Download
1 / 31
310 likes | 421 Vues
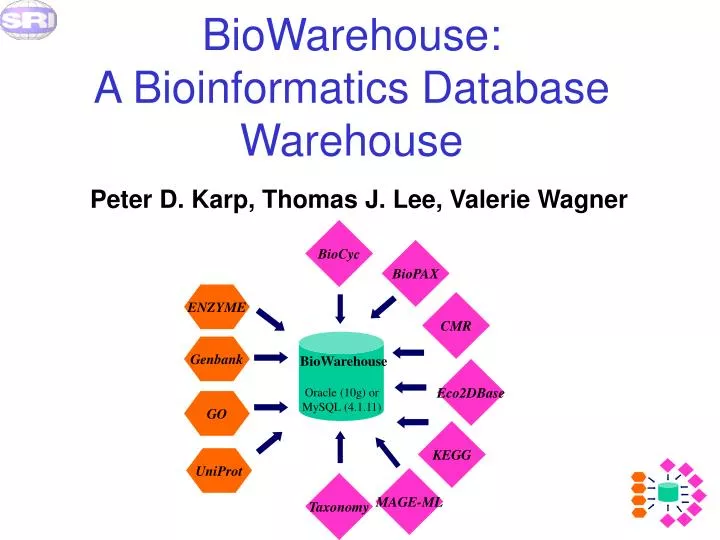
BioCyc. BioPAX. BioCyc. ENZYME. CMR. Genbank. BioWarehouse. Eco2DBase. Oracle (10g) or MySQL (4.1.11). UniProt. GO. Taxonomy. KEGG. UniProt. MAGE-ML. Taxonomy. BioWarehouse. ENZYME. CMR. Oracle or MySQL. = Java-based Loader. = C-based Loader. Genbank. KEGG.

E N D
BioCyc BioPAX BioCyc ENZYME CMR Genbank BioWarehouse Eco2DBase Oracle (10g) or MySQL (4.1.11) UniProt GO Taxonomy KEGG UniProt MAGE-ML Taxonomy BioWarehouse ENZYME CMR Oracle or MySQL = Java-based Loader = C-based Loader Genbank KEGG BioWarehouse: A Bioinformatics Database Warehouse Peter D. Karp, Thomas J. Lee, Valerie Wagner
Overview • Motivations for BioWarehouse • Facile programmatic access to individual DBs • Capture locally produced data • Database integration • BioWarehouse technical approach • Loaders • Schema overview • Applications of BioWarehouse • Join the BioWarehouse project
Motivations: Computing with Individual Databases • Most bioinformatics DBs are not queryable via a database management system • Via Internet or locally installable • Having relational database versions of individual bioinformatics DBs facilitates complex queries against individual DBs • What is the alternative? Perl scripts? Awkward to program, slow to execute
Motivations:Manage/Integrate Locally Produced Data • Need schema to capture locally produced data • Integrate locally produced data with public databases
Why is the Multidatabase Approach Alone Not Sufficient? • Multidatabase query approaches assume databases are in a queryable DBMS • Most sites that do operate DBMSs do not allow remote query access because of security and loading concerns • Users want to control data stability • Users want to control speed of their queries • Multidatabase query systems limited by Internet bandwidth and by the speed of the slowest data source that they query • Users need to capture, integrate and publish locally produced data of different types • Multidatabase and Warehouse approaches complementary
Key Challenges / Results for BioWarehouse • Design schema that accurately captures the contents of source DBs • Design schema that is understandable and scalable • Address poorly-specified syntax & semantics of source DBs • Balancing the preservation of source data with mapping into common semantics • Clearly document data mappings performed by loaders
Technical Approach • Multi-platform support: Oracle (10G) and MySQL • Schema support for multitude of bioinformatics datatypes • Create loaders for public bioinformatics DBs • Parse file format of the source DB • Some loaders parse interchange formats (BioPAX) • Semantic transformations • Insert DB contents into warehouse tables BMC Bioinformatics 7:170 2006 http://bioinformatics.ai.sri.com/biowarehouse/
Technical Approach • Provide Warehouse query access mechanisms • SQL queries via ODBC, JDBC, OAA • High quality documentation for schema and loader transformations • No graphical query interface yet
How to Use BioWarehouse? • Create your own local instance of BioWarehouse • Query an existing BioWarehouse instance, such as publichouse
PublicHouse Server • Publicly queryable BioWarehouse server operated by SRI • Manages a set of biological DBs constructed using BioWarehouse • CMR • BioCyc Pathway/Genome DBs • ENZYME • NCBI Taxonomy • Will be transitioning publichouse to contain • BioCyc • E. coli gene expression, proteomics, and ChIP-chip datasets • See: http://bioinformatics.ai.sri.com/biowarehouse/publichouse.html • Note publichouse will become a BioCyc/EcoliHub BioWarehouse server • Host: publichouse.sri.com • Port: 3306 • Database: biospice
BioWarehouse Schema • Manages many bioinformatics datatypes simultaneously • Pathways, Reactions, Chemicals • Proteins, Genes, Replicons • Sequences, Sequence Features • Gene expression data • Protein expression data • Flow cytometry data • Organisms, Taxonomic relationships • Computations (sequence matches) • Citations, Controlled vocabularies • Links to external databases • Each type of warehouse object implemented through one or more relational tables
BioWarehouse Schema • Manages multiple datasets simultaneously • Dataset = Single version of a database • Version comparison • Multiple software tools or experiments that require access to different versions • Each dataset is a warehouse entity • Every warehouse object is registered in a dataset
BioWarehouse Schema • Different databases storing the same biological datatypes are coerced into same warehouse tables • Design of most datatypes inspired by multiple databases • Representational tricks to decrease schema bloat • Single space of primary keys • Single set of satellite tables such as for synonyms, citations, comments, etc. • Schema size • Core schema: 70 tables • Gene expression schema: 109 tables
BioWarehouse Schema Overview • Schema manages many bioinformatics datatypes … including links to external databases • Main biological objects: • Each type of warehouse object implemented through one or more relational tables (70)
Pathway Data • BioCyc • KEGG • BioPAX format • Physical interaction data only • ENZYME • Populates these tables: Reaction, Protein, Chemical
Pathway Schema Neighborhood Pathway Product PathwayReaction Chemical Reaction Substrate EnzymaticReaction Protein
Pathway Data: BioCyc Loader • Each BioCyc DB can be loaded into separate BioWarehouse dataset, or one common dataset • Loads data from 13 BioCyc source files: • pubs.dat [not present for all BioCyc PDDBs] • compounds.dat • proteins.dat • protseq.fasta [not present for all BioCyc PGDBs] • transunits.dat [not present for all BioCyc PGDBs] • genes.dat • promoters.dat [not present for the MetaCyc PGDB] • terminators.dat [not present for the MetaCyc PGDB] • dnabindsites.dat [not present for the MetaCyc PGDB] • reactions.dat • enzrxns.dat • regulation.dat • pathways.dat • http://biowarehouse.ai.sri.com/repos/biocyc-loader/flatfile/doc/index.html
Comparative Analysis with BioWarehouse:Compare MetaCyc to KEGG • KEGG pathways are larger than MetaCyc pathways • MetaCyc has a larger number of pathways • Which database has a larger collection of pathway data? • Prior result: KEGG pathways are on average 4.2 times larger than MetaCyc pathways “The outcomes of pathway database computations depend on pathway ontology” Green and Karp, Nucleic Acids Research 2006:34 3687-97
MetaCyc contains 1.4 times as many reactions within its pathways as does KEGG
Gene Expression Data inBioWarehouse • Goals • Experimentalist loads locally produced data into BioWarehouse • Computational biologist loads remotely downloaded data into BioWarehouse • For processing and/or integration with other data • Source data format: MAGE-ML • http://mged.org/ • BioWarehouse and ArrayExpress are only MAGE-ML compliant data models we could find
Our Approach • Translate MAGE-OM into a relational database schema • One class One table gives too large a schema (ArrayExpress) • Instead, one table per inheritance hierarchy – reduces table count by half • Use MAGE SDK tool for XML->Object; use Castor for Object->Relational mapping • Merge the resulting schema into BioWarehouse schema to eliminate redundancy • Result: 109 tables
ChIP-Chip Data • Current project to extend MAGE-ML loader and BioWarehouse to accommodate ChIP-chip data • Meta data, gene expression data, transcription factor(s), antibody(s)
Protein Interactions Data • Schema support • Load via BioPAX
Contribute to BioWarehouse • Open Source project • Ways to contribute: • Maintain/update an existing loader • Implement a new loader • Port to new compiler or platform or DBMS support@biowarehouse.org
Acknowledgments • Funded by • NIH/NIGMS EcoliHub project • NIH/NIGMS BioCyc project • DARPA Bio-SPICE program SRI Colleagues • Valerie Wagner, Tom Lee, Tomer Altman Learn more • http://bioinformatics.ai.sri.com/biowarehouse/ • BMC Bioinformatics 7:170 2006






















