Download

1 / 13
130 likes | 209 Vues
Flexible Metric NN Classification. based on Friedman (1995) David Madigan. Nearest-Neighbor Methods. k -NN assigns an unknown object to the most common class of its k nearest neighbors Choice of k ? (bias-variance tradeoff again) Choice of metric?

E N D
Flexible Metric NN Classification based on Friedman (1995) David Madigan
Nearest-Neighbor Methods • k-NN assigns an unknown object to the most common class of its k nearest neighbors • Choice of k? (bias-variance tradeoff again) • Choice of metric? • Need all the training to be present to classify a new point (“lazy methods”) • Surprisingly strong asymptotic results (e.g. no decision rule is more than twice as accurate as 1-NN)
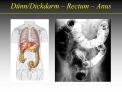
Suppose a Regression Surface Looks like this: want this not this Flexible-metric NN Methods try to capture this idea…
FMNN • Predictors may not all be equally relevant for classifying a new object • Furthermore, this differential relevance may depend on the location of the new object • FMNN attempts to model this phenomenon
Local Relevance • Consider an arbitrary function f on Rp • If no values of x are known, have: • Suppose xi=z, then:
Local Relevance cont. • The improvement in squared error provided by knowing xi is: • I2i(z) reflects the importance of the ith variable on the variation of f(x) at xi=z
Local Relevance cont. • Now consider an arbitrary point z=(z1,…,zp) • The relative importance of xi to the variation of f at x=z is: • R2i(z)=0 when f(x) is independent of xi at z • R2i(z)=1 when f(x) depends only on xi at z
Estimation • Recall:
On To Classification • For J-class classification have {yj}, j=1,…,J output variables, yje {0,1}, S yj=1. • Can compute: • Technical point: need to weight the observations to rectify unequal variances
The Machete • Start with all data points R0 • Compute • Then: • Continue until Ri contains K points M1th order statistic