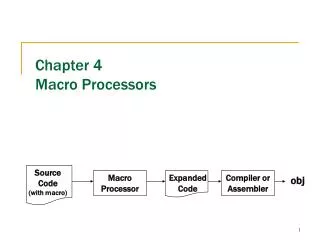
Download
1 / 1
10 likes | 112 Vues
Anshuman Gupta and Michael Bedford Taylor CSE Department, University of California at San Diego. The Details. Overview. Dynamically Partitioned Manycore Architecture. Online Performance Estimation ( pTables ). Higher-Order Decisions.

E N D
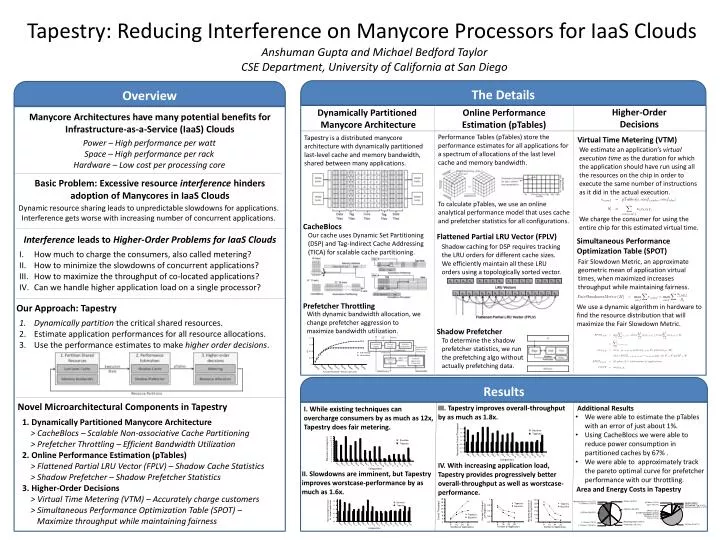
Anshuman Guptaand Michael Bedford Taylor CSE Department, University of California at San Diego The Details Overview Dynamically Partitioned Manycore Architecture Online Performance Estimation (pTables) Higher-Order Decisions Manycore Architectures have many potential benefits for Infrastructure-as-a-Service (IaaS) Clouds Performance Tables (pTables) store the performance estimates for all applications for a spectrum of allocations of the last level cache and memory bandwidth. Tapestry is a distributed manycore architecture with dynamically partitioned last-level cache and memory bandwidth, shared between many applications. Virtual Time Metering (VTM) Power – High performance per watt Space – High performance per rack Hardware – Low cost per processing core We estimate an application’s virtual execution time as the duration for which the application should have run using all the resources on the chip in order to execute the same number of instructions as it did in the actual execution. Tapestry: Reducing Interference on Manycore Processors for IaaS Clouds Basic Problem: Excessive resource interference hinders adoption ofManycores in IaaS Clouds To calculate pTables, we use an online analytical performance model that uses cache and prefetcher statistics for all configurations. Dynamic resource sharing leads to unpredictable slowdowns for applications. Interference gets worse with increasing number of concurrent applications. We charge the consumer for using the entire chip for this estimated virtual time. CacheBlocs Our cache uses Dynamic Set Partitioning (DSP) and Tag-Indirect Cache Addressing (TICA) for scalable cache partitioning. Flattened Partial LRU Vector (FPLV) Interference leads to Higher-Order Problems for IaaS Clouds Simultaneous Performance Optimization Table (SPOT) Shadow caching for DSP requires tracking the LRU orders for different cache sizes. We efficiently maintain all these LRU orders using a topologically sorted vector. How much to charge the consumers, also called metering? How to minimize the slowdowns of concurrent applications? How to maximize the throughput of co-located applications? Can we handle higher application load on a single processor? Fair Slowdown Metric, an approximate geometric mean of application virtual times, when maximized increases throughput while maintaining fairness. Prefetcher Throttling Our Approach: Tapestry We use a dynamic algorithm in hardware to find the resource distribution that will maximize the Fair Slowdown Metric. With dynamic bandwidth allocation, we change prefetcher aggression to maximize bandwidth utilization. Dynamically partition the critical shared resources. Estimate application performances for all resource allocations. Use the performance estimates to make higher order decisions. Shadow Prefetcher To determine the shadow prefetcher statistics, we run the prefetching algo without actually prefetching data. Results III. Tapestry improves overall-throughput by as much as 1.8x. Additional Results Novel Microarchitectural Components in Tapestry I. While existing techniques can overcharge consumers by as much as 12x, Tapestry does fair metering. • We were able to estimate the pTables with an error of just about 1%. • Using CacheBlocs we were able to reduce power consumption in partitioned caches by 67% . • We were able to approximately track the pareto optimal curve for prefetcher performance with our throttling. 1. Dynamically Partitioned Manycore Architecture > CacheBlocs – Scalable Non-associative Cache Partitioning > Prefetcher Throttling – Efficient Bandwidth Utilization 2. Online Performance Estimation (pTables) > Flattened Partial LRU Vector (FPLV) – Shadow Cache Statistics > Shadow Prefetcher – Shadow Prefetcher Statistics 3. Higher-Order Decisions > Virtual Time Metering (VTM) – Accurately charge customers > Simultaneous Performance Optimization Table (SPOT) – Maximize throughput while maintaining fairness IV. With increasing application load, Tapestry provides progressively better overall-throughput as well as worstcase-performance. II. Slowdowns are imminent, but Tapestry improves worstcase-performance by as much as 1.6x. Area and Energy Costs in Tapestry












![G4 - AMATEUR RADIO PRACTICES [5 Questions - 5 groups]](https://cdn2.slideserve.com/4617737/g4-amateur-radio-practices-5-questions-5-groups-dt.jpg)


![T1A04 (C) [97.3(a)(23)] Which of the following meets the FCC definition of harmful interference?](https://cdn2.slideserve.com/5148982/slide1-dt.jpg)