Download

1 / 16
160 likes | 309 Vues
Macro instruction synthesis for embedded processors. Pinhong Chen Yunjian Jiang (william) - CS252 project presentation. Control. I/D Mem . Macro Instr. Ext. ALU. control. Reg Bus unit. Reg/Mem Access. Motivation. Start from a simple processor core

E N D
Macro instruction synthesis for embedded processors Pinhong Chen Yunjian Jiang (william) - CS252 project presentation
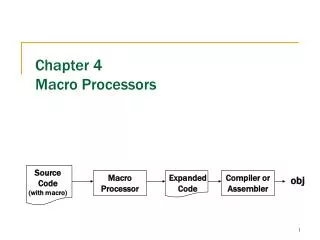
Control I/DMem. Macro Instr. Ext. ALU control Reg Bus unit Reg/Mem Access Motivation • Start from a simple processor core • Find new macro instructions to enhance performance and reduce code size • Application-specific • Using dedicated hardware to speed up Application
RISC8 Architecture • Why RISC8? • Simple • 8-bit ISA with 43 Instructions • Addressable space 64K bytes • Complete ISA, including • Load/Store, Arithmetic, Logical , Branch, Multiplication,Division, Stack Operation, Subroutine call, Interrupt Operations, etc. • Small • Verilog core size is 3.5K gates in 0.25um • clock speed of 300MHz is reported (our result is about 200MHz) • Synthesizable RTL Core • Free assembler
Instr. Profiling Istr. Syn Istr. Syn Istr. Syn Methodology Application (*.c) Front end performance IR (exp. tree) Code Gen. simulation RTL exp. tree Asm. code Assembler mach. code
ASSIGN ADD VAR AND VAR VAR CON Different Levels of expression trees sum += c & 5 ASSIGN ASSIGN reg byte MOV acc addr16 ADD ADD acc AND VAR reg AND VAR con08 byte acc reg addr16 byte con08 Reconstructed from mach. code SUIF IR RTL IR after code gen
Expression trees SUIF IR • Data type carried • Inaccurate cost • No profiling • Simple – less tree nodes • Machine independent • Register level • Data type carried • One-to-one between macro instructions • Profiling data can be back annotated • Machine dependent • Machine code • Data type lost • One-to-one between machine instructions • Profiling data accurate • Large expression trees • Machine dependent
Instruction Enumeration • Traverse tree structure in post-order • Normalize sub-tree orders • Combine patterns from sub-trees • Hash new instruction patterns • Collect register usage and memory access for evaluation • Annotate profiling information ADD acc reg AND byte acc reg byte con08
Machine Code Level Tree Reconstruction • Build IR tree from machine codes • Recover data dependencies from assembly code • Clear definition by ISA • eg. AND r2 ==> acc=acc & r2 • Limited to a basic block • Eliminate intermediate storage nodes ADD acc reg AND byte acc reg byte con08
Machine Code Level Tree Reconstruction • Build IR tree from machine codes • Recover data dependencies from assembly code • Clear definition by ISA • eg. AND r2 ==> acc=acc & r2 • Limited to a basic block • Eliminate intermediate storage nodes ADD AND byte byte con08
Table-Driven Assembly Development Tools New Instruction Candidates Istr. Syn New Instr. Select Instr. Profile Special Instr. Special Instr. Simulator Disassembler Instr. Table performance Asm. code Assembler mach. code Asm. code
Table-driven back-end tool automation @new_ins=( 'mac'=>{otree=>['r0','nADD','r0',['nMUL','Rn','addr16']], pattern=>'Rn addr16', code=>['00000011','00000$Rn','$addr16[0]','$addr16[1]'], sim=>'$R[0]+=$R[$Rn]*$memory[$addr16]', cycles=>13, decode=>'$Rn=$memory[$pc++] & 0x7; $addr16[0]=$memory[$pc++]; $addr16[1]=$memory[$pc++]; $addr16=$addr16[0]|($addr16[1]<<8);‘ });
Op-Code Reuse • Op codes may not be fully used in a specific application • Remove un-used instruction op-codes • Typical applications use far less than 256 op-codes • Cost of op-code reuse • Decoding logic • Less flexibility
Implementation • Compiler front-end: SUIF • Code generator: SPAM-olive • Retargeted to RISC8 • RTL pattern enumeration: C++ • RISC8 assembler: PERL • RISC8 simulator: PERL • Machine level pattern enumeration: PERL • Macro driven instruction implementation automation: PERL
GSM encoder • Hardware/software tradeoff • Software gain: execution speed, code size • Hardware cost: functional unit, decoding logic, data path configuration
Conclusions • RTL level pattern enumeration • Key to automating instruction identification, code-generation, assembly and simulation • No need to change algorithm source code • Hardware/software trade-off • Good estimation of performance gain and hardware cost at register-transfer level • Op-code reuse