Download

1 / 25
250 likes | 386 Vues
College of Education and Health Professions. The Normal Distribution . Chapter 3. Assumption of Normality. Many statistical tests (t, ANOVA) assume that the sampling distribution is normally distributed. This is a problem, we don’t have access to the sampling distribution.

E N D
College of Education and Health Professions The Normal Distribution Chapter 3
Assumption of Normality • Many statistical tests (t, ANOVA) assume that the sampling distribution is normally distributed. • This is a problem, we don’t have access to the sampling distribution. • But, according to the central limit theorem if the sample data are approximately normal, then the sampling distribution will be normal. • Also from the central limit theorem, in large samples (n > 30) the sampling distribution tends to be normal, regardless of the shape of the data in our sample. • Our task is to decide when a distribution is approximately normal.
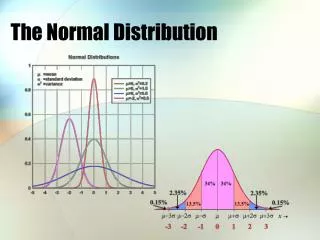
A Z Score is a Standardized Statistic 95.0% of the scores fall between a Z of -1.96 to +1.96 97.4% of the scores fall between a Z of -3.00 to +3.00 99.9% of the scores fall between a Z of -3.30 to +3.30
How do we decide if a distribution is approximately normal? 99.9% of the scores fall between a Z of -3.30 to +3.30
Normality Statistics are not Reliable for Large Samples Z > 1.95 is significant at p < .05 Z > 2.58 is significant at p < .01 Z > 3.29 is significant at p < .001 Significance tests for normality: Kolomogorov-Smirnov, Shapiro-Wilk, skew, kurtosis, should not be used in large samples (because they are likely to be significant even when skew and kurtosis are not too different from normal.
Small Data Sets (n<20) and Normality? -.91 -.04 -.28 -.36 -1.86 -2.99 -.32 1.63 -.19 -.32 Small data sets are adversely affected by occasional extreme scores, even when the extreme score is less than a Z of 3.3.
Approximately Normal? • We will use the following to determine if a distribution is approximately normal: • Q-Q Plot values should lie close to the 45 line. • Distribution should be similar in shape to the normal curve. • Skew & Kurtosis should be reasonably close to 0. • Data points with a Z score > +3.3 or < -3.3 will be considered as outliers and removed.
Histogram with Normal Curve Distribution may be leptokurtic (peaked) Positively skewed? Need to run Explore.
We are 95% sure that the true mean lies between 58.721 and 61.7085. The distribution is positively skewed. The distribution is leptokurtic. This may be an outlier, we can use the descriptives command to generate Z scores.
Don’t use the K-S test for normality. If the Shapiro-Wilk is less than 0.05 the data may not be normal. But, it is not a perfect test. For small data sets (n < 100) if S-W has a p < 0.001 the data may not be normal. The test is unreliable for large data sets n > 100.
The circles should fall on the 45 degree line. For this data set the ends are deviating from the line, again suggesting a problem with normality.
Case number 282 has a star, indicating that it is an extreme score. An extreme value, E, is defined as a value that is smaller (or larger) than 3 box-lengths. We need to convert the data to Z scores to examine the Z for case 282.
Check this box to generate Z scores for any variables in the Variable(s) box. The output is shown on the next slide, it places the Z score in your Data Sheet by adding a Z in front of the variable(s) selected.
The new column ZReactionTime contains the Z scores for ReactionTime. The Z score for case 282 is 4.944. Since the value is much greater than our arbitrary cutoff of 3.3. We will delete this data point then re-run Explore. Copy the column, rename the new variable RTimeTrimmed, then delete case 282.
The top descriptive output is the original data set. Here is the data set with case 282 removed. Look at the changes in the 95% CI, Skew and Kurtosis.
The Shapiro-Wilk is significant, indicating there may be a problem with normality. Looks like case 84 and 100 may be the cause. We need to generate Z scores again.
The Q-Q plot and the box plot both suggest a problem. We need to run Z scores to look at case 100 & 84.
Compute Z scores for the RTimeTrimmed variable. The new variable will be in the data sheet labeled ZRTimeTrimmed
Both case 84 & 100 have a Z score above 3.3, our arbitrary cutpoint. We can delete them and then run Explore. Copy column RTimeTrimmed, make a new variable RTimeTrimmed2
The original data set is on the top. RTimeTrimmed2 now has 3 data points that have been deleted.
Looking better, run Z scores again on RTimeTrimmed2, check cases 235 & 290.
The Z score for case 235 is 3.17, and for case 290 is 2.92. They are both below our arbitrary cutoff of 3.3 for a Z score. The distribution is now approximately normally distributed.