Download
1 / 17
220 likes | 912 Vues
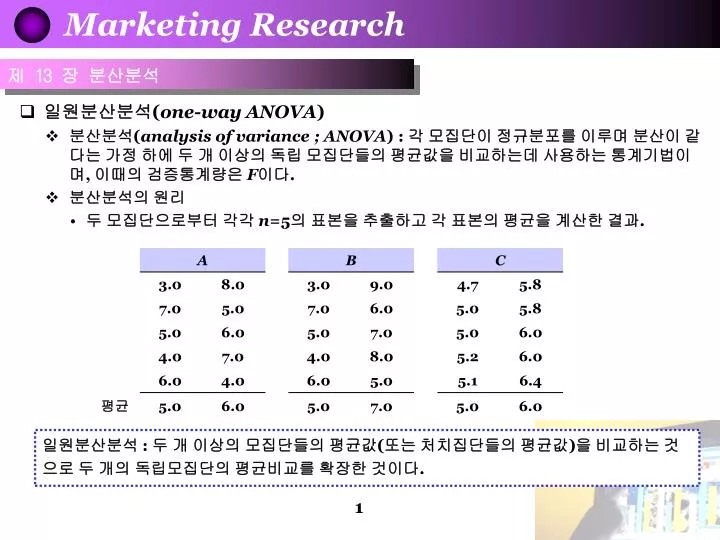
일원분산분석 ( one-way ANOVA ) 분산분석 ( analysis of variance ; ANOVA ) : 각 모집단이 정규분포를 이루며 분산이 같다는 가정 하에 두 개 이상의 독립 모집단들의 평균값을 비교하는데 사용하는 통계기법이며 , 이때의 검증통계량은 F 이다 . 분산분석의 원리 두 모집단으로부터 각각 n =5 의 표본을 추출하고 각 표본의 평균을 계산한 결과. 제 13 장 분산분석.

E N D
일원분산분석(one-way ANOVA) • 분산분석(analysis of variance ; ANOVA) : 각 모집단이 정규분포를 이루며 분산이 같다는 가정 하에 두 개 이상의 독립 모집단들의 평균값을 비교하는데 사용하는 통계기법이며, 이때의 검증통계량은 F이다. • 분산분석의 원리 • 두 모집단으로부터 각각 n=5의 표본을 추출하고 각 표본의 평균을 계산한 결과. 제 13 장 분산분석 일원분산분석 : 두 개 이상의 모집단들의 평균값(또는 처치집단들의 평균값)을 비교하는 것으로 두 개의 독립모집단의 평균비교를 확장한 것이다.
A와 B를 비교하면, A에 비해 B의 경우 두 모집단의 평균차이가 있을 가능성이 높다. 왜냐하면 A에 비해 B의 경우 두 평균값들의 분산이 더 크기 때문이다. • A와 C를 비교하면, A에 비해 C의 경우 두 모집단의 평균차이가 있을 가능성이 높다. 왜냐하면 A에 비해 C의 경우 각 집단내의 분산이 더 작기 때문이다. • 요약 : 두 개 이상의 모집단으로부터 표본을 추출한 경우 표본평균값 간의 차이가 클수록(집단간 분산이 클수록) 그리고 각 표본의 요소들 간의 차이가 작을수록(집단 내 분산이 작을수록) 모집단의 평균값에는 차이가 있을 가능성이 높다. → 분산분석은 이러한 논리에 바탕을 두고 분산값들을 분석함으로써 모집단 평균의 차이를 검증하는 통계기법. • 분산분석의 절차 • 자연모집단들의 평균간에 차이가 있는 가를 보는 것(예를 들어 신입생들의 수능시험 평균성적이 세 대학교간에 차이가 있는가 ?)이지만, 어떤 실험변수에 여러 수준의 처치를 가하고 그 결과가 다르게 나타나는지를 보는데도 자주 사용됨. • 교육방법/ A, B / 판매실적 • n개의 실험대상을 무작위로 k개의 집단으로 나누고 각각의 집단에 처치를 가하여 실험대상으로부터 처치에 따른 결과 값을 추정(각 집단의 크기 n1, n2, …, nk). 무작위화 결과변수 처치변수(treatment variable) 처치수준(treatment level)
분산분석을 위한 기본자료의 배열 • 전체 제곱합(total variance ; total sum of squares ; Total SS)
집단간 제곱합(between variance ; sum of squares due to treatment ; SST) • 집단내 제곱합(within variance ; sum of squares due to error ; SSE) • 전체 제곱합(Total SS) = 집단간 제곱합(SST) + 집단내 제곱합(SSE) • SST와 SSE를 각각의 자유도로 나누면 MST와 MSE를 얻게 되며 이로부터 검증통계량 F값을 계산할 수 있다.
k개 모집단 평균값들(혹은 k개 처치집단 평균값들)간에 차이가 있는지를 조사하기 위한 가설설정과 검증절차. • H0 : μ1=μ2=…=μk H1 : 모든 μ가 동일하지는 않다. 즉 최소한 어떤 두 개의 평균값들간에는 차이가 있다. • Fobs계산 : • F-table에서 Fcrit값을 찾는다 : Fcrit = F(α; k-1, n-k) (여기서 k-1과 n-k는 각각 집단간 및 집단내 분산의 자유도이다.) • 기각역은 Fcrit값의 우측에 위치한다. 따라서 Fobs ≥ Fcrit이면 H0는 기각되고 Fobs< Fcrit이면 Ho는 기각되지 않는다. • 분산분석의 예 : A잡지회사의 영업부에서는 영업사원 교육을 위한 네 가지 교육프로그램의 효과에 차이가 있는지를 조사하기 위하여 실험을 실시하였다. 이 실험에서 28명의 신입사원들을 무작위로 네 집단으로 나누어 교육프로그램 A, B, C, D로써 교육을 실시하였다. 교육도중 5명이 탈락하고 교육을 마친 후 1주일간의 장기구독 판매실적은 다음의 표와 같다. 여기서 신입사원들을 무작위로 네 집단으로 나누었으므로 각 집단에 속한 사원들의 교육이전 판매능력은 동일한 것으로 가정된다. 이러한 자료로써 교육프로그램에 따라 판매실적이 다르다고 할 수 있는가 (α=.05)?
가설검증 • Ho : μ1=μ2=μ3=μ4 H1 : 모든 μ가 동일하지는 않다(즉, 어떤 집단의 평균값은 다른 집단의 평균값과 다르다). • F-test를 한다. • Fobs계산을 위하여 분산분석표를 작성한다. 먼저, 각 집단의 평균값과 전체 평균값을 계산하면,
Fobs = 3.77 3.13 .05 • Fcrit =F(α;k-1, n-k) = F(.05 ; 3, 19) = 3.13 • F = 3.13보다 우측이 기각영역이 되면 Fobs = 3.77은 기각역에 위치하므로 H0는 기각된다. 따라서 모든 교육프로그램효과가 동일하지는 않다. 즉, 최소한 어느 두 가지 프로그램간에는 그 효과가 다르다고 결론지을 수 있다. C, D가 기각하는데 있어 가장 많이 공헌(contribution)
p-value 3.77 • 분산분석의 추가 이슈들 • 추가 1 : p-value를 이용한 가설검증 → “p-value/자유도(3, 19)의 F분포”는 다음 영역임. • 추가 2 : 사후다중비교 ; 분산분석결과 네 집단 중 적어도 어느 두 집단간에는 평균차이가 있다고 결론 내렸다. 그러면 6개의 두 집단 비교 중 어느 두 집단에서 차이가 있는가 (4C2 = 6) ? 이를 위하여 사후다중비교(post hoc multiple comparisons)를 할 수 있다. • F(.05 ; 3, 19) = 3.19 / F(.025 ; 3, 19) = 3.90 • 3.77은 3.13와 3.19 사이에 위치하므로 .025<p-value<.05라고 할 수 있다. p-value<α=.05보다 작으므로 H0는 역시 기각된다.
추가 3 : 분산분석에 의한 두 집단 평균의 비교 – 일반적으로 두 집단의 평균차이검증을 위해서는 t-test를 사용하지만 분산분석에 의한 F-test에 의해서도 물론 가능하다. 12장의 판매사원 교육프로그램 예를 통해 분산분석에 의한 가설검증을 하면, 귀무가설과 대립가설은 t-test의 경우와 같다. 분산분석결과 Fobs=2.70으로 나타나며, Fcrit = F(.05 ; 2-1, 18-2) = 4.49로서 H0는 기각되지 않는다. • (tobs)2 = (1.64)2 = 2.70 = Fobs • (tcrit)2 = (2.12)2 = 4.49 = Fcrit로 나타남을 알 수 있다. 이와 같이 두 모집단 평균차이검증을 위하여 F-test를 하더라도 t-test결과와 같다. 그러나 t-test가 보다 간편하므로 흔히 t-test를 사용한다.
분산분석(무작위 블럭디자인 ; paired-difference test) • 마케팅 관리자가 패키지 디자인으로 두 가지가 아닌 세 가지를 비교하고자 하는 경우, 선정된 수퍼마켓을 세 집단을 나누어 각 집단의 수퍼마켓에 A, B, C중 한 가지 패키지 디자인의 비누를 진열하여 매출을 비교한다면 수퍼마켓의 크기, 내점고객수, 그 지역의 소득, 경쟁상황 등 여러 가지 요인들이 매출에 영향을 줄 수 있다(외생변수). 그러므로 무작위 블럭디자인(randomized block design)을 통해서 실험을 해야 한다. 이 실험에서 4개의 수퍼마켓을 선정하여 각 수퍼마켓에 세 가지 디자인의 비누를 모두 진열하였다. 그 결과 각 수퍼마켓에서 패키지 디자인별로 다음과 같이 매출이 실현되었다. 이 경우 각 수퍼마켓의 조건이 세 가지 디자인의 비누판매에 공통적으로 영향을 미치며, 이와 같은 변수를 블럭(block)변수라고 한다. 이 자료로부터 패키지 디자인에 따라 매출이 다르다고 할 수 있는가 ? 한 처치변수의 수준(treatment level)에 따라 결과변수의 값이 달라지는가를 조사할 때 외생변수로 작용할 수 있는 변수를 통제하기 위하여 블럭변수로 처리한 것으로 엄격히 말해 한 개의 처치변수의 효과를 조사하는 것.
가설검증 • H0 : μ1=μ2=μ3, H1 : 모든 μ가 동일하지는 않다. • F-test를 한다. • 분산분석표를 작성하여 Fobs를 구한다. b : 블럭의 수 t : 처치의 수 주관심대상
관심의 대상 : 패키지 디자인에 따라 매출이 다른가에 관한 것이므로 Fobs(처치)=36.09를 다음의 Fcrit과 비교한다(α=.05) Fcrit = F(α; t-1, (b-1)(t-1)) = F(.05 ; 2, 6) = 5.14 • Fobs> Fcrit이므로 H0는 기각되며, α=.05에서 패키지 디자인에 따라 매출이 달라질 수 있다는 결론을 내릴 수 있다. 또한 F(.005 ; 2, 6)= 14.54이므로 p-value<.005이고 따라서 H0는 α=.005에서도 기각된다(자유도가 커질수록 F값은 작아지는 경향이 있다). • 추가적으로 원래 관심의 대상은 아니지만 슈퍼마켓간에 매출이 동일하다(μ1=μ2=μ3=μ4)는 귀무가설을 생각할 수 있는데 , • H0 : μ1=μ2=μ3=μ4 , H1 : 모든 μ가 동일하지는 않다. • Fobs = 15.30, Fcrit = F(α ; b-1, (b-1)(t-1)) = F(.05; 3, 6) = 4.76 • Fobs> Fcrit이므로 H0는 기각되며, α=.05에서 비누매출이 동일하지는 않다는 결론을 내릴 수 있다. 또한 F(.005 ; 3, 6)= 112.92이므로 p-value<.005이고 따라서 H0는 α=.005에서도 기각된다.
태도 태도 탄산화 단맛 저 고 고 저 • 이원분산분석(factorial design) : 2개 이상의 독립처치변수의 수준변화에 따른 결과변수값의 변화를 조사하기 위한 실험디자인으로 이때 각 처치변수를 factor라고 부른다(factor A의 처치수준 a, factor B의 처치수준 b일 때 이 실험디자인을 a×b factorial design이라 부르며 처치변수가 2개이므로 처치효과(treatment effect)를 조사하기 위하여 이원분산분석(two-way ANOVA)을 적용) . • 이원분산분석 결과 : 처치효과로서 주효과와 상호작용효과. • 주효과(main effect) : 한 처치변수의 변화가 결과변수에 미치는 영향에 관한 것. • 상호작용효과(interaction effect) : 다른 처치변수의 변화에 따라 한 처치변수가 결과변수에 미치는 영향에 관한 것. • 예 : 탄산화 정도와 단맛정도가 청량음료태도에 미치는 영향을 알기 위한 실험으로 각 처치변수의 수준을 고·저로 하는 경우 이 실험디자인은 2×2 factorial design이 된다. • 두 처치변수의 주 효과 탄산화의 정도가 높을수록 태도가 호의적이며 단맛 정도가 높을수록 태도가 비호의적인 것으로 추정.
고탄산화 태도 태도 고탄산화 저탄산화 저탄산화 단맛 단맛 저 고 고 저 • 두 가지 처치변수의 상호작용효과 다른 처치변수의 변화에 따라 한 처치변수가 결과변수에 미치는 영향에 관한 것. 저탄산화에 비해 고탄산화 경우 태도가 호의적이며 이러한 경향은 단 맛의 고·저에 관계없이 동일하게 나타난다 : 상호작용효과는 없다고 할 수 있다. 저탄산화에 비해 고탄산화의 경우 태도가 호의적(저단맛의 경우 : 탄산화의 정도에 따라 태도가 크게 다르지 않음; 고단맛의 경우 : 저탄산에 비해 고탄산의 경우 태도가 호의적 : 상호작용효과가 있는 것으로 추정.
팩토리얼 디자인에 의한 이원분산분석의 예 : 저관여 신제품의 경우 소비자의 광고에 대한태도는 브랜드태도에 상당한 영향을 미칠 수 있다. 신제품 광고로서 세 가지 광고대안을 개발하였으며 피실험자들에게 노출시킨 후 광고태도를 측정하여 소비자들이 좋아하는 광고를 선택하고자 한다. 마케터는 이러한 광고대안들에 대한 태도가 남녀간에 다를지도 모른다고 생각하고 남·녀 중 어느 집단이 어떤 광고를 더 좋아하는지 알기를 원했다 남·녀 각각 9명의 피실험자들을 다음과 같이 6개의 cells에 할당하고 각 피실험자에게 세 가지 광고 중 하나를 보여주었다. 피실험자들은 광고태도를 0 ~ 5.0(간격 0.1)의 척도상에 표시하였다. 그 결과는 다음과 같다. 이때, 세 가지의 연구문제를 생각할 수 있다. • 광고대안에 따라 광고태도가 다른가(α=.05) ? • 성별에 따라 광고태도가 다른가(α=.05) ? • 성별과 광고대안 간에는 상호작용효과가 있는가(α=.05) ?
< 가설검증 > • H0 : μ1=μ2=μ3, H1 : 모든 μ가 동일하지는 않다. H0 : μ남=μ여, H1 : μ남≠μ여 H0 : 상호작용효과가 없다. H1 : 상호작용효과가 있다. • 2×3 factorial design에 의한 이원분산분석(세 개의 F-검증) • cell별로 평균을 계산하면…
광고 태도 1 2 3 4 남 여 광고 123 • 연구가설별로 F-table에서 Fcrit를 찾는다. • 이원분산분석의 경우 보통 상호작용과정을 먼저 조사. • 상호작용효과가 유의적 : 전체 패턴을 주의 깊게 해석(주효과를 추가적으로 조사하지만, 의미는 크지 않다.) • 상호작용효과가 비유의적 : 주효과를 조사하고 유의적이면 이에 따라 해석. • 상호작용효과에 대한 검증 : Fobs = 1.34 < Fcrit = F(.05 : 2, 12) = 3.89 ∴ 상호작용효과는 유의적이지 않음. • 광고대안(A)의 주효과에 대한 검증 : Fobs = 21.81 > Fcrit = F(.05 : 2, 12) = 3.89 ∴ 광고대안(A)의 주효과는 유의적. • 성별(B)의 주효과에 대한 검증 : Fobs = 100.28 > Fcrit = F(.05 : 1, 12) = 4.75 ∴ 성별(B)의 주효과는 유의적. 남녀 모두 광고 1을 광고 2보다 선호하는 경향이 있으며, 전체적으로 남자가 여자보다 실험용 광고에 대한 태도가 호의적 이며, 성별에 따라 특정 광고를 선호하는 경향이 다르지 않다 (6개 평균태도점수 간의 차이가 통계적 유의성이 있는지 알기 위해 사후다중비교를 실시해야 함). Comment : 남자가 여자보다 실험광고를 선호하며, 광고1을 세 개 중 가장 선호하는 것으로 추정.