Download

1 / 26
310 likes | 506 Vues
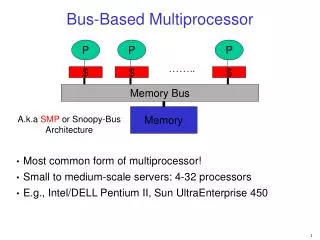
More Architectural Support for MIMD. Snoop-based multiprocessor design. Correctness issues semantic model: coherence and memory consistency dead-lock, live-lock, and starvation Design issues simplistic-to-realistic one-by-one: Single-level cache and an atomic bus

E N D
More Architectural Support for MIMD Snoop-based multiprocessor design • Correctness issues • semantic model: coherence and memory consistency • dead-lock, live-lock, and starvation • Design issues simplistic-to-realistic one-by-one: • Single-level cache and an atomic bus • Multi-level cache design issues • Split-transaction bus design issues • Scalable snoop-based design techniques PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Key goals • Correctness • Design simplicity (verification is costly) • High performance Design simplicity and performance are often at odds Get picture of bus-based coherence organization, dual tags, proc-side and bus-side controllers PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Correctness Requirements • Semantic model: contract between HW/SW • cache coherence -> write serialization • sequential consistency -> prog. order, write atomicity • Deadlock: no forward progress and no system activity • resources being held in a cyclic relationship • Livelock: no forward progress but system activity • allocation/de-allocation of resources with no progress • Starvation: some processes are denied service • often temporary PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Single-Level Cache and Atomic Bus Single-level caches and an atomic bus • Tag and cache controller designissues • Snoop protocol design • Race conditions: non-atomic state transitions • Correctness issues • serialization • deadlock, livelock, and starvation • Atomic (synchronization) operations PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
bus requests Performance issue: Simultaneous tag accesses from processor and bus Solution: Duplicate tags but keep them consistent Cached data Tags Tags Processor requests Cache Controller Design Recall actions on a cache access: 1. Indexing cache with tag check 2. Get/request data 3. Update state bits Extension for snoop support: bus requests also access cache • processor-side controller • bus-side controller PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Reporting Snoop Results Where to read (memory or cache) and what state transition to make? • support wired-and/or bus lines When is the snoop result available? (main alternatives) • synchronous: requires dual tags and must adapt to worst-case because of updates of state bits caused by processor • asynchronous (variable delay snoop):assume minimum delay but add enough cycles if necessary • memory state bit to distinguish between valid/invalid memory block PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Dealing with Write-backs One would like to service miss before writing back the replaced block Two implications: • Add a write-back buffer • Bus snoops must also look into write-back buffer PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Baseline Architecture Write-back buffer PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
State Transitions Must Appear Atomic Assume a block is in shared state in both caches 4. Upgrade from cache 1 is performed. However, Upgrade is not appropriate 2. Cache 2 gets access to bus 1. Await use of bus Upgr Upgr Cache 1 3. Upgrade from Cache 2 updates state of Cache 1 to invalid Cache 2 PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Non-Atomic State Transitions Time window between issuing and performing of a bus operation • Problem: another transaction may change action • Solution: extend with non-atomic state PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Correctness Issues • Write serialization: ownership acquisition and cache block modification should appear atomic • processor may not write data into cache until read-exclusive request is on bus; it is committed • Deadlock: Two cache controllers may be in a circular dependence relation if one is locking the cache while waiting for the bus (fetch deadlock) • Livelock: If several controllers issue read-exclusive requests for same block at the same time • Let each one complete before taking care of next • Starvation: Bus arbitration is unfair to some nodes PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
A Fetch-Deadlock Situation 3. Cache 2 waits for Cache 1 to respond and Cache 1 waits for Cache 2 to release the bus Deadlock! 2. Cache 2 gets access to bus 1. Await use of bus, but Cache 1 is locked ReadX B BusRd A Cache 1 B Cache 2 A PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
A Livelock Situation • A read exclusive operation involves: • Acquisition of an exclusive block • Reattempting the write in the local cache 2. Make cache 1’s copy invalid 1. Try to get bus ReadX A ReadX A Cache 1 3. Make Cache 2’s copy invalid Etc……Livelock! Cache 2 PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Remedies to Correctness Issues • Do not update cache until Upgrade is on bus • Service incoming snoops while waiting for bus • Complete the transaction with no interruption Upgr Upgr Cache 1 Cache 2 PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Implementation of Atomic Memory Operations Test&set should result in atomic read-modify-write • Cacheable t&s vs memory-based implementation • lower latency & bw for spinning and self-acquisition • longer time to transfer lock to other node • memory-based requires bus to be locked down • Load-linked (LL) and store-conditional (SC) implementation • Lock flag and lock address register at each processor • LL reads block, sets lock flag, puts block address in reg • Incoming invalidates checked against address: if match, reset flag • SC checks lock flag as indicator of intervening conflicting write: if reset, fail; if not, succeed PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
P L2 L1 M Multi-Level Cache Designs • Coherence needs to be extended across L1 and L2 • L1 on-chip. Snoop support in L1 expensive Is snoop support needed in L1? Definition: L1 included in L2 iff all blocks in L1 also in L2 If inclusion maintained then snoop support only needed at L2 (must be able to invalidate blocks in L1) Consequence: a block in owned state in L1 (M in MSI) must be marked modified in L2 PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Maintaining Inclusion Violations to the inclusion property: • Set-associative L1 with history-based replacement algorithm • Split I- and D-caches at L1 and unified at L2 • Different cache block sizes in L1 and L2 Techniques to maintain inclusion: Direct-mapped L1 and L2 with any associativity given some additional constraints for block size, fetch policy, … Note: One can always displace a block in L1 on replacement in L2 to maintain inclusion PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Mem Access Delay Mem Access Delay Separate request-response phases improve bus utilization Data Data Address/CMD Address/CMD Address/CMD Bus arbitration Split Transaction Buses Challenging issues: • Avoid conflicting requests in progress simultaneously • Buffers needed => flow control • Correctness issues (coherence, SC, deadlock, livelock,...) PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Example of Conflict Situation • With atomic bus, Upgrade is committed when bus is granted • Here, two Upgrades can be on bus and may invalidate both copies Upgr Upgr Cache 1 Cache 2 PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Some real examples • Details can be interesting • Supports historical emphasis of the course • SGI Power Challenge PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
SGI Challenge 1(4) High-level design decisions • Avoid conflicts: Allow a fixed number of requests to different blocks in progress at a time • Flow-control: Limited buffers, so NACK when full and retry • Ordering: Allow out-of-order responses (to cope with non-uniform delays) PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
SGI Challenge 2(4) • Separate request-response buses • Request phase: (use address request bus) • present the address and initiate snooping • report snoop result (prolong or nack if necessary) • Response phase: (use data request bus) • send data back PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Design of SGI Challenge 3(4) • Max 8 outstand. requests • 3-bit tag to separate req. • Request table in each node to keep track of outstanding requests • Writes are committed when request is granted • Flow control: NACK and retry when buffers are full Conflict resolution • Before address request is done, request table is checked • Memory and caches check request independently PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Serialization and SC 4(4) • Serialization to a single locationguaranteed • 1. Only a single request to each block allowed • 2. Request committed when request on bus • Problems to guarantee SC: • requires serialization across writes to different locations • requests can be reordered in buffers so being committed is not same as performed • A solution: • Servicing incoming requests before processor’s own requests guarantees write atomicity PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
Multiple Outstanding Processor Requests Modern processors allow multiple outstanding memory operations • Problem: may violate sequential consistency • Solution: • Buffer all outstanding requests • Don’t make writes visible to any until committed • Don’t perform reads before previously issued requests are committed • Lockup-free caches implement the buffering capability to enforce ordering of uncommitted memory operations PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011
SGI Challenge: 36 MIPS R8000 processors with a 1.2 GB/s bus Peak: 5.4 GFLOPS • Sun Enterprise 6000: 30 UltraSparc processors with 2.67 GB/s bus Peak: 9 GFLOPS Commercial Machines Look these up on the net PCOD: MIMD II Lecture (Coherence) Per Stenström (c) 2008, Sally A. McKee (c) 2011