Download

1 / 59
590 likes | 745 Vues
Relational Query Processing Approach to Compiling Sparse Matrix Codes. Vladimir Kotlyar Computer Science Department, Cornell University http://www.cs.cornell.edu/Info/Project/Bernoulli. Outline . Problem statement Sparse matrix computations Importance of sparse matrix formats

E N D
Relational Query Processing Approach to Compiling Sparse Matrix Codes Vladimir Kotlyar Computer Science Department, Cornell University http://www.cs.cornell.edu/Info/Project/Bernoulli
Outline • Problem statement • Sparse matrix computations • Importance of sparse matrix formats • Difficulties in the development of sparse matrix codes • State-of-the-art restructuring compiler technology • Technical approach and experimental results • Ongoing work and conclusions
Sparse Matrices and Their Applications • Number of non-zeroes per row/column << n • Often, less that 0.1% non-zero • Applications: • Numerical simulations, (non)linear optimization, graph theory, information retrieval, ...
Application: numerical simulations • Fracture mechanics Grand Challenge project: • Cornell CS + Civil Eng. + other schools; • supported by NSF,NASA,Boeing • A system of differential equations is solved over a continuous domain • Discretized into an algebraic system in variables x(i) • System of linear equations Ax=b is at the core • Intuition: A is sparse because the physical interactions are local
Application: Authoritative sources on the Web • Hubs and authorities on the Web • Graph G=(V,E) of the documents • A(u,v) = 1 if (u,v) is an edge • A is sparse! • Eigenvectors of identify hubs, authorities and their clusters (“communities”) [Kleinberg,Raghavan ‘97] Hubs Authorities
Sparse matrix algorithms • Solution of linear systems • Direct methods (Gaussian elimination): A = LU • Impractical for many large-scale problems • For certain problems: O(n) space, O(n) time • Iterative methods • Matrix-vector products: y = Ax • Triangular system solution: Lx=b • Incomplete factorizations: A LU • Eigenvalue problems: • Mostly matrix-vector products + dense computations
Sparse matrix computations • “DOANY” -- operations in any order • Vector ops (dot product, addition,scaling) • Matrix-vector products • Rarely used: C = A+B • Important: C A+B, A A + UV • “DOACROSS” -- dependencies between operations • Triangular system solution: Lx = b • More complex applications are built out of the above + dense kernels • Preprocessing (e.g. storage allocation): “graph theory”
Outline • Problem statement • Sparse matrix computations • Sparse Matrix Storage Formats • Difficulties in the development of sparse matrix codes • State-of-the-art restructuring compiler technology • Technical approach and experiments • Ongoing work and conclusions
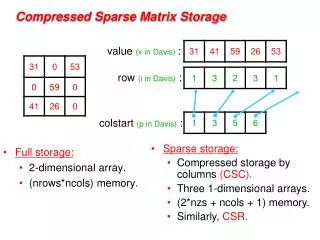
Storing Sparse Matrices • Compressed formats are essential • O(nnz) time/space, not O(n²) • Example: matrix-vector product • 10M row/columns, 50 non-zeroes/row • 5 seconds vs 139 hours on a 200Mflops computer (assuming huge memory) • A variety of formats are used in practice • Application/architecture dependent • Different memory usage • Different performance on RISC processors
Point formats Coordinate Compressed Column Storage
Block formats • Block Sparse Column • “Natural” for physical problems with several unknowns at each point in space • Saves storage: 25% for 2-by-2 blocks • Improves performance on modern RISC processors
Why multiple formats: performance • Sparse matrix-vector product • Formats: CRS, Jagged diagonal, BlockSolve • On IBM RS6000 (66.5 MHz Power2) • Best format depends on the application (20-70% advantage)
Bottom line • Sparse matrices are used in a variety of application areas • Have to be stored in compressed data structures • Many formats are used in practice • Different storage/performance characteristics • Code development is tedious and error-prone • No random access • Different code for each format • Even worse in parallel (many ways to distribute the data)
Libraries • Dense computations: Basic Linear Algebra Subroutines • Implemented by most computer vendors • Few formats, easy to parametrize: row/column-major, symmetric/unsymmetric, etc • Other computations are built on top of BLAS • Can we do the same for sparse matrices?
Sparse Matrix Libraries • Sparse Basic Linear Algebra Subroutine (SPBLAS) library [Pozo,Remington @ NIST] • 13 formats ==> too many combinations of “A op B” • Some important ops are not supported • Not extensible • Coarse-grain solver packages [BlockSolve,Aztec,…] • Particular class of problems/algorithms (e.g. iterative solution) • OO approaches: hooks for basic ops (e.g. matrix-vector product)
Our goal: generate sparse codes automatically • Permit user-defined sparse data structures • Specialize high-level algorithm for sparsity, given the formats FOR I=1,N sum = sum + X(I)*Y(I) FOR I=1,N such that X(I)0 and Y(I)0 sum = sum + X(I)*Y(I) executable code
Input to the compiler • FOR-loops are sequential • DO-loops can be executed in any order (“DOANY”) • Convert dense DO-loops into sparse code DO I=1,N; J=1,N Y(I)=Y(I)+A(I,J)*X(J) for(j=0; j<N;j++) for(ii=colp(j);ii < colp(j+1);ii++) Y(rowind(ii))=Y(rowind(ii))+vals(ii)*X(j);
Outline • Problem statement • State-of-the-art restructuring compiler technology • Technical approach and experiments • Ongoing work and conclusions
An example: locality enhancement • Matrix-vector product, array A stored in column/major order FOR I=1,N FOR J=1,N Y(I) = Y(I) + A(I,J)*X(J) • Would like to execute the code as: FOR J=1,N FOR I=1,N Y(I) = Y(I) + A(I,J)*X(J) • In general? Stride-N Stride-1
An abstraction: polyhedra • Loop nests == polyhedra in integer spaces FOR I=1,N FOR J=1,I ….. • Transformations • Used in production and research compilers (SGI, HP, IBM)
Caveat • The polyhedral model is not applicable to sparse computations FOR I=1,N FOR J=1,N IF (A(I,J) 0) THEN Y(I) = Y(I) + A(I,J)*X(J) • Not a polyhedron What is the right formalism?
Extensions for sparse matrix code generation FOR I=1,N FOR J=1,N IF (A(I,J) 0) THEN Y(I)=Y(I)+A(I,J)*X(J) • A is sparse, compressed by column • Interchange the loops, encapsulate the guard FOR J=1,N FOR I=1,N such that A(I,J) 0 ... • “Control-centric” approach: transform the loops to match the best access to data [Bik,Wijshoff]
Limitations of the control-centric approach • Requires well-defined direction of access
Outline • Problem statement • State-of-the-art restructuring compiler technology • Technical approach and experiments • Ongoing work and conclusions
Data-centric transformations • Main idea: concentrate on the data DO I=…..; J=... …..A(F(I,J))….. • Array access function: <row,column> = F(I,J) • Example: coordinate storage format:
Data-centric sparse code generation • If only a single sparse array: FOR <row,column,value> in A I=row; J=column Y(I)=Y(I)+value*X(J) • For each data structure provide an enumeration method • What if more than one sparse array? • Need to produce efficient simultaneous enumeration
Efficient simultaneous enumeration DO I=1,N IF (X(I) 0 and Y(I) 0) THEN sum = sum + X(I)*Y(I) • Options: • Enumerate X, search Y: “data-centric on” X • Enumerate Y, search X: “data-centric on” Y • Can speed up searching by scattering into a dense vector • If both sorted: “2-finger” merge • Best choice depends on how X and Y are stored • What is the general picture?
An observation DO I=1,N IF (X(I) 0 and Y(I) 0) THEN sum = sum + X(I)*Y(I) • Can view arrays as relations (as in “relational databases”) X(i,x) Y(i,y) • Have to enumerate solutions to the relational query Join(X(i,x), Y(i,y))
Connection to relational queries • Dot product Join(X,Y) • General case?
From loop nests to relational queries DO I, J, K, ... …..A(F(I,J,K,...))…..B(G(I,J,K,...))….. • Arrays are relations (e.g. A(r,c,a)) • Implicitly store zeros and non-zeros • Integer space of loop variables is a relation, too: Iter(i,j,k,…) • Access predicate S: relates loop variables and array elements • Sparsity predicate P: “interesting” combination of zeros/non-zeros Select(P, Select(S Bounds, Product(Iter, A, B, …)))
Why relational queries? [Relational model] provides a basis for a high level data language which will yield maximal independence between programs on the one hand and machine representation and organization of data on the other E.F.Codd (CACM, 1970) • Want to separate what is to be computed from how
CRS CCS BRS Coordinate …. Bernoulli Sparse Compilation Toolkit Input program • BSCT is about 40K lines of ML + 9K lines of C • Query optimizer at the core • Extensible: new formats can be added Front-end Query Optimizer Abstractproperties Plan Macros Instantiator Low level C code
Query optimization: implementing joins FOR I Join(A,Y) FOR J Join(A(I,*), X) .…. FOR I Merge(A,Y) H = scatter(X) FOR J enumerate A(I,*), search H ….. • Output is called a plan
Instantiator: executable code generation H=scatter X FOR I Merge(A,Y) FOR J enumerate A(I,*), search H ….. ….. for(I=0; I<N; I++) for(JJ=ROWP(I); JJ < ROWP(I+1); JJ++) ….. • Macro expansion • Open system
Summary of the compilation techniques • Data-centric methodology: walk the data,compute accordingly • Implementation for sparse arrays • arrays = relations, loop nests = queries • Compilation path • Main steps are independent of data structure implementations • Parallel code generation • Ownership, communication sets,... = relations • Difference from traditional relational databases query opt. • Selectivity of predicates not an issue; affine joins
Experiments • Sequential • Kernels from SPBLAS library • Iterative solution of linear systems • Parallel • Iterative solution of linear systems • Comparison with the BlockSolve library from Argonne NL • Comparison with the proposed “High-Performance Fortran” standard
Setup • IBM SP-2 at Cornell • 120 MHz P2SC processor at each node • Can issue 2 multiply-add instructions per cycle • Peak performance 480 Mflops • Much lower on sparse problems: < 100 Mflops • Benchmark matrices • From Harwell-Boeing collection • Synthetic problems
Matrix-vector products • BSR = “Block Sparse Row” • VBR = “Variable Block Sparse Row” • BSCT_OPT = Some “Dragon Book” optimizations by hand • Loop invariant removal
Solution of Triangular Systems • Bottom line: • Can compete with the SPBLAS library (need to implement loop invariant removal :-)
Iterative solution of sparse linear systems • Essential for large-scale simulations • Preconditioned Conjugate Gradients (PCG) algorithm • Basic kernels: y=Ax, Lx=b +dense vector ops • Preprocessing step • Find M such that • Incomplete Cholesky factorization (ICC): • Basic kernels: , sparse vector scaling • Can not be implemented using the SPBLAS library • Used CCS format (“natural” for ICC)
Iterative Solution • ICC: a lot of “sparse overhead” • Ongoing investigation (at MathWorks): • Our compiler-generated ICC is 50-100 times faster than Matlab implementation !!
Iterative solution (cont.) • Preliminary comparison with IBM ESSL DSRIS • DSRIS implements PCG (among other things) • On BCSSTK30; have set values to vary the convergence • BSCT ICC takes 1.28 secs • ESSL DSRIS preprocessing (ILU+??) takes ~5.09 secs • PCG iterations are ~15% faster in ESSL
Parallel experiments • Conjugate Gradient algorithm • vs BlockSolve library (Argonne NL) • “Inspector” phase • Pre-computes what communication needs to occur • Done once, might be expensive • “Executor” phase • “Receive-compute-send-...” • On Boeing-Harwell matrices • On synthetic grid problems to understand scalability
Executor performance • Grid problems: problem size per processor is constant • 135K rows, ~4.6M non-zeroes • Within 2-4% of the library
Inspector overhead • Ratio of the inspector to single iteration of the executor • A problem-independent measure • “HPF-2” -- new data-parallel Fortran standard • Lowest-common denominator, inspectors are not scalable
Experiments: summary • Sequential • Competitive with SPBLAS library • Parallel • Inspector phase should exploit formats (cf. HPF-2)
Outline • Problem statement • State-of-the-art restructuring compiler technology • Technical approachand experiments • Ongoing work and conclusions
Ongoing work • Packaging • “Library-on-demand”; as a Matlab toolbox • Parallel code generation • Extend to handle more kernels • Core of the compiler • Disjunctive queries, fill
Ongoing work • Packaging • “Library-on-demand”; as a Matlab toolbox • Completely automatic tool; data structure selection • Out-of-core computations • Parallel code generation • Extend to handle more kernels • Core of the compiler • Disjunctive queries, fill