Download
1 / 41
410 likes | 556 Vues
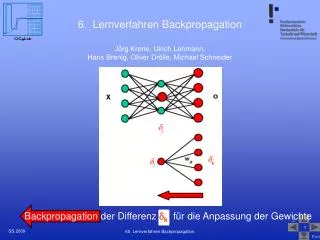
Fehler E. t-1. E. t. t+1. Δ w ij (t). Δ w ij (t-1). w ij. w ij. 7. Modifikationen von Backpropagation. Jörg Krone, Ulrich Lehmann, Hans Brenig, Oliver Drölle, Michael Schneider. Inhalt. Motivation für die Entwicklung von Trainingsverfahren Momentum-Term Flat-Spot Elimination

E N D
Fehler E t-1 E t t+1 Δwij (t) Δwij (t-1) wij wij 7. Modifikationen von Backpropagation Jörg Krone, Ulrich Lehmann, Hans Brenig, Oliver Drölle, Michael Schneider 70 Modifikation und Varianten des Backpropagation
Inhalt • Motivation für die Entwicklung von Trainingsverfahren • Momentum-Term • Flat-Spot Elimination • Weight Decay • Manhatten-Training • SuperSAB - Schrittweitenadaption Quickprop • Resilient Propagation (Rprop) • Levenberg-Marquardt (LM) • Zusammenfassung • Quellenangabe 70 Modifikation und Varianten des Backpropagation
Motivation Verbesserung der Trainingsverfahren mit den Zielen: • schneller – finde die neuen optimalen Gewichte möglichst schnell. Denn für sehr große Netze (>1000 Neuronen) oder viele Trainingsdatensätze kann das Training immer noch Stunden dauern • genauer – finde das globale Minimum für den Fehler E. Steigerung der Genauigkeit für die Produktionsphase • sicher konvergierend (stabiles Ergebnis) 70 Modifikation und Varianten des Backpropagation
Visualisierung der Varianten des Backpropagation MATLAB 7.1/Demos/toolboxes/nn… Kapitel 12 Kapitel 12: In den Demos von MATLAB werden die Verfahren zur Verbesserung des Backpropagation-Trainings als e-Simulation für ein MLP (1-2-1) gezeigt. Sie basieren meistens auf der folgenden Fehlerkurve für je ein Gewicht w1 des Hidden- und ein Gewicht w2 des Outputlayers (unten links) die zur performanteren Visualisierung in 2D mit Höhenlinien (gelbes Koordinatensystem unten rechts) gezeigt wird: >>nnd12sd1 Ziel: Minimum des Fehlers 70 Modifikation und Varianten des Backpropagation
Momentum-Term(MATLAB: traingdm) Prinzip: • Backpropagation mit Momentum-Term • wirkt wie ein Tiefpassfilter • die bereits vollzogene Gewichtsänderung zum Zeitpunkt t wird bei der Berechnung der Änderung zum Zeitpunkt t+1 mit einem Summanden berücksichtigt awij (t) • die Stärke des Momentum-Terms bestimmt der Faktor a • wij (t+1) = oi f‘j (net j) (tj – oj) + awij (t) • häufig im Bereich a = 0,6 bis 0,9 70 Modifikation und Varianten des Backpropagation
Demo: Backpropagation mit Momentum MATLAB 7.1/Demos/toolboxes/nn… Kapitel 12 Momentum Backpropagation – Einfluss des Momentum-Terms, um das Fehlerminimum im Höhenprofil der Fehlerkurve (rotes Kreuz auf gelber Fläche) zu finden: >>nnd12mo (Starten Sie bei 12/-5) 70 Modifikation und Varianten des Backpropagation
Momentum-Term: Bewertung • bei zu großen Lernraten besteht immer noch die Gefahr von Oszillationen über einem lokalen Minimum • etwas erhöhte Rechenzeit für eine Trainingsepoche durch eine weiter Multiplikation und Addition für jede Gewichtsänderung Bewertung: • Trainingsepochen (nicht -zeiten!) können dadurch gegenüber Standard-BAP z.B. für ein XOR-KNN mit 3 Layern (2-2-1) auf 1/8(!) reduziert werden • Training im Plateau-Bereich einer Fehlerkurve wird beschleunigt • Wahl einer geeigneten Lernrate wird etwas unkritischer, da der Momentum-Term die Gewichtsänderung im steilen Abstieg vergrößert und im Minimum verkleinert 70 Modifikation und Varianten des Backpropagation
Flat-Spot Elimination(modified sigmoid-prime function) Problem der Ableitung f‘j (net j) : • für sigmoide Aktivierungsfunktionen (logistische oder tanh) ist die Ableitung nahe 0 für Neuronen, die stark an (1) oder aus (0) sind • Beispiel: logistische Aktivierungs-funktionf‘j (net j) =[0-0,25] 70 Modifikation und Varianten des Backpropagation
Flat-Spot Elimination Prinzip: • Anheben der Ableitung der Aktivierungsfunktion um einen kleinen Betrag • Addition einer Konstanten zur Ableitung, damit die Funktion nicht 0 wird • f‘j (net j)mod = f‘j (net j) + 0,1 • damit verändert sich der Wertebereich für f‘j (net j)mod = [0,1-0,35] • Trainingszeiten können dadurch für das Encoder-Beispiel (10-5-10) auf die Hälfte reduziert werden 70 Modifikation und Varianten des Backpropagation
Flat-Spot Elimination: Bewertung • Wirkung bei sehr großen KNN (> 1000 Neuronen) noch nicht vollständig untersucht! Bewertung: • Trainingszeiten können dadurch z.B. für ein Encoder-KNN (ähnlich dem Decoder/DAU) mit 3 Layern (10-5-10) auf die Hälfte reduziert werden 70 Modifikation und Varianten des Backpropagation
Weight Decay (Gewichtsabnahme) • Prinzip: • neurobiologisch ist es unplausibel zu große Gewichte zuzulassen • große Erregungen (Ärger/Freude) werden am nächsten Tag abgeschwächter betrachtet • durch große Gewichte wird die Fehlerfläche steiler und stark zerklüftet • die bereits vollzogene Gewichtsänderung zum Zeitpunkt t wird bei der Berechnung der Änderung zum Zeitpunkt t+1 teilweise wieder subtrahiert - d wij (t) • die Stärke des Weight Decay bestimmt der Faktor d = 0,005 bis 0,03 • pwij (t+1) = opi pj- d pwij (t) 70 Modifikation und Varianten des Backpropagation
Demo: Weight Decay MATLAB 7.1/Demos/toolboxes/nn… Kapitel 13 Effects of Decay – Einfluss des Weight-Decay-Terms, um den Wert eines Gewichtes bei fortlaufender Anpassung (hier bis zu 30 Epochen) zu begrenzen: >>nnd13edr 70 Modifikation und Varianten des Backpropagation
Weight Decay: Bewertung • Bewertung: • Generalisierungsleistung wird durch kleine Gewichte verbessert • Vorsicht bei d >0,03ist geboten! Besser klein als zu groß! 70 Modifikation und Varianten des Backpropagation
Manhattan-Training Prinzip: • für die Gewichtsänderung in jedem Trainingszyklus wird nicht der Betrag dpi, sondern nur noch das Vorzeichen des Fehlersignals sgn (dpi) berücksichtigt • die Backpropagationregel wird damit ersetzt durch die verallgemeinerte und einfache Delta-Regelpwij = opi •sgn (dpi) 70 Modifikation und Varianten des Backpropagation
Manhattan-Training: Bewertung • entspricht nicht mehr dem steilsten Abstieg bezüglich des quadratischen Abstandes der Fehlerfunktion, sondern der linearen Fehlerfunktion E = p Ep = pj tpj – opj Bewertung: • Quasi-Normierung des Gradienten und damit der Gewichtsänderung mit geringem Rechenzeitbedarf • wirkt dem Problem zu kleiner (Gradienten) Änderungen bei Plateaus entgegen • wirkt dem Problem zu großer Gewichtsänderungen in steilen Schluchten entgegen 70 Modifikation und Varianten des Backpropagation
SuperSAB-Lernregel(super self-adaptive backpropagation)(MATLAB: traingdx) Prinzip: • selbstadaptiver BAP mit eigener Schrittweite (Lernrate) ij für jedes Gewicht • Schrittweite wird im Verlauf des Trainings kontinuierlich angepasst (adaptiert) • ij (t+1) = ij (t) + wird vergrößert, wenn E/ wij für zwei folgende Zeitschritte das gleiche Vorzeichen hat (mit Wachstumsfaktor + 1,05 (...1,20) und initialer Lernrate = 0,9) • ij (t+1) = ij (t) - wird verkleinert, wenn sich für E/ wij bei zwei folgenden Zeitschritten das Vorzeichen ändert (mit Schrumpfungsfaktor - 0,5 (...0,7)) • ij (t+1) = ij (t) bleibt konstant, wenn E/ wij = 0 in einem betrachten Zeitschritt (t+1) 70 Modifikation und Varianten des Backpropagation
Demo: Backpropagation mit adaptiver Schrittweite MATLAB 7.1/Demos/toolboxes/nn… Kapitel 12 Variable Learning Rate Backpropagation – Einfluss der Änderung der Lernrate, um das Fehlerminimum im Höhenprofil der Fehlerkurve (rotes Kreuz auf gelber Fläche) zu finden: >>nnd12vl (Starten Sie bei 12/-5, Initial Learning Rate 10) 70 Modifikation und Varianten des Backpropagation
SuperSAB-Lernregel: Bewertung • nicht alle großen Netze (> 100 Neuronen) erfüllen die Voraussetzung, dass Änderungen eines Gewichtes wij (t) unabhängig von Änderungen anderer Gewichte vorgenommen werden können • nur für Batch-Training stabiles Verhalten (Konvergenz) Bewertung: • wirkt Oszillationen und dem Verlassen von Minima entgegen (kleinere Lernrate, wenn sich das Vorzeichen der Steigung ändert) • wirkt dem Problem zu kleiner (Gradienten) Änderungen bei Plateaus entgegen (keine Reduktion der Schrittweite, wenn die Steigung 0 oder sehr klein ist) • Kombination mit Momentum-Term a möglich (a = 0,6 bis 0,9) 70 Modifikation und Varianten des Backpropagation
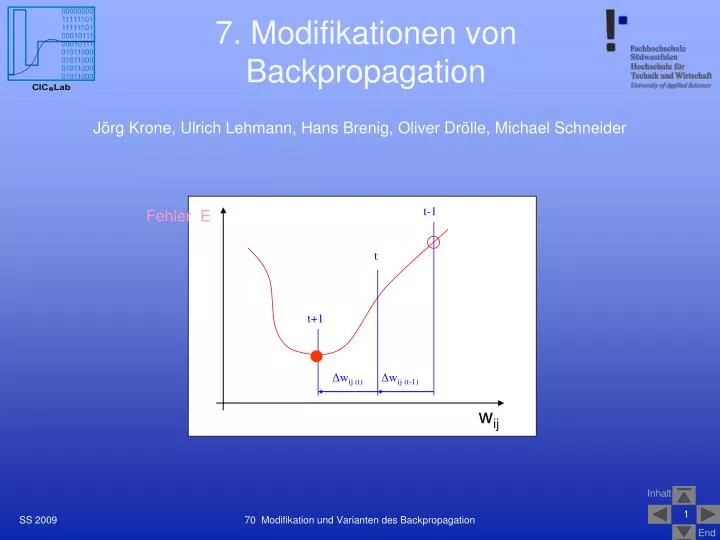
Lernverfahren Quickprop Prinzip • iteratives Offline-Verfahren (Batch) zweiter Ordnung zur Bestimmung des Minimums der Fehlerfunktion in Anlehnung (Näherung) an eine Parabelform für die Fehlerkurve E(wij) • die Parabel (blau) wird bestimmt durch die Ableitung der Fehlerfunktion zum Zeitpunkt t-1 sowie zum aktuellen Zeitpunkt t und dem AbstandDwij(t-1), dann kann der Scheitel der Parabel aus dem Verlauf der Ableitung berechnet werden 70 Modifikation und Varianten des Backpropagation
Quickprop: Approximation der Fehlerfunktion Die Parabel (blau) wird bestimmt durch die Ableitung der Fehlerfunktion zum Zeitpunkt t-1 sowie zum aktuellen Zeitpunkt t und dem AbstandDwij(t-1).Der Scheitel der Parabel (Nulldurchgang der Ableitung) kann aus dem Verlauf der Ableitung einfach anhand der ähnlichen grauen Dreiecke berechnet werden. 70 Modifikation und Varianten des Backpropagation
Quickprop: Gewichtsänderung zum Scheitel der Parabel • wegen der Ähnlichkeit der schraffierten Dreiecke in der vorhergehenden Grafik gilt: mit P(t) = wij (t) als Parabelterm • für den Fall, dass S(t) = S(t-1), kann der Nenner 0 und der Ausdruck für die Gewichtsänderung unendlich werden, daher muss die Schrittweite auf den max. Wachstumsfaktor mbegrenzt werden: • wij (t) <= mwij (t-1) mit m = 1,75 ... 2,25 70 Modifikation und Varianten des Backpropagation
Quickprop: Bestimmung der neuen Gewichte • bei Beginn des Offline-Lernverfahrens ist wij (t) = 0, deswegen wird mit dem Gradientenverfahren (Delta-Regel) mit Weight Decay (damit die Gewichte nicht zur groß werden und den Parabelterm übersteigen) gestartet: • wij (t) = popi pj-dwij (t-1) G(t): Gradiententerm • mit = 0...2 und d 0,0001 • die gesamte Gewichtsänderung setzt sich aus dem Gradiententerm G(t) und dem Parabelterm P(t) zusammen • wij gesamt (t) = G(t) + P(t) • mit G(t) größer zu Beginn des Trainings und 0 im lokalen Minima und P(t) = 0 zu Beginn des Trainings und max. im lokalen Minima 70 Modifikation und Varianten des Backpropagation
Quickprop:Bewertung • neigt im Online-Training wie SuperSAB zu Oszillationen (instabilem Verhalten) • Wirkung bei größeren KNN (> 100 Neuronen) wurden in einigen Anwendungen Oszillationen in lokalen Minima beobachtet! • Abhilfe: Offline-Training und (Lernrate) durch die Anzahl der eingehenden Gewichte einer Zelle teilen. Dadurch können größere Netze besser lernen! Bewertung: • schnelles Trainingsverfahren, wenn die Fehlerfunktion durch eine nach oben geöffnete Parabel approximiert werden kann und Änderungen eines Gewichtes wij (t) unabhängig von Änderungen anderer Gewichte vorgenommen werden können • das Minimum der Fehlerfunktion kann bei guter Approximation schon nach einem Lernschritt nahezu erreicht werden 70 Modifikation und Varianten des Backpropagation
Rprop: Resilient Propagagtion[elastische Fehler-Rückpropagation](MATLAB: trainrp) Prinzip: • basiert auf den Ideen von vorgestellten Verfahren: • Manhatten-Training: einfache Normierung der Gewichtsänderung (nur das Vorzeichen des Gradienten entscheidet nicht der Betrag) • SuperSAB: Anpassung bzw. Adaption der Lernrate an die Fehlerkurve (Wachstumsfaktor und Schrumpffaktor) • Quickprop: Verwendung der Steigung der Fehlerfunktion des aktuellen und vorherigen Zeitpunktes zur schnellen Bestimmung des Fehler-Minimums • kombiniert die Vorteile mehrerer Verfahren • ist ein Batch-Trainingsverfahren (offline) 70 Modifikation und Varianten des Backpropagation
Rprop (1+2) Berechnung von wij (t+1) = wij (t) + wij (t) mit: - ij(t) falls S(t-1) S(t) > 0 oder S(t) > 0 wij (t) = ij(t) falls S(t-1) S(t) > 0 oder S(t) < 0 - wij (t-1) falls S(t-1) S(t) < 0-sign(S(t)) ij(t) sonst Im folgenden werden der Betrag der Gewichtsänderung mit ij(t) und die Änderung des Gewichts wij (t) mit wij (t) bezeichnet und getrennt geändert. S(t) ist die Steigung der Fehlerkurve im Schritt t. ij(t-1) + falls S(t-1) S(t) > 0ij(t) = ij(t-1) - falls S(t-1) S(t) < 0ij(t-1) falls S(t-1) S(t) = 0 70 Modifikation und Varianten des Backpropagation
Rprop (3+4) Berechnung von wij (t+1) = wij (t) + wij (t) mit: - ij(t) falls S(t-1) S(t) > 0 oder S(t) > 0 wij (t) = ij(t) falls S(t-1) S(t) > 0 oder S(t) < 0 - wij (t-1) falls S(t-1) S(t) < 0-sign(S(t)) ij(t) sonst Im folgenden werden der Betrag der Gewichtsänderung mit ij(t) und die Änderung des Gewichts wij (t) mit wij (t) bezeichnet und getrennt geändert. S(t) ist die Steigung der Fehlerkurve im Schritt t.ij(t-1) + falls S(t-1) S(t) > 0ij(t) = ij(t-1) - falls S(t-1) S(t) < 0ij(t-1) falls S(t-1) S(t) = 0 70 Modifikation und Varianten des Backpropagation
Rprop: Parametereinstellung • bei fast allen Experimenten wurden bisher folgende Werte gewählt: • Wachstumsfaktor:+ = 1,2 mit W-Grenzwert:m= 1,75 ... 2,25 • Schrumpffaktor:- = 0,5 • zur Vermeidung von Gleitkommaüberlauf im Simulationsrechner werden meistens noch Schranken zur Beschränkung der Gewichtsänderung vorgegeben: • obere Schranke: max= 50 • untere Schranke: min= 1,0 * 10-6 (ein Mikro) • Initialisierungsgewichte ij(t=0) liegen etwa im Bereich: • 0= 1,0 bis 4,0 • ein Weight Decay-Term kann die Generalisierungsleistung von Rprop verbessern 70 Modifikation und Varianten des Backpropagation
Rprop: Bewertung • nur Batch-Training sinnvoll, da Online-Training noch instabiler als beim SuperSAB • Generalisierungsleistung kann schlechter sein als bei einem Netz, das mit Backpropagation trainiert wurde! • Abhilfe: Rprop mit Weight Decay-Term! Bewertung: • sehr schnelles Trainingsverfahren 70 Modifikation und Varianten des Backpropagation
Levenberg-Marquardt (LM)(MATLAB: trainlm) Prinzip: • basiert auf den Ideen von vorgestellten Verfahren: • Backpropagation-Training: Suche des Minimums der Fehlerfunktion in der Richtung des steilsten Abstiegs (Gradientenverfahren) • Quickprop: Verwendung der Steigung der Fehlerfunktion des aktuellen und vorherigen Zeitpunktes zur schnellen Bestimmung des Fehler-Minimums (nichtlineare Approximation durch Parabel) • kombiniert die Vorteile mehrerer Verfahren • ist ein Batch-Trainingsverfahren (offline) 70 Modifikation und Varianten des Backpropagation
Levenberg-Marquardt (LM) • Nichtlineare Approximation der Fehlerfunktion E = f (wij) durch LM am Beispiel einer Gaußkurve mit wenigen Stützpunkten: die Summe der Abstandsquadrate wird minimiert 70 Modifikation und Varianten des Backpropagation
Demo: Levenberg-Marquardt-Algorithmus MATLAB 7.1/Demos/toolboxes/nn… Kapitel 12 LM–Training: Kombination aus Gradientenabstieg und Newton-Verfahren zur Approximation der Fehlerfunktion. Bei geeigneten Parametern wird das Minimum des Fehlers (rotes Kreuz auf gelber Fläche) nach zwei Epochen gefunden: >>nnd12m (Starten Sie bei 12/-5, Initial Rate µ = 0.03 (Anteil des Gradientenverf.)) 70 Modifikation und Varianten des Backpropagation
LM: Initialisierung der Gewichte Unterschiedliche Initialisierungen des KNN mit gleichem Trainingsalgorithmus können erhebliche Unterschiede in der Lernkurve haben. 70 Modifikation und Varianten des Backpropagation
Levenberg-Marquardt: Bewertung • nur Batch-Training sinnvoll, da Online-Training instabil • Generalisierungsleistung kann schlechter sein als Backpropagation! • hoher Speicherbedarf = p • (w+) • Abhilfe: Validierung und Testdaten neben den Trainingsdaten verwenden und bei Verschlechterung des Testfehlers Abbruch des Trainings! Mehrere Initialisierungen testen (≥ 5); ggf. trainrp verwenden Bewertung: • sehr schnelles Trainingsverfahren • sehr genau↔geringe Fehler (Training und Validierung) bei guter Initialisierung erzielbar 70 Modifikation und Varianten des Backpropagation
Zusammenfassung I 70 Modifikation und Varianten des Backpropagation
Zusammenfassung II 70 Modifikation und Varianten des Backpropagation
MATLAB User's Guide Neural Network Toolbox • MATLAB Printable (PDF) Documentation on the Web • A. Zell: Simulation von neuronalen Netzen • VDE/VDI GMA FA 5.14 Computational Intelligencehttp://www.iai.fzk.de/medtech/biosignal/gma/tutorial/index.html • e-Simulation Levenberg-Marquardt-Algorithmus http://www.malerczyk.de/applets/Marquardt/Marquardt.html#iterationhttp://de.wikipedia.org/wiki/Newtonsches_N%C3%A4herungsverfahren • Levenberg-Marquardt-Algorithmushttp://www.crgraph.de/Levenberg.pdfhttp://www.versuchsmethoden.de/ Quellenverzeichnis 70 Modifikation und Varianten des Backpropagation
Fragen Fragen Sie bitte! 70 Modifikation und Varianten des Backpropagation
Danke Vielen Dank für Ihr Interesse! 70 Modifikation und Varianten des Backpropagation
Anlagen 70 Modifikation und Varianten des Backpropagation
Rprop (1 bis 4) 70 Modifikation und Varianten des Backpropagation
Danke Vielen Dank für Ihr Interesse! 70 Modifikation und Varianten des Backpropagation