Download

1 / 100
1k likes | 1.12k Vues
XML und Datenbanken. Peter Brezany Institut für Softwarewissenschaften Universität Wien. XML, die eXtensible Markup Language, ist heute in aller Munde. Man verspricht sich von ihr: branchenübergreifende Standardisierungen, weltweiten problemlosen Datenaustausch, portierbare Anwendungen, usw.

E N D
XML und Datenbanken Peter Brezany Institut für Softwarewissenschaften Universität Wien
XML, die eXtensible Markup Language, ist heute in aller Munde. Man verspricht sich von ihr: branchenübergreifende Standardisierungen, weltweiten problemlosen Datenaustausch, portierbare Anwendungen, usw. Java: „write once, run everywhere“. XML : „write once, read everywhere“ – eine ideale Eigenschaft für das WWW. XML ist eine Metasprache – eine Sprache zur Definition von Sprachen, und diese mit XML definierten Vokabulare und Sprachen sind es, auf denen immer mehr Internetanwendungen aufbauen. XML ist auch nützlich für Datenaustausch zwischen Datenbanken und Andwendungen uns zwischen mehreren Paaren von Anwendungen. Motivation
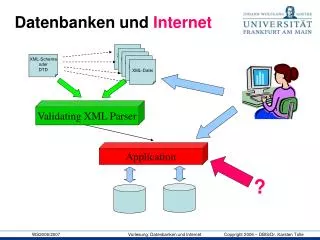
Motivation – Web Datenbanken Ein Web Datenbanksystem ist ein DB Sytem, das persistente Daten über das Web liefert. User User Softw. Web Server DB DBMS Applic. Softw. Other Applications • There are several ways that XML can • be used within a Web database system: • flat file DB that stores data as XML • documents. • data stored in a traditional DB and • formatted as XML when retrieved. • specialized XML DBMS OS Operating System Hardware HW
Erscheinung des World Wide Webs (WWW) in der Mitte der 1990-er Jahren resultierte in sehr große Anforde-rungen an Daten-, Informations- und Wissensmanagement. Neue Werkzeuge sind notwendig. Neue strategisch wichtige Technologien sind erschienen: Extensible Markup Language (XML), semistrukturierte Datenbanken und semantisches Web. Diese Technologien haben enormen Einfluß auf e-business (electronic business). Einführung
XML ist am 10. Februar 1998 vom W3C standardisiert worden. Es ist eine Metasprache. Um eine Sprache zu definieren, muß man ihre Grammatik und das Vokabular festlegen. Das tut man in der Dokumenttyp Definition (DTD). Dokumente gehören zum selben Dokumenttyp, wenn sie der gleichen DTD folgen. Z. B. HTML-Dokumente folgen der selben Grammatik (welche Tags können wie geschachtelt werden...) und können das selbe Vokabular (sprich die Tags) benutzen. Das bedeutet, daß alle HTML-Dokumente dem selben Dokumenttyp angehören, nämlich HTML. Jeder kann sich eine DTD bauen, und dann XML-Dokumente schreiben die dieser DTD folgen. Ein interpretierendes Programm (zB ein Browser) kann dann zwar sagen: Ja, dieses XML-Dokument ist gültig in Bezug auf diese DTD (d.h. das Dokument befolgt die Regeln der DTD, und gehört damit zum entsprechenden Dokumenttyp). XML
Es kann aber NICHT wissen, was es mit diesem oder jenem Element machen soll. Das bedeutet, daß sich jeder der eine DTD verfaßt auch darum kümmern muß, daß es Programme gibt, die mit den Dokumenten dieses Typs etwas anfangen können! Nun muß natürlich nicht jeder, der ein XML-Dokument schreibt, ein eigenes Programm zur Interpretation des Dokuments entwickeln. Zumindest wenn das XML in einem Browser angezeigt werden soll, gibt es dafür XSL (eXtensible Stylesheet Language). XML (2)
XML (3) Ein kleines Beispiel für ein XML-Dokument (ohne DTD): <?xml version="1.0"?><BUCH><TITEL> Der Herr der Ringe </TITEL><AUTOR> J.R.R. Tolkien </AUTOR></BUCH> Das ähnelt HTML - XML ist eine Vereinfachung von SGML (Standardized Generalized Markup Language), und HTML mit SGML definiert wurde.
XML eine Metasprache. Das bedeutet, daß sich für jeden beliebigen Zweck Dokumenttypen schaffen lassen. Z. B. könnten sich Meteorologen einen Dokumenttyp mit den Elementen <Luftdruck>, <Temperatur> usw. schaffen, und Ärzte einen Dokumenttyp mit den Elementen <PatientName> und <Sterbedatum>. Das heißt, daß XML in allen Bereichen als Datenaustauschformat zum Einsatz kommen kann. Ein weiterer Vorteil ist in diesem Falle, daß XML von Computern und Menschen lesbar ist. Im Gegensatz zu HTML, ist bei XML die Struktur bzw Grammatik (DTD), der Inhalt (das XML Dokument) und die Darstellung (z.B. XSL) getrennt. Das ermöglicht die unterschiedliche Darstellung des gleichen Inhalts (zB. als Text, HTML, Sprachausgabe, Braille-Schrift...) ohne die Änderung des XML-Dokuments. Bei Webseiten könnte man sich etwa vorstellen, XML-codierte Daten und ein kleines Programm das diese Daten interpretiert (bzw. ein XSL-Dokument) an den Client zu schicken. Warum XML?
Es gibt zwei Kriterien nach denen man XML-Dokumente bewerten kann: Wohlgeformtheit (wellformedness): Gemeint ist, daß ein wohlgeformtes XML-Dokument die Regeln des Standards befolgt, also beispielsweise < und > richtig benutzt und die Elemente korrekt geschachtelt sind. Folgendes ist also nicht wohlgeformt: <fett>Das ist <kursiv> völlig </fett> falsch! </kursiv> Gültigkeit (validity): Ein wohlgeformtes XML-Dokument wird als gültig oder valide bezeichnet, wenn es den Regeln einer DTD folgt. Ein Dokument kann also wohlgeformt und nicht gültig sein, aber niemals gültig und nicht wohlgeformt. Außerdem ergibt sich, daß ein Dokument immer nur bezüglich einer DTD, und nicht von sich aus gültig sein kann. XML
Kommentar <!--Kommentar--> Ein XML Dokument besteht aus 2 Teilen: dem Prolog (Er kann aus der Versionsangabe und DTD bestehen; kann aber auch leer sein.) und den eigentlichen Elementen. Die Versionsangabe <?xml version="1.0" encoding="UTF-8"?> Die DTD dient ja quasi als Schablone nach deren Muster man dann die XML-Dokumente baut. XML - Grundlegendes
Es gibt zwei Möglichkeiten eine DTD in ein XML-Dokument einzubinden. Bei der internen DTD befinden sich DTD und XML-Dokument in einer Datei. <?xml version="1.0"?> <!DOCTYPE foo [ <!ELEMENT myElement (#PCDATA)> ]> Nach dem [ folgt hier schon die Definition eines Elementes. Bei einer externen DTD befinden sich DTD und XML-Dokument in getrennten Dateien, was bei großen Dokumenten durchaus praktisch ist. Das XML-Dokument enthält dann nur einen Verweis auf die DTD. <?xml version="1.0"><!DOCTYPE foo SYSTEM "foo.dtd"> Ein XML-Parser wird in einer Datei namens foo.dtd nach einer DTD suchen. XML Es wirdein Element name de- finiert, der nur Text (parsed character data) – #PCDATA enthalten darf.
XML Beide Formen der DTD können auch gemischt vorkommen: <?xml version="1.0"?><!DOCTYPE foo SYSTEM "foo.dtd" [ <!ELEMENT myELEMENT (#PCDATA)>]> Der Parser wird an dieser Stelle beide DTD's zusammenfassen, und als eine behandeln. Zusammenfasung: Der Prolog besteht aus der XML-Versionsangabe und einem Verweis auf die DTD oder der DTD selbst. Beide Elemente sind optional.
Wurzelelement Grundsätzlich gilt die Regel, daß der Name, der in der Dokumenttypdeklaration auftaucht, also in unserem Fall foo, der des Wurzelelementes sein muß. Das Wurzelelement ist ein Tag, der alle anderen Tags enthält (mehr dazu im nächsten Teil).
Elemente Elemente sind die einfachsten und häufigsten Bestandteile von XML. Jedes XML-Dokument hat EIN Wurzelelement, das alle anderen Elemente enthält. <?xml version="1.0"?><buch>Der Herr der Ringe</buch><autor><vorname>John Ronald Reuel</vorname><nachname>Tolkien</nachname></autor> Dieses Beispiel wäre also KEIN wohlgeformtes XML-Dokument, da es zwei Wurzelelemente (oder, je nach Betrachtungsweise, kein Wurzelelement) besitzt, nämlich <buch> und <autor>.
Was ist ein XML Dokument? Ein grundlegendes XML Dokument ist einfach ein XML Element, das verschachtelte XML Elemente enthalten kann. Zum Beispiel ist das untenstehende XML Element "buecher" ein gültiges XML Dokument. <buecher> <buch isbn="0345374827"> <titel>The Great Shark Hunt</titel> <autor>Hunter S. Thompson</autor> </buch></buecher>
Leere und nichtleere Elemententypen Grundsätzlich gibt es zwei verschiedene Elemente: nichtleere und leere. Für die leeren Elemente gibt es zwei Schreibweisen, die völlig gleichwertig sind. <nichtLeer>Inhalt</nichtLeer><leeresElement></leeresElement><leeresElement2/>
Definition eines Elements in der DTD NichtleereElemente unterschiedliche Inhalte haben können: Text, weitere Elemente oder beides. <!ELEMENT name (#PCDATA)> definiert ein Element name, das nur Text (parsed character data) enthalten darf.
Definition eines Elements in der DTD (2) <!ELEMENT titel (#PCDATA)><!ELEMENT autor (#PCDATA)><!ELEMENT buch (titel, autor)> Hier werden zwei Elemente titel und autor definiert (beide Text). Das Element buch wird so definiert, daß es in den XML-Dokumenten dann diese beiden Elemente in dieser Reihenfolge genau einmal enthalten muss. Man kann also Anzahl und Reihenfolge der Child-Elemente bestimmen.
Definition eines Elements in der DTD (3) Der Operator „|“ (Bedeutung: oder). <!ELEMENT anschrift (firma | name), strasse, ort, email><!ELEMENT firma (#PCDATA)><!ELEMENT name (#PCDATA)><!ELEMENT strasse (#PCDATA)><!ELEMENT ort (#PCDATA)><!ELEMENT email (#PCDATA)> Hier können wir zwischen einem Firmennamen und dem Namen einer Person wählen, müssen dann aber Straße, Ort und email Adresse angeben.
Definition eines Elements in der DTD (3) Es gibt Menschen mit mehreren email Adressen, und auch welche ohne . Als eine Lösung gibt es folgende Operatoren: ?Das Objekt ist optional, kann also null oder einmal auftreten. *Das Objekt ist optional, kann aber beliebig oft auftreten. +Das Objekt muß mindestens einmal auftreten. Unser Beispiel sollte also besser so aussehen: <!ELEMENT anschrift (firma | name), strasse, ort, email*> Die Definition der restlichen Elemente haben wir uns hier gespart, sie verändern sich ja nicht.
Definition eines Elements in der DTD (4) • Ein Elementtyp ist jetzt noch ungeklärt: gemischter Inhalt (mixed • content). Gemischter Inhalt bedeutet, daß das Element Text und • weitere Elemente enthalten soll. Für diesen Fall gelten einige • Besonderheiten bei der Definition: • #PCDATA muß immer an erster Stelle stehen • alle Inhalte müßen mit | verknüpft werden • die gesamte Gruppe muß optional sein, und beliebig oft vorkommen • dürfe (also der *-Operator) • Im Klartext bedeutet das, daß man weder die Anzahl noch die • Reihenfolge der Inhalte eines Elements mit mixed content • bestimmen kann. Daher ist nach folgender DTD • <!ELEMENT zitat (#PCDATA)> • <!ELEMENT text (#PCDATA | zitat)*> • folgendes XML-Dokument gültig (valid):
Definition eines Elements in der DTD (5) <text>Heinz Rühmann sagte:<zitat> Ein Pessimist ist ein Mensch, der sich über schlechteErfahrungen freut, weil sie ihm Recht geben.</zitat>Aber das ist nur eins von vielen Zitaten über Pessimisten.</text>
Definition eines Elements in der DTD (6) Wie kann man leere Elemente definieren? <!ELEMENT leer EMPTY> Analog zu EMPTY gibt es auch noch das Schlüsselwort ANY. Das bedeutet, daß das entsprechende Element alle in der DTD definierten Elemente und PCDATA in jeder Reihenfolge und Anzahl enthalten kann. Also können wir unser Zitat-Text-Beispiel noch einmal vereinfachen: <!ELEMENT zitat (#PCDATA)><!ELEMENT text ANY>
DTD und das entsprechende Dokument Stellen wir uns vor, wir wollen Bücher in XML-Dokumenten fassen. Zu jedem Buch soll der Titel, und der Inhalt gespeichert werden. Der Inhalt gliedert sich in Kapitel, und diese wiederum in Überschriften, Text und Zitate. Die Anzahl und Reihenfolge von Texten und Zitaten soll beliebig sein. <!ELEMENT buch (titel, kapitel+)> <!--ein Titel, min. ein Kapitel--><!ELEMENT titel (#PCDATA)><!ELEMENT kapitel (headline, (text | zitat)*)><!--zuerst immer die Überschrift, dann Text/Zitate in beliebiger Folge--> <!ELEMENT headline (#PCDATA)><!ELEMENT text (#PCDATA)><!ELEMENT zitat (#PCDATA)> Die nächste Folie zeigt ein XML-Dokument von diesem Typ:
DTD und das entsprechende Dokument (2) <?xml version="1.0"?><!DOCTYPE buch SYSTEM "buch.dtd"><buch><titel>Mein erstes Buch</titel> <kapitel> <headline>Einleitung</headline><text>Einleitungen sind immer ein sehr schwieriger Teil. Und damitjetzt auch noch ein Zitat in dieses Beispiel kommt:</text><zitat>Optimisten glauben, daß wir in der besten aller Welten leben.Pessimisten befürchten, daß das stimmt.</zitat> <text>Nun kann man hier noch 'ne Menge Text schreiben, muß man aber nicht. Auch das Zitieren wäre nach Lust und Laune möglich. Nur Überschriften dürfen nicht mehr kommen.</text></kapitel> </buch>
Attribute Attribute sind zusätzliche Informationen zu Elementen. Sie können beispielsweise so aussehen: <img src="meinBild.jpg" alt="bild" heigth="12" width="150"/><person sex="m"><name>der Weihnachtsmann</name></person> Das <img>-Element könnte genausogut so aussehen: <img><src>meinBild</src><alt>"bild"</alt><height>12</height><width>150</width></img>
Attribute (2) Wie kann man nun Attribute in der DTD definieren? <!ATTLIST img src CDATA #REQUIREDalt CDATA #REQUIREDheight CDATA #IMPLIEDwidth CDATA #IMPLIED> ATTLIST img sagt nur aus, daß es sich im Folgenden um eine Attributliste zum Element img handelt. Danach werden die einzelnen Attribute aufgelistet, und zwar zuerst der Name des Attributes, dann der Typ (in diesem Fall CDATA, also Zeichendaten). Zum Schluss folgt noch ein Modifikator, der angibt, ob das Attribut erforderlich ist (#REQUIRED), oder optional (#IMPLIED). Es gibt noch eine dritte Möglichkeit für den Modifikator: #FIXED.
Attribute (3) <!ATTLIST steuern comment CDATA #FIXED "zu hoch"> Das bedeutet also, daß zum Element <steuern> ein Attribut comment definiert wird, das immer den Wert "zu hoch" hat. <steuern comment="zu hoch"/> <steuern/> <!--entspricht der ersten Zeile--> <steuern comment="zu niedrig"> <!--Fehler--> Wenn man keinen Modifikator angibt, muß man eine Vorgabe für den Attributwert machen. <!ATTLIST fenster material "glas"> Dies würde also bedeuten, daß wenn man folgende Zeile schreibt, das Attribut material den Attributwert glas hat:<fenster/> <fenster material="kunststoff"/> <!--das Attribut wird anders belegt-->
Attributtypen CDATA beliebige Zeichenketten ID Die ID muß im gesamten Dokument einmalig sein, damit jede ID eindeutig ein Element identifiziert. Deshalb kann eine ID nur #REQUIRED oder #IMPLIED sein. IDREF IDREF muß eine Zeichenkette sein, die irgendwo im Dokument eine ID ist, also quasi auf diese verweisen. Mit ID und IDREF können also zwei unterschiedliche Elemente einander zugeordnet werden. IDREFS Eine Liste von Referenzen. Als Trennzeichen fungiert das Leerzeichen. ENTITY Der Attributwert muß mit dem Namen einer externen, ungeparsten Entity übereinstimmen. ENTITIES Eine Liste. Als Trennzeichen fungiert das Leerzeichen.
Attributtypen (2) • NMTOKEN (ein einzelnes Token) Entpricht CDATA mit ein • paar Einschränkungen: • darf nur mit A-Z, a-z, 0-9 oder _ anfangen, danach sind • auch ".", "-", "," erlaubt • es dürfen keine Leerzeichen oder Markup enthalten sein • darf nicht mit xml anfangen, egal ob groß oder klein. • NMTOKENS eine Liste von Token (mit Trennzeichen Leerzeichen). • NOTATION Der Wert eines Attributs vom Typ NOTATION, ist • der Name einer Notation. Was Notationen sind, • dazu später mehr. • NOTATIONS eine Liste von notationen.
Attributtypen (3) Eigentlich gibt es noch einen elften Attributtyp, nämlich den Aufzählungstyp. Dieser hat allerdings kein Schlüsselwort (wie CDATA), und kommt mit einer anderen Syntax daher: <!ATTLIST person sex (m | w | transsexuell) #REQUIRED> Hier kann das Attribut sex nur die Werte m, w oder transsexuell annehmen.
Attribute - abschließendes Beispiel <!ELEMENT bibliothek (buch)+><!ELEMENT buch (titel, autor, inhalt)><!ATTLIST buch genre (Sachbuch | Roman | Fantasy) "Sachbuch" verlag CDATA #FIXED "meinVerlag" isbn ID #REQUIRED neuauflageVon IDREF "null"><!ELEMENT titel (#PCDATA)><!ELEMENT autor (#PCDATA)><!ATTLIST autor geschlecht (m | w) #REQUIRED><!ELEMENT inhalt (#PCDATA)>
Attribute - abschließendes Beispiel Jedem Buch wird hier ein eindeutiger Schlüssel zugewiesen, nämlich seine ISBN. Dabei wird angenommen, daß in dieser Bibliothek jeweils nur EIN Exemplar eines Buches steht, und deshalb ISBN's nicht doppelt vorkommen. Das Attribut neuauflageVon kann sich dann eindeutig auf eine ISBN beziehen. Sollte dieses Attribut nicht gesetzt werden, beispielsweise weil es die Erstauflage ist, ist der Defaultwert null. null hat keine besondere Bedeutung (bzw. ist kein von XML reserviertes Wort), und muß dann von der Anwendung entsprechend interpretiert werden.
Eine Instanz unserer DTD <?xml version="1.0"?><!DOCTYPE bibliothek SYSTEM "bibliothek.dtd"><bibliothek><buch genre="Fantasy" isbn="3-608-95855-X"><titel>Der Herr der Ringe</titel><autor geschlecht="m">J.R.R. Tolkien</autor><inhalt>viel Text</inhalt></buch><buch isbn="3-8273-1330-9"><titel>XML in der Praxis</titel><autor geschlecht="m">Behme, Mintert</autor><inhalt>Inhalt</inhalt></buch><buch genre="Fantasy" isbn="5559110815" neuauflageVon="3-608-95855-X"><titel>Der Herr der Ringe</titel><autor geschlecht="m">J.R.R. Tolkien</autor><inhalt>vielText</inhalt></buch></bibliothek>
Entities Entities sind im Prinzip Ersetzungen, das heißt, jedes Entity hat einen Namen und einen Ersetzungstext. Ersetzungstext ist vielleicht nicht ganz korrekt, denn Entities können auch Bilder, Sounds etc. sein. Wenn nun irgendwo der Name des Entities (die Entityreferenz) auftaucht, setzt der Parser dort den Ersetzungstext ein. <!ENTITY fhtw "Fachhochschule fuer Technik und Wirtschaft Berlin"> Referenziert wird dieses Entity mit&fhtw; Dort wo die Entityreferenz auftaucht, wird der Ersetzungstext eingesetzt. <student hochschuhle="&fhtw;"><uni>&fhtw;</uni></student>
Entities sind im Prinzip Ersetzungen, das heißt, jedes Entity hat einen Namen und einen Ersetzungsobjekt. Entities können Texte, Bilder, Sounds etc. sein. Wenn nun irgendwo der Name des Entities (die Entityreferenz) auftaucht, setzt der Parser dort den Ersetzungsobjekt ein. Es gibt drei verschiedene Kriterien nach denen Entities gegliedert werden: allgemeine vs ParameterentitiesAllgemeine Entities bzw. deren Entityreferenzen können nur im XML-Dokument auftauchen. Im Gegensatz dazu gibt es Parameterentities nur in der DTD. Beide Entities werden natürlich wie gewohnt in der DTD deklariert. geparste vs ungeparste EntitiesReferenzen auf geparste Entities werden vom Parser zuerst ersetzt, und danach analysiert, das heißt auf Markup durchsucht. Ungeparste Entities werden vom Parser nicht analysiert. Ungeparste Entities müssen an eine externe Anwendung weitergegeben werden, um verarbeitet zu werden. externe vs interne EntitiesDer Inhalt (Ersetzungstext) eines externes Entity ist nur durch Zugriff auf eine andere Datei zu bestimmen. Diese Datei kann zum Beispiel ein Bild, ein Sound oder auch eine XML-Datei sein. Bei einem internen Entity wird der Inhalt bei der Deklaration bestimmt. Entities – Mehr Details
<!ENTITY fhtw "Fachhochschule fuer Technik und Wirtschaft Berlin"> Bei der Deklaration folgt nach dem Schlüsselwort ENTITY der Name des Entities und dann der Ersetzungstext. &fhtw; Die Referenz besteht also aus dem &, gefolgt vom Namen des Entities. Abgeschlossen wird das ganze durch das ;. Dort wo die Entityreferenz auftaucht, wird der Ersetzungstext eingesetzt. Die Entityreferenz darf an allen Stellen stehen, in denen im XML-Dokument Text erlaubt ist: <student hochschuhle="&fhtw;"><uni>&fhtw;</uni></student> Internes, geparstes, allgemeines Entitiy
<!ENTITY % headings "H1 | H2 | H3 | H4 | H5 | H6"> Der einzige Unterschied zur Deklaration eines allgemeinen Entities besteht in dem %. Auch die Entityreferenz verwendet das %: %headings; Die Verwendung erfolgt ähnlich wie beim allgemeinen Entity: <?xml version="1.0"><!DOCTYPE body [<!ENTITY % headings "H1|H2|H3|H4|H5|H6"><!ENTITY % list "UL|OL|DIR|MENU"><!ELEMENT BODY (%headings;|P|%list;|PRE|HR|IMG)*>]><BODY><H1>Überschrift</H1></BODY> Internes, geparstes,Parameterentity
<!ENTITY kapitel1 SYSTEM "www.frag-mich-mal.de/kap1.xml"> Nach dem Namen des Entities folgt hier das Schlüsselwort SYSTEM und danach die Angabe wo das externe Entity gefunden werden kann &kapitel1; Externes, geparstes, allgemeines Entity
<!ENTITY % buch SYSTEM "www.frag-mich-nicht.de/buch.dtd"> Die Entityreferenz ist: %buch; Externes, geparstes Parameterentity
<!ENTITY bild SYSTEM "/bilder/foto.jpg" NDATA jpeg> NDATA -dies sagt dem Parser eigentlich nur, daß es sich nicht uminterpretierbare Daten (im Sinne von XML) handelt. Das abschließende jpeg ist ein Name (der natürlich frei vergeben werden kann), der mit dem Namen einer Notation übereinstimmen muß (dazu kommen wir gleich). Auch die Entityreferenz wird anders verwendet als bisher. Sie darf nämlich nur als Attributwert eines Attributes vom Typ Entity auftreten. <!ENTITY passfoto SYSTEM "/bilder/foto.jpg" NDATA jpeg><!ELEMENT person EMPTY><!ATTLIST person bild ENTITY #REQUIRED> Im XML-Dokument könnte dann stehen: <person bild="passfoto"/> Der Parser wird an dieser Stelle merken, daß bild vom Typ ENTITY ist und nach einem Entity namens passfoto suchen. In der Deklaration steht nun wo der Parser das entsprechende Bild finden kann. Was macht denn der Parser nun mit diesem Entity macht? An dieser Stelle kommen die Notationen ins Spiel. Externes, ungeparstes, allgemeines Entity
Notationen Eine Notation verbindet einen Namen mit einer Anwendung. Beispielsweise ließe sich der Name jpeg mit der Anwendung bildbetrachter.exe verbinden. <!NOTATION jpeg SYSTEM "http://www.bilder.de/bildbetrachter.exe"> Der Parser würde also alle externen Entities mit dem Namen jpeg an die Anwendung bildbetrachter.exe übergeben. Um das alles zusammen zu fassen, auf der nächsten Folie ein kleines Beispielzu Entities und Notationen:
Notationen (2) <?xml version="1.0"?><!DOCTYPE person [<!ENTITY passfoto SYSTEM "/bilder/foto.jpg" NDATA jpeg><!NOTATION jpeg SYSTEM "http://www.bilder.de/bildbetrachter.exe"><!ELEMENT person (name, vorname)><!ATTLIST person bild ENTITY #REQUIRED><!ELEMENT name (#PCDATA)><!ELEMENT vorname (#PCDATA)>]><person bild="passfoto"><name>Grube</name><vorname>Claire</vorname></person> Bemerkung: NDATA = non-parsed data
XML 1.0 sieht vor, dass eine DTD extern sein kann, und ermöglicht auf diese Weise, dass verschiedene Dokumente dasselbe Vokabular benutzen. Es war jedoch nicht vorgesehen, verschiedene Vokabulare zu kombinieren. Wenn z.B. für Bücher ein Standardvokabular (BS) definiert ist, kann BS benutzt werden, um es in die Angebote eines Buchversands einzubinden, zusammen mit spezifischen Daten des Vehandels, die Wiederum mit einem anderen Vokabular beschrieben sind. Auch im XML-Umfeld selbst kommen Standardvokabulare vor, um z.B. Transformationsanweisungen in ein Dokument einzubinden. Nun kann man mit einem Dokument, das verschiedene Vokabulare enthält, nur schwer umgehen, wenn sich die einzelnen Namen von Elementen und Attributen nicht den jeweiligen Vokabularen zuordnen lassen. Insbesondere kann es vorkommen, dass 2 Vokabulare dieselben Namen (doch mit verschiedener Bedeutung) enthalten. Namensräume
Namensräume - Beispiele Eine häufige Anwendung von Namensräumen ist die Nutzung von HTML-Tags in XML. <?xml version=“1.0“?> <Hallo xmlns:html=“http://www.w3.org/TR/REC-html40“> <Ausgabe>XML</Ausgabe> <html:h2>Eine Überschrift mit HTML </html:h2> </Hallo> Durch das xmlns:html= ... Attribut wird im Wurzelelement der Namensraum html definiert (es wird dem Browser mitgeteilt, dass HTML-Tags innerhalb des XML-Dokuments verwendet werden). Durch die URI “http://www.w3.org/TR/REC-html40“ wird die genaue Adresse einer HTML4Spezifikation angegeben, damit der Raum html genauestens definiert werden kann.
Namensräume – Beispiele (2) Angenommen, die beiden folgenden Elementgruppen kämen aus zwei verschie- denen DTDs, nämlich books und owners: <BOOK> <TITLE>Tauben im Gras</TITLE> <AUTHOR>Wolfgang Koeppen</AUTHOR> </BOOK> <OWNER> <NAME>Hans Meier</NAME> <TITLE>Dr.</TITLE> </OWNER> Das Problem wird deutlich: beide Elemente haben eine semantisch logische Bedeutung, sind aber quasi Homonyme. Der erste Tag bezieht sich auf den Buchtitel, der zweite auf den akademischen Titel des Besitzers. Lösung (nächste Folie):
Namensräume – Beispiele (3) . . . xmlns:books ="http://www.jcpohl.de/tr/books"> xmlns:owners ="http://www.jcpohl.de/tr/owners"> xmlns=default-name-space . . . <books:BOOK> <books:TITLE>Tauben im Gras</books:TITLE> <books:AUTHOR>Wolfgang Koeppen</books:AUTHOR> </books:BOOK> <owners:OWNER> <owners:NAME>Hans Meier</owners:NAME> <owners:TITLE>Dr.</owners:TITLE> </owners:OWNER> default-name-space – definiert als Vorbelegung und gilt dann für alle nicht mit einem Prefix versehenen Elementdaten
XML-Schema Der W3C-Standard XML-Schema ist eine XML-Sprache zur Definition von XML-Vokabularen.Als Nachfolger der bekannten Document Type Definitions (DTD) markiert XML Schema den entscheidenden Wendepunkt von der bisherigen dokumentenorientierten Sichtweise hin zu einer datenorientierten . Technisch gesehen erweitern sich durch XML Schema die Ausdrucksmöglich- keiten bei der Formulierung neuer XML-Vokabulare entscheidend. Einerseits hinsichtlich inhaltlicher Merkmale wie Datentypen; andererseits auch in Richtung struktureller Merkmale. So halten bekannte Konzepte aus den Programmier- und Datenbanksprachen Einzug.Inzwischen haben namhafte Firmen und Initiativen ihre Unterstützung des am 2. Mai 2001 durch das W3C verabschiedeten Standards erklärt; zu Lasten anfänglich konkurrieren- der proprietärer Vorschläge.
Es gibt grundsätzlich 2 Möglichkeiten, XML-Dokumente zu parsen, d.h. von einem Programm aus die gespeicherten XML-Daten in für das Programm sinnvolle Strukturen umzuwandeln: Tree based parser, DOM – Sie lesen das komplette XML-Dokument ein, validieren es und bauen daraus eine baumartige Struktur (z.B. DOM) zusammen. Dieser Baum kann dann vom Programm benutzt werden. Umgekehrt gibt es auch XML-Schreiber, welche eine DOM-Baumstruktur in ein XML-Dokument umwandeln. DOM (Document Object Model) ist ein Objektmodell, es beschreibt die in einem Dokument einer bestimmten XML-Anwendung enthaltenen Elemente als Objekte, für die Verarbeitung mit einer objekt-orientierten Programmiersprache wie z.B. Java. DOM liefert eine komplette Baumstruktur aller Objekte eines XML-Dokuments und eignet sich daher nicht für extrem große XML-Files. Beispiel – nächste Folie Parser