Download

1 / 37
370 likes | 405 Vues
This survey covers parallel computer architectures like pipelining, multiple CPU functional units, and separate CPU and I/O processors. It includes performance comparisons, Flynn's Taxonomy classification, SIMD architectures, and more.

E N D
A Survey of Parallel Computer Architectures • CSC521 Advanced Computer Architecture • Dr. Craig Reinhart • The General and Logical Theory of Automata • Lin, Shu-Hsien (ANDY) • 4/24/2008
What is the parallel computer architectures? • Pipelining Instruction • Multiple CPU Functional Units • Separate CPU and I/O processors
Pipelining Instruction • Decompose the pipelining instruction, it can be executed into a linear series of autonomous stages, allowing each stage to simultaneously perform every portion of the execution process (such as decoding, calculating effective address, fetching operand, executing, and storing).
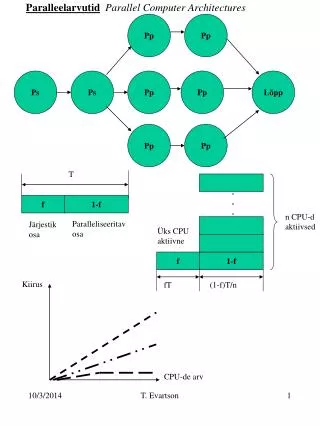
Pipelining vs. Single-cycle processors • For single-cycle processor it takes 16 nanosecond to execute four instructions, while for pipelining processor it takes only 7 nanoseconds.
Multiple CPU Functional Units(1) • Multiple CPU Functional Units provides independent functional units for arithmetic and Boolean operations that execute concurrently.
Multiple CPU Functional Units(2) • A parallel computer has three types of parts: • Processors • Memory modules • Communication / synchronization network
Single Processor V.S. Multi-Processor Energy-Efficient Performance The two figures are showing the different performance with a single processor and multi-processors: • The right above figure shows that based on the single processor. Increasing clock frequency by 20% to single processor delivers a 13% percent performance gain, but require73% greater Power. • The below figure shows that adding a second processor on the under-clocking experience, the clock frequency effectively delivers 73% more performance.
Separate CPU and I/O processors • Freeing the CPU from I/O control responsibilities by using dedicated I/O processors; solutions range from relatively simple I/O controllers to complex peripheral processing units.
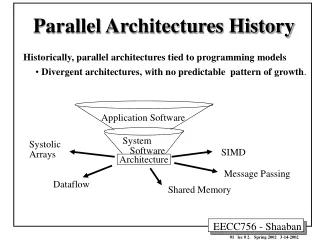
High-level Taxonomy of Parallel Computer Architectures • A parallel architecture provides an explicit, high-level framework for the parallel programming solutions by providing multiple processors, whether simple or complex, that cooperate to solve problems through concurrent execution.
Flynn’s TaxonomyClassifies Architectures (1) • SISD--(single instruction, single data stream) -- Defines serial computers. -- An ordinary computer • MISD--(multiple instruction, single data stream) -- It would involve multiple processors applying different instructions to a single datum; this hypothetical possibility is generally deemed to be impractical.
Flynn’s TaxonomyClassifies Architectures (2) • SIMD--(single instruction, multiple data streams) -- It involves multiple processors simultaneously executing the same instruction on different data -- Massively parallel army-of-ants approach: processors execute the same sequence of instructions (or else NO-OP) in lockstep (TMC CM-2) • MIMD--(multiple instruction, multiple data streams) -- It involves multiple processors autonomously executing diverse instructions on diverse data -- It is true, symmetric, parallel computing (Sun Enterprise)
Pipelined Vector Processors • Vector processors are characterized by multiple, pipelined functional units. • The architecture provides parallel vector processing by sequentially streaming vector elements through a functional unit pipeline and by streaming the output results of one units into the pipeline of another as input.
Register-to-Register Vector Architecture Operation. • Each pipeline stage in the hypothetical architecture has a cycle time of 20 nanoseconds. • And then 120 ns elapse from the time operands a1 and b1 enter stage 1 until result c1 is available.
SIMD Architectures • SIMD architectures employ: • a central control unit • multiple processors • Interconnection network (IN) • Function: --For either processor-to-processor or processor-to-memory communication.
SIMD Architectures computed Example • A SIMD architectures :Vector Computer • For example: Adding two real Arrays A, B. shows in the below figure
SIMD Architectures Problems Some SIMD problems, e.g. • SIMD cannot use commodity processors • SIMD cannot supports multiple users • SIMD is less efficiency in conditionally executed parallel code
Bit-Plane Array Processing • Processor arrays structured for numerical SIMD execution have been employed for large-scale scientific calculations. For example: Image processing and nuclear energy model. • In bit-plane architectures, the array of processors is arranged in a symmetrical grid (such as 64x64) and associated with multiple “planes” of memory bits that correspond to the dimensions of the processor grid.
Associative Memory Processing Organization The right figure is showing the characteristic functional units of an associative memory processor. • A program controller (serial computer) reads and executes instructions, invoking a specialized array controller when associative memory instructions are encountered. • Special registers enable the program controller and associative memory to share data
Associative Memory Comparison Operation • The right figure shows a row-oriented comparison operation for a generic bit-serial architecture. • All of the associative processing elements start at a specified memory column and compare the contents of four consecutive bits in their row against the comparison register contents, setting a bit in the A register to indicate whether or not their row contains a match.
Associative Memory Logical OR Operation • The right figure is showing that a logical OR operation is performed on a bit-column and the bit-vector in register A, with register B receiving the results. • A zero in the mask register indicates that the associated word is not to be included in the current operation.
Systolic Flow of Data From and to Memory • Systolic architectures (systolic arrays) are pipelined multiprocessors in which data is pulsed in rhythmic fashion from memory and through a network of processors before returning to memory
Systolic Matrix Multiplication • Right figure is a simple systolic array • A= |ab| and B= |ef| |cd| |gh| • The zero inputs shown moving through the array are used for synchronization. • Each processor begins with an accumulator set to zero and, during each cycle, adds the product of its two inputs to the accumulator. • After five cycles the matrix product is complete. Go back page 34
MIMD Architectures • MIMD architectures employ multiple instruction streams, using local data. • MIMD computers support parallel solution that require processors to operate in a largely autonomous manner
MIMD Distributed Memory Architecture Structure • Distributed memory architectures connect processing nodes (consisting of an autonomous processor and its local architecture structure. memory) with a processor-to-processor interconnection network.
Example: Distributed Memory Architectures • Right figure is IBM RS/6000 SP machine. It is a distributed memory architectures machine.
Interconnection Network Topologies • Various interconnection network topologies have been proposed to support architectural expandability and provide efficient performance for parallel programs with differing interprocessor communication patterns. • Right figure a-e depicts the topologies which are a) ring, b) mesh, c) tree, d) hypercube, and e) tree mapped to a reconfigurable mesh
Shared-Memory Architecture • Shared memory architectures accomplish interprocessor coordination by providing a global, shared memory that each processor can address. • In the right figure is showing some major alternatives for connecting multiple processors to shared memory. • Figure a) shows bus interconnection, b) shows 2 ╳2 crossbar, c) shows 8 ╳8 omega MIN routing a P3 require to M3
MIMD/SIMD Operations • A MIMD architecture to be controlled in SIMD fashion. • The master/slaves relation of a SIMD architecture’s controller and processors can be mapped onto the node/descendents relation of a subtree • When the root processor node of a subtree operates as a SIMD controller, it transmits instructions to descendent nodes that execute the instructions on local memory data.
Dataflow Architectures • Dataflow architectures. The fundamental feature of dataflow architectures is an execution paradigm in which instructions are enabled for execution as soon as all of their operands become available. • The program fragment dataflow graphs is shown in the right figure.
Dataflow Token-Matching Example • At step 1, the execution of (3*a)=> the result is 15 and the instruction at node 3 requires an operand. • Step 2, the match this token=> the result of token of (5*b) with the node 3 instruction. • Step 3, the matching unit creates the instruction token (template). • Step 4, the node store unit obtains the relevant instruction opcode from memory. • Step 5, The node store unit then fills in the relevant token fields and assigns the instruction to a processor. The execution of the instruction will create a new result token to be used as input to the node 4 instruction.
Reduction Architecture Demand Token Production(1) • The figure is a simplified version of a graph-reduction architecture that maps the program below onto trees-structured processors and passes tokens that demand or return results. • In the right figure, it depicts all the demand tokens produced by the program, as demands for the values of references propagate down the tree. • The algorithms example is shown as below: a=+bc; b=+de; c=*fg; d=l;e=3;f=5;g=7
Reduction Architecture Demand Token Production(2) • In the right figure, it depicts the last two results that tokens produced are shown as they are passed to the root node. • The Algorithm example is shown as below: a=+bc; b=+de; c=*fg; d=l;e=3;f=5;g=7
Wavefront Array Matrix Multiplication (1) • The right figure a-c with the following PowerPoint slices depicts the wavefront array concepts, using the matrix multiplication example used earlier to illustrate systolic operation on page 23of PowerPoint • Figure (a) shown on the right side is the situation that buffers are initially filled after memory input.
Wavefront Array Matrix Multiplication (2) • Figure (b) ,PE(1,1) adds the product ae to its accumulator and transmits operands a and e to neighbors; thus, the first computational wavefront is shown propagating from PE(l,l) to PE(1,2) and PE(2,l).
Wavefront Array Matrix Multiplication (3) • Figure (c ) shows the first computational wavefront continuing to propagate, while a second wavefront is propagated by PE(l,l).
Conclusion • What is the parallel computer architectures? R.W. Hackney term: “A confusing menagerie of computer designs.”