Download

1 / 16
170 likes | 593 Vues
DATA MINING: DEFINITIONS AND DECISION TREE EXAMPLES. Emily Thomas Director of Planning and Institutional Research. WHAT IS DATA MINING?. Data mining is the discovery of hidden knowledge, unexpected patterns and new rules in large databases.

E N D
DATA MINING: DEFINITIONS AND DECISION TREE EXAMPLES Emily Thomas Director of Planning and Institutional Research
WHAT IS DATA MINING? • Data mining is the discovery of hidden knowledge, unexpected patterns and new rules in large databases. • Data mining is exploratory. The results lack the protection from spurious conclusions that validates theory-based hypothesis-driven statistics.
WHY USE DATA MINING? In the corporate world: • Large amounts of data are captured in enterprise data bases. • These databases are too large for traditional statistical techniques. • Identifying patterns in the data can target profitable, or unprofitable, customers.
WHY USE DATA MINING? In institutional research: • Large numbers of variables • We have insufficient time/resources to investigate all the relationships that might be informative. • Identifying data patterns can shed light on student behavior.
WHY DATA MINING NOW? • Development of large, integrated enterprise databases • Development of data mining techniques and software • Development of simplified user interface
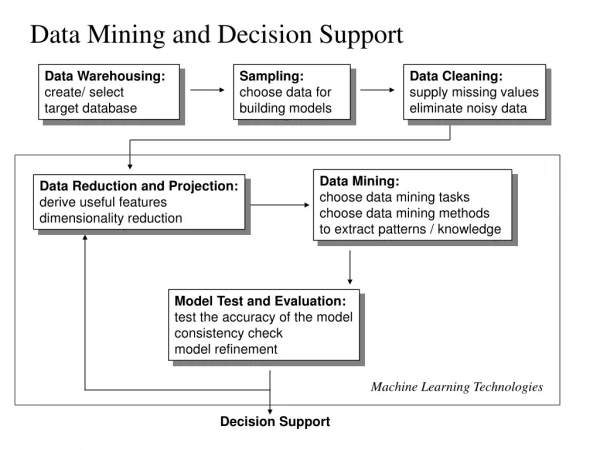
Decision trees Rule induction Nearest neighbors Neural networks Clustering Genetic algorithms Exploratory factor analysis Stepwise regression DATA MINING TECHNIQUES
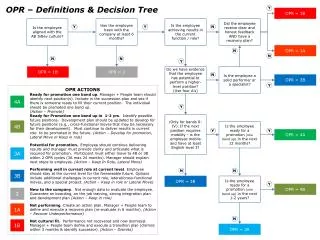
DECISION TREE ANALYSIS CHAID: Chi-squared Automatic Interaction Detector (SPSS Answer Tree) • Select significant independent variables • Identify category groupings or interval breaks to create groups most different with respect to the dependent variable • Select as the primary independent variable the one identifying groups with the most different values of the dependent variable • Select additional variables to extend each branch if there are further significant differences
TRANSFER RETENTION RATES Percent of new full-time Fall 2002 transfers returning in Spring 2003
TRANSFER RETENTION RATES FALL 2002-SPRING 2003
VERY LARGE INTELLECTUAL GROWTH 19% of students
LARGE INTELLECTUAL GROWTH 41% of students
LOW OR MODERATE INTELLECTUAL GROWTH 40% of students
SOS 2000: SATISFACTION WITH “THIS COLLEGE IN GENERAL”
DECISION TREEADVANTAGES AND DISADVANTAGES • Discover unexpected relationships • Identify subgroup differences • Use categorical or continuous data • Accommodate missing data • Possibly spurious relationships • Presentation difficulties
BIBLIOGRAPHY • AnswerTree 2.0: User’s Guide. SPSS, 1998. • Adriaans, P and D Zantinge (1996). Data Mining. Harlow, England and elsewhere: Addison-Wesley. • Bordon, VMH (1995). Segmenting Student Markets with a Student Satisfaction and Priorities Survey. Research in Higher Education 16:2, 115-138. • Neville, PG. (1999). “Decision Trees for Predictive Modeling,” SAS Technical Report, The SAS Institute. • Thomas, EH and N Galambos. What Satisfies Students? Mining Student-Opinion Data with Regression and Decision Tree Analysis. Forthcoming in Research in Higher Education, May 2004.