Download
1 / 1
10 likes | 128 Vues
Response bias, type and token frequency, and prosodic context in segment identification Noah Silbert & Kenneth de Jong Linguistics & Cognitive Science. Frequency Effects in Language Frequency effects are observed in low-level linguistic domains:

E N D
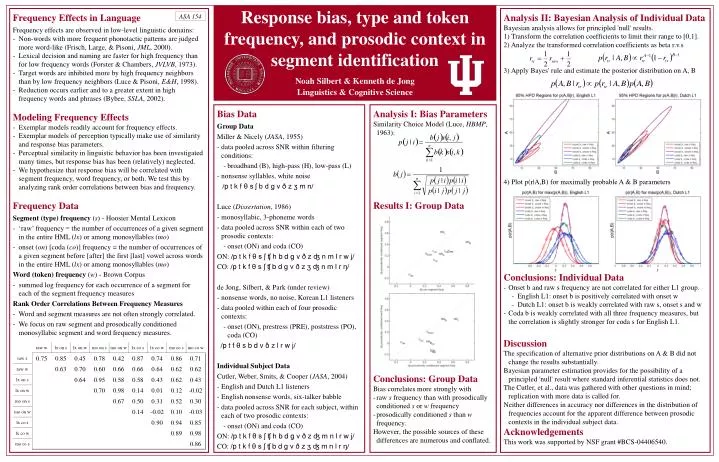
Response bias, type and token frequency, and prosodic context in segment identification Noah Silbert & Kenneth de Jong Linguistics & Cognitive Science • Frequency Effects in Language • Frequency effects are observed in low-level linguistic domains: • Non-words with more frequent phonotactic patterns are judged more word-like (Frisch, Large, & Pisoni, JML, 2000). • Lexical decision and naming are faster for high frequency than for low frequency words (Forster & Chambers, JVLVB, 1973). • Target words are inhibited more by high frequency neighbors than by low frequency neighbors (Luce & Pisoni, E&H, 1998). • Reduction occurs earlier and to a greater extent in high frequency words and phrases (Bybee, SSLA, 2002). • Modeling Frequency Effects • Exemplar models readily account for frequency effects. • Exemplar models of perception typically make use of similarity and response bias parameters. • Perceptual similarity in linguistic behavior has been investigated many times, but response bias has been (relatively) neglected. • We hypothesize that response bias will be correlated with segment frequency, word frequency, or both. We test this by analyzing rank order correlations between bias and frequency. • Frequency Data • Segment (type) frequency (s) - Hoosier Mental Lexicon • ‘raw’ frequency = the number of occurrences of a given segment in the entire HML (lx) or among monosyllables (mo) • onset (on) [coda (co)] frequency = the number of occurrences of a given segment before [after] the first [last] vowel across words in the entire HML (lx) or among monosyllables (mo) • Word (token) frequency (w) - Brown Corpus • - summed log frequency for each occurrence of a segment for each of the segment frequency measures • Rank Order Correlations Between Frequency Measures • Word and segment measures are not often strongly correlated. • We focus on raw segment and prosodically conditioned monosyllabic segment and word frequency measures. • Analysis II: Bayesian Analysis of Individual Data • Bayesian analysis allows for principled 'null' results. • 1) Transform the correlation coefficients to limit their range to [0,1]. • 2) Analyze the transformed correlation coefficients as beta r.v.s • 3) Apply Bayes' rule and estimate the posterior distribution on A, B • 4) Plot p(r|A,B) for maximally probable A & B parameters • Conclusions: Individual Data • Onset b and raw s frequency are not correlated for either L1 group. • English L1: onset b is positively correlated with onset w • Dutch L1: onset b is weakly correlated with raw s, onset s and w • Coda b is weakly correlated with all three frequency measures, but the correlation is slightly stronger for coda s for English L1. • Discussion • The specification of alternative prior distributions on A & B did not change the results substantially. • Bayesian parameter estimation provides for the possibility of a principled 'null' result where standard inferential statistics does not. • The Cutler, et al., data was gathered with other questions in mind; replication with more data is called for. • Neither differences in accuracy nor differences in the distribution of frequencies account for the apparent difference between prosodic contexts in the individual subject data. • Acknowledgements • This work was supported by NSF grant #BCS-04406540. ASA 154 • Bias Data • Group Data • Miller & Nicely (JASA, 1955) • data pooled across SNR within filtering conditions: • broadband (B), high-pass (H), low-pass (L) • nonsense syllables, white noise • /p t k f θ s ʃ b d g v ð z ʒ m n/ • Luce (Dissertation, 1986) • monosyllabic, 3-phoneme words • data pooled across SNR within each of two prosodic contexts: • onset (ON) and coda (CO) • ON: /p t k f θ s ʃ ʧ h b d g v ð z ʤ n m l r w j/ • CO: /p t k f θ s ʃ ʧ b d g v ð z ʒ ʤ n m l r ŋ/ • de Jong, Silbert, & Park (under review) • nonsense words, no noise, Korean L1 listeners • data pooled within each of four prosodic contexts: • onset (ON), prestress (PRE), poststress (PO), coda (CO) • /p t f θ s b d v ð z l r w j/ • Individual Subject Data • Cutler, Weber, Smits, & Cooper (JASA, 2004) • English and Dutch L1 listeners • English nonsense words, six-talker babble • data pooled across SNR for each subject, within each of two prosodic contexts: • onset (ON) and coda (CO) • ON: /p t k f θ s ʃ ʧ h b d g v ð z ʤ m n l r w j/ • CO: /p t k f θ s ʃ ʧ b d g v ð z ʒ ʤ m n l r ŋ/ • Analysis I: Bias Parameters • Similarity Choice Model (Luce, HBMP, 1963): • Results I: Group Data • Conclusions: Group Data • Bias correlates more strongly with • raw s frequency than with prosodically conditioned s or w frequency • prosodically conditioned s than w frequency. • However, the possible sources of these differences are numerous and conflated.





















