Download

1 / 17
200 likes | 460 Vues
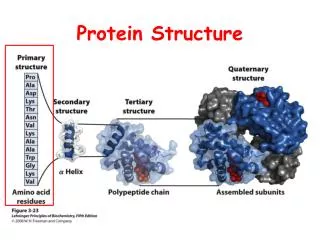
PROTEIN STRUCTURE CLASSIFICATION . SUMI SINGH (sxs5729). Levels of Protein Structure. Thanks to: Frank Lloyd Wright for graphics. WOOD, BRICK etc. material/building blocks AMINO ACIDS. *****************************************************************

E N D
PROTEIN STRUCTURE CLASSIFICATION SUMI SINGH (sxs5729)
Thanks to: Frank Lloyd Wright for graphics WOOD, BRICK etc. material/building blocks AMINO ACIDS ***************************************************************** Number of Amino Acids found in Eukaryotic Proteins= 20(found in universal genetic code)+ 2 (synthetically incorporated therefore not included in discussion) Possible number of protein sequence of size 300 = 20300 This number is greater than the total number of atoms in the universe
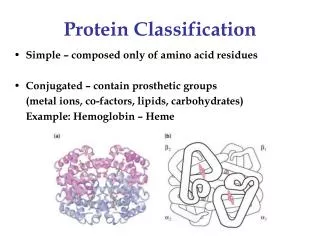
Evolution Evolution has selected a very small subset of those protein sequences < 30,000 in humans and an even smaller number of protein structures (1000–5000) Ratio– 1:6 Conserved structures are expected to reflect functional similarities (interaction with other molecules)
Why Compare Protein Structures? • Low sequence similarity may yield very similar structures • Sometimes high sequence similarity yields different structures Sequence Structure Function
Know your dataset For the current project
PDB: Protein Data Bank • The Protein Data Bank (PDB) archive is the single worldwide repository of information about the 3D structures of large biological molecules, including proteins and nucleic acids. • These are the molecules of life that are found in all organisms including bacteria, yeast, plants, flies, other animals, and humans. Understanding the shape of a molecule helps to understand how it works. • This knowledge can be used to help deduce a structure's role in human health and disease, and in drug development. The structures in the archive range from tiny proteins and bits of DNA to complex molecular machines like the ribosome. • Web address: http://www.rcsb.org/pdb/home/home.do
SCOP Dataset “Nearly all proteins have structural similarities with other proteins and, in some of these cases, share a common evolutionary origin. The SCOP database, created by manual inspection and abetted by a battery of automated methods, aims to provide a detailed and comprehensive description of the structural and evolutionary relationships between all proteins whose structure is known. As such, it provides a broad survey of all known protein folds, detailed information about the close relatives of any particular protein, and a framework for future research and classification.” • http://scop.berkeley.edu/
Starting at the bottom, the hierarchy of SCOP domains comprises the following levels -- Species representing a distinct protein sequence. -- Protein grouping together similar sequences of essentially the same functions. -- Family containing proteins with similar sequences but typically distinct functions. -- Superfamily bridging together protein families with common functional and structural features inferred to be from a common evolutionary ancestor. -- Levels above Superfamily are classified based on structual features and similarity, and do not imply homology:Folds grouping structurally similar superfamilies.
Structural Fingerprints/Features Structure comparison is an NP-Hard problem. There are no fast structural alignment algorithms that can guarantee optimality within any given similarity measure. Therefore, existing structure comparison methods employ heuristics. There are different approaches for extracting structural features. We use Triangular Spatial Relationship to generate keys.
HUH!! LOOKS LIKE I HAVE DONE EVERYTHING.. SO WHY ARE WHY AM I HERE? For the current project
What do you get from me? • A file of Keys Created Representing each Protein Structure. • Each of these files of keys representing protein has been correctly classified into their respective Superfamilies. • That will give you the class information for the files. It is a hypothesis that each file belonging to same class must have similar keys. You must be able to test this hypothesis.
For the current project • Develop SIGNATUREs for the PROTEIN KEYS. • These SIGNATUREs must be used to CLASSIFY the proteins correctly into their respective SUPERFAMILIES. • Performance and Speed are important
Signature for Keys • Accurately/concisely represent the keys. • Signatures can be simple statistics like mean, median etc. of the keys or a complex combination of features. • What ever may be the choice of Signature/s, it/they must be able to perform extremely fast and accurate classification of the protein/s.
Choice of Classifier/Tool • Criteria: 1. ACCURACY 2. SPEED
Final Product A software that takes in “keys” as input and classifies it correctly. There must be a check if the “new” protein-keys already exists in the system.