its prediction HMM, SVM and string kernels Protein ranking and structureal classification

E N D
Machine Learning in the Study of Protein Structure Rui Kuang Columbia University Candidacy Exam Talk May, 2004
Table of contents • Introduction to protein structure and its prediction • HMM, SVM and string kernels • Protein ranking and structureal classification • Protein secondary and higher order structure prediction • Protein domain segmentation • Future work
Part I Introduction to Protein Structure and Its Prediction
Why do we study protein structure • Protein– Derived from Greek word proteios meaning “of the first rank” in 1838 by Jöns J. Berzelius. • Crucial in all biological processes, such as Enzymatic catalysis, transport and storage, immune protection…… • Functions depend on structures --- structure can help us to understand function
Building blocks • Amino acid Hydrophobic: AVLIFPM Charged residues: DEKR Polar: STCNQHYW Special : G • Polypeptide chain Extend from its amino terminus to its carboxy terminus
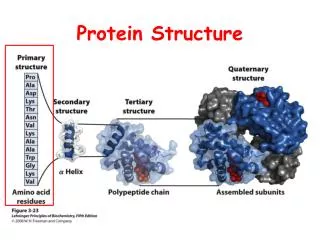
How to Describe Protein Structure • Primary: amino acid sequence • Secondary structure: alpha helix, beta sheet and loops • Tertiary: Phi-Psi angle • Quaternary: arrangement of several polypeptide chains
Secondary Structure : Alpha Helix hydrogen bonds between n and n+i (i=3,4,5)
Secondary Structure : Beta Sheet Antiparallel Beta Sheet Parallel Beta Sheet We can also have mix.
Secondary Structure : Loop Regions • Less conserved structure • Insertions and deletions are more often • Conformations are flexible
Tertiary Structure Phi – N - bond Psi – -C’ bond
Protein Domains • A polypeptide chain or a part of a polypeptide chain that can fold independently into a stable tertiary structure. • Built from different combinations of secondary structure elements and motifs
Three Main Classes of Domain Structures • During the evolution, the structural core tends to be conserved • Alpha domains : The core is build up exclusively from alpha helices • Beta domains : The core comprises anti-parallel beta sheets packed against each other • Alpha/Beta domains : a predominantly parallel Beta sheet surrounded by alpha helices
Determination of Protein Structures • X-ray crystallography The interaction of x-rays with electrons arranged in a crystal can produce electron-density map, which can be interpreted to an atomic model. Crystal is very hard to grow. • Nuclear magnetic resonance (NMR) Some atomic nuclei have a magnetic spin. Probed the molecule by radio frequency and get the distances between atoms. Only applicable to small molecules.
Structure space sparse 2000- 24,000 Function space Ill-defined ????? (20,000by GO) Sequence, Structure and Function Sequence space dense 1,000,000 Thanks to Michal Linial
From sequence to structure • Significant sequence similarity (>30%) usually suggests strong resemblance in structure • Remote homologous protein can also share similar structure • Structure space can be represented by discrete groups of folds • Yet the boundaries between these classes are often difficult to define
From structure to function • Structure similarity implies evolutionary relationship and functional similarity • However functions can be associated with different structures, different superfamilies can have the same fold and homologous superfamilies can evolve into distinct functions. • 66% of proteins having similar fold also have a similar function
Protein structure prediction in three areas • Comparative modeling:Where there is a clear sequence relationship between the target structure and one or more known structures. • Fold recognition ('threading'):No sequence homology with known structures. Find consistent folds (remote homology detection). • Ab initio structure prediction(‘de novo’):Deriving structures, approximate or otherwise, from sequence.
Comparative Modeling • Find homology proteins with known structure as templates • Align target with template sequences in terms of sequence/PSSM (most important) • Evolution makes sequence similarity weaker • No one-one corresponding due to Insertion/deletion • Full-atom refinement and loop modeling
Fold recognition • There is no known structure for the homologies of target sequence • Find remote homologies with consistent (similar) structures. • Does structural information help? • Do comparative modeling
De novo • No template available for use, predict the structure by folding simulation • Rosetta: • based on short segments independently sample distinct distributions of local conformations from known structure • Folding happens when orientations and conformations allow low free energy interactions. Optimized by a Monte Carlo search procedure
How to study protein structure with machine learning? • With above 24,000 known structures and functions in Protein Data Bank • Protein pairwise comparison • protein structural classification • Protein structure prediction • Protein segmentation……
Part II Hidden Markov Model, Support Vector Machine and String Kernels K( , ) Thanks to Nello Cristianini
Hidden Markov Models for Modeling Protein Alignment Maximum Likelihood Or Maximum a posteriori HMM Krogh, Brown, Mian, Sjolander and Haussler, 1993
Hidden Markov Models for Modeling Protein • Probability of sequence x through path q • Viterbi algorithm for finding the best path • Forward and backward for posterior decoding Krogh, Brown, Mian, Sjolander and Haussler, 1993
Hidden Markov Models for Modeling Protein Build HMM from sequences not aligned EM algorithm • Choose initial length and parameters • Iterate until the change of likelihood is small • Calculate expected number of times each transition or emission is used • Maximize the likelihood to get new parameters
String kernels for text classification • String subsequence kernel –SSK : • A recursive computation of SSK has the complexity of the computation O(n|s||t|). It is quadratic in terms of the length of input sequences. Not practical. Lodhi, Cristianini and etc... 2002
Part III Protein ranking and structural classification Where are my relatives?
Structural Classification Databases • SCOP, CATH, FSSP • Sequence pairwise comparison • Smith-waterman, BLAST, PSI-BLAST, rank-propagation, SAM-T98 • Discriminative classification • SVM pairwise, mismatch kernel, EMOTIF kernel, I-Site kernel, semi-supervised kernel
SCOP Fold Superfamily Negative Test Set Negative Training Set Family Positive Test Set Positive Training Set SCOP Family : Sequence identity > 30% or functions and structures are very similar Superfamily : low sequence similarity but functional features suggest probable common evolutionary origin Common fold : same major secondary structures in same arrangement with the same topological connections
CATH • Class • Architecture • Topology • Homologous • Sequence family
Local alignment: Smith-Waterman algorithm • For two string x and y, a local alignment with gaps is: • The score is: • Smith-Waterman score: Thanks to Jean Philippe
BLAST: a heuristic algorithm for matching DNA/Protein sequences • Idea: True match are likely to contain a short stretch of identity • A list of ‘neighborhood words” of the query sequence • Search database with the list, whenever there is a match do a ‘hit extension’, stopping at the maximum scoring extension Altschul, Madden, Schaffer, Zhang etc., 1997
PSI-BLAST: Position-specific Iterated BLAST • Only extend those double hit within a certain range. • A gapped alignment uses dynamic programming to extend a central pair of aligned residues in both directions. • PSI-BLAST can takes PSSM as input to search database Altschul, Madden, Schaffer, Zhang etc., 1997
Local and Global Consistency • Affinity matrix • D is a diagonal matrix • Iterate • F* is the limit of seuqnce {F(t)} Zhou, Bousquet, Lal, Weston, and Scholkopf, 2003
Rank propagation • Protein similarity network: • Graph nodes: protein sequences in the database • Directed edges: a exponential function of the PSI-BLAST e-value (destination node as query) • Activation value at each node: the similarity to the query sequnce • Exploit the structure of the protein similarity network Weston, Elisseeff, Zhou, Leslie and Noble, 2004
SAM-T98 • The first iteration: query sequence to search NR database using WU-BLASTP and build alignment for the found homologs • 2nd-4th iterations: take the alignment from the previous iterations to find more homologs with WU-BLASTP and update the alignment with the new homologs found. • Build a HMM from the final alignment. The HMM of query sequence is used to search database, or we can use query sequence to search against HMM database Karplus, Barrett and Hughey, 1999
Use discriminative methods, such as SVM to utilize negative data as well as positive data…
Fisher Kernel • A HMM (or more than one) is built for each family • Derive kernel function from the fisher scores of each sequence given a HMM H1: Jaakkola, Diekhans and Haussler, 2000
SVM-pairwise • Represent sequence P as a vector of pairwise similarity score with all training sequences • The similarity score could be a Smith-Waterman score or PSI-BLAST evalue. Liao and Noble, 2002
Mismatch Kernel AKQ KQD QDY DYY YYY… Implementation with suffix tree achieves linear time complexity O(||mkm+1(|x|+|y|)) AKQDYYYYE… AKQ … CKQ AKY … DKQ AAQ ( 0 , … , 1 , … , 1 , … , 1 , … , 1 , … , 0 ) AAQAKQDKQEKQ AKQ Leslie, Eskin, Cohen, Weston and Noble, 2002
EMOTIF Database • A motif database of protein families • Substitution groups from separation score Nevill-manning, Wu and Brutlag, 1998
EMOTIF Database (continued) • All possible motifs are enumerated from sequence alignment Nevill-manning, Wu and Brutlag, 1998
EMOTIF Kernel • EMOTIF TRIE built from eBLOCKS • EMOTIF feature vector: where is the number of occurrences of the motif m in x Ben-Hur and Brutlag, 2003
I-SITE Motif Library • Sequence segments (3-15 amino acids long) are clustered via Kmeans • Within each cluster structure similarity is calculated in terms of dme and mda • Only those clusters with good dme and mda are refined and considered motifs afterwords
I-SITE Kernel • Similar to EMOTIF kernel I-SITE kernel encodes protein sequences as a vector of the confidence level against structural motifs in the library
Cluster kernels • Profile Kernels Implicitly average the feature vectors for sequences in the PSI-BLAST neighborhood of input sequence (dependent on the size of the neighborhood and total length of unlabeled sequences) • Bagged Kernels Run bagged k-means to estimate p(x,y), the empirical probability that x and y are in the same cluster. The new kernel is the product of p(x,y) and base kernel K(x,y) Weston, Leslie, Zhou, Elisseeff and Noble, 2003
Part IV Protein secondary and higher order structure prediction Can we really do that?
PHD: Profile network from HeiDelberg B. Rost and C. Sander, 1993
PSIPRED D. T. Jones, 1999