Download

1 / 25
260 likes | 435 Vues
Parallel Programming & Stuff Jud Leonard. February 28, 2008. SiCortex Systems. Outline. Parallel problems Simulation Models Imaging Monte Carlo methods Embarrassing Parallelism Software issues due to parallelism Communication Synchronization Simultaneity Debugging. Limits to Scaling.

E N D
Parallel Programming & StuffJud Leonard February 28, 2008
Outline • Parallel problems • Simulation Models • Imaging • Monte Carlo methods • Embarrassing Parallelism • Software issues due to parallelism • Communication • Synchronization • Simultaneity • Debugging
Limits to Scaling • Amdahl’s Law: serial eventually dominates • Seldom the limitation in practice • Gustafson: Big problems have lots of parallelism • Often in practice, communication dominates • Each node treats a smaller volume • Each node must communicate with more partners • More, smaller messages in the fabric • Improved communication enables scaling • Communication is key to higher performance
Physical System Simulations • Spatial partition of problem • Works best if compute load evenly distributed • Weather, Climate • Fluid dynamics • Complex boundary management after load balancing • Partition criteria must balance: • Communication • Compute • Storage
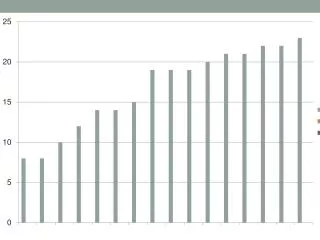
Example: 3D Convolution • Operate on N3 array with M3 processors • Result is a weighted sum of neighbor points • Single-processor • no communication cost • Compute time ≈ N3 • 3D partition • Communication ≈ (N/M)2 • Compute Time ≈ (N/M)3
Scalability of 3D Convolution Effect of Cost Ratio on Scaling Efficiency
Example: Logic Simulation • Modern chips contain many millions of gates • Enormous inherent parallelism in model • Product quality depends on test coverage • Economic incentive • Perfect application for parallel simulation • Why has nobody done it? • Communication costs • Complexity of partition problem • Multidimensional non-linear optimization
Example: Seismic Imaging • Similar to Radar, Sonar, MRI… • Record echoes of a distinctive signal • Correlate across time and space • Estimate remote structure from variation in echo delay at multiple sensors • Terabytes of data • Need efficient algorithms • Every sensor affected by the whole structure • How to partition for efficiency?
New Issues due to Parallelism • Communication costs • My memory is more accessible than others • Planning, sequencing halo exchanges • Bulk transfers most efficient • but take longer • Subroutine syntax vs Language intrinsic • Coherence and synchronization explicitly managed • Issues of grain size • Synchronization • Coordination of “loose” parallelism • Identification of necessary sync points
Mind Games • Simultaneity • Contrary to habitual sequential mindset • Access to variables is not well-ordered between parallel threads • Order is not repeatable • Debugging • Printf? • Breakpoints? • Timestamps?
Interesting Problems - Parallelism • Event-driven simulation • Load balancing • Debugging • Correctness • Dependency • Synchronization • Performance • Critical paths
The Kautz Digraph • Log diameter (base 3, in our case) • Reach any of 972 nodes in 6 or fewer steps • Multiple disjoint paths • Fault tolerance • Congestion avoidance • Large bisection width • No choke points as network grows • Natural tree structure • Parallel broadcast & multicast • Parallel barriers & collectives
Alphabetic Construction • Node names are strings of length k (diameter) • Alphabet of d+1 letters (d = degree) • No letter repeats in adjacent positions • ABAC: allowed • ABAA: not allowed • Network order = (d+1)dk-1 • d+1 choices for first letter • d choices for (k-1) letters • Connections correspond to shifts • ABAC, CBAC, DBAC -> BACA, BACB, BACD
Noteworthy • Most paths simply shift in destination ID • ABCD -> BCDB -> CDBA -> DBAD -> BADC • Unless tail overlaps head • ABCD -> BCDA -> CDAB • A few nodes have bidirectionally-connected neighbors • ABAB <-> BABA • A “necklace” consists of nodes whose names are merely rotations of each other • ABCD -> BCDA -> CDAB -> DABC -> ABCD again
Whatsa Kautz Graph? 0 3 1 2
Kautz Graph Topology 0 1 2 11 3 10 4 9 5 8 7 6
Whatsa Kautz Graph? 0 1 2 3 4 5 6 7 8 35 9 34 10 33 11 32 12 31 13 30 14 29 15 28 16 27 17 26 25 24 23 22 21 20 19 18
Interconnect Fabric • Logarithmic diameter • Low latency • Low contention • Low switch degree • Multiple paths • Fault tolerant to link, node, or module failures • Congestion avoidance • Cost-effective • Scalable • Modular
DMA Engine API • Per-process structures: • Command and Event queues in user space • Buffer Descriptor table (writable by kernel only) • Route Descriptor table (writable by kernel only) • Heap (User readable/writable) • Counters (control conditional execution) • Simple command set: • Send Event: immediate data for remote event queue • Put Im Heap: immediate data for remote heap • Send Command: nested command for remote exec • Put Buffer to Buffer: RDMA transfer • Do Command: conditionally execute command string
Interesting Problems - SiCortex • Collectives optimized for Kautz digraph • Optimization for a subset • Primitive operations • Partitions • Best subsets to choose • Best communication pattern within a subset • Topology mapping • N-dimensional mesh • Tree • Systolic array • Global shared memory
27-node Module PCIe Express Module Options Module Service Processor Fibre Channel 10 Gb Ethernet InfiniBand MSP Ethernet Dual Gigabit Ethernet ICE9 Node Chip DDR2 DIMM Backpanel Connector Power regulator
Designed for HPC It’s not x86 Performance = low power Communication Kautz digraph topology Messaging: 1st class op Mesochronous cluster Open source everything Performance counters Reliable by design ECC everywhere Thousands of monitors Factors of 3 Lighted gull wing doors! Linux (Gentoo) Little-endian MIPS-64 ISA Pathscale compiler GNU toolchain IEEE Floating Point MPI PCI Express I/O What’s new or unique? What’s not?