Download

1 / 32
460 likes | 926 Vues
Structural Genomics. – is defined as “ an approach to structural biology that capitalizes on highly parallel experimental strategies to address scientific questions that require many structures ” – was borne out of the Human Genome Project in the 1990s and related genome projects

E N D
Structural Genomics – is defined as “an approach to structural biology that capitalizes on highly parallel experimental strategies to address scientific questions that require many structures” – was borne out of the Human Genome Project in the 1990s and related genome projects – suddenly, there were a vast number of genes (and gene products!) available for analysis – like the Human Genome Project, technological convergence plays an important role – new synchrotron sources for X-ray crystallography – higher field, higher sensitivity NMR spectrometers – new computational and molecular modeling approaches – underlying question: if we know a lot about the protein universe in structural terms, are we better equipped to address new frontiers in basic science and disease/cancer?
Early Research in Structural Genomics – in the 1990s, researchers at Glaxo-Wellcome were working on the human nuclear hormone receptor family as drug targets – there were 48 members in the family and they didn’t know which one would be the best druggable target – so they decided to do as many as possible, in the end, 36 of them were done – a ten year long project can now be performed in a very small fraction of the time
Structural Genomics Consortia – the personnel, equipment costs are too large for one group to bear, especially if a group wishes to solve as many structures as possible – from an organism/pathogen such as Tuberculosis – from a protein family involved in disease such as kinases and receptors – a repertoire of proteins of the same predicted function from a wide array of species – a sparse approach where a group wishes to find as many new protein folds as possible regardless of protein, organism, etc
Structural Genomics Consortia Japan — RIKEN http://www.rsgi.riken.go/jp/rsgi_e/index.html – a fantastic facility in Yokohoma/Tokyo – 35+ NMR spectrometers – 200+ personnel – $30M budget Canada/England/USA — SGC — Structural Genomics Consortium – hub is in Toronto at Banting&Best / MaRS – RIKEN and SGC are responsible for the majority of deposited protein structures – also performs methods development in cloning, structure determination NESG — New England Structural Genomics PSI — Protein Structure Initiative (Univ Madison, US National Insts Health)
Statistics / Running the Numbers – the number of new proteins is increasing linearly with the number of new genomes discovered. There is need to be a strategy to get the most value per protein structure – health benefit – scientific benefit (is is novel?) 80-90% of proteins in any genome can be classified into a particular sequence family having a shared 3D structure Therefore, it may be good to pursue the orphaned proteins that don’t belong in any known family There are databases such as CDART that describe and search for protein domains – Conserved Domain Architecture Retrieval Tool
Statistics / Running the Numbers – In the CDART database, a related domain is defined statistically (E < 0.01). Extending the analysis of domains, the following key observations were made: ~75% of the protein universe can be grouped into 23000 different domain patterns. This estimate is consistent with the predictions of many groupls ~25% of the protein universe cannot be classified into a domain pattern either because the sequences are unique or the software can link these sequences to a family ~25% of the domain patterns have one structural representative already Of the domain patterns, about 12000 can be placed a family demonstrating a similar structure – the current output of structural genomics groups is 500 structures per year so it’ll take about 15 years to survey all of the protein families
The Human Proteome from a Structural Perspective – The human genome is composed of 20500 genes and 11 000 000 amino acids – about 65% of amino acids in the proteome are predicted to have a unique structure – about 22% are predicted to be disorderd – about 8 % are predicted to be in coiled coli helices – the remainder in signal peptides and transmembrane regions
The Human Proteome from a Structural Perspective – if two proteins share > 60% sequence identity, there are predicted to have the same molecular function 90% of the time – enzymes, however, that share > 30% sequence identity will have the same molecuar function – if two proteins have < 30% identity, they may still have the same structure but not necessarily the same function – a TIM barrel fold is capable of carrying out of 60 different functions
– some of the factors impacting the pursuit of structural genomics (Norin et al, 2002)
Structural Genomics Targets – directed research towards kinases, and proteins involved in nucleotide metabolism, helicases, polymerase, dehydrogenases, ubiquitination enzymes, anhydrases – kinases are involved in cell proliferation, cancer. Structural genomics advanced this effort significantly since 2005
Kinases / Bcr-Abl – formed as a result of a common chromosomal fusion called the Philadelphia Chromosome in many leukemias – one major cancer breakthrough was the development of Gleevec by Novartis in the late 1990s. Cost to patient per year for the drug = $40,000 to $80,000
- in this phylogenetic tree, the structural genomics programs have targeted branches of the various kinase classes that are underrepresented (in blue)
First Description of Structural Proteomics in 2000 – 424 non-membrane proteins from the extreme thermophilie M thermoautotrophicum were selected. The researchers figured a thermophile would provide lots of stable proteins at room temperature – there are a total of 1871 open reading frames in this bacterium – clear homologs in the PDB were excluded to enhance results – many proteins were in the sweet < 30 kDa range which is excellent for both NMR spectroscopy and X-ray crystallography
First Description of Structural Proteomics in 2000 – Every three days, one person could generate 20 clones for the project. To facilitate purification, a His6 tag was placed on each. – approximately 500 solution conditions were assayed for each protein for X-ray crystallography using a sparse matrix. – a NMR HSQC spectrum (20 minutes acquisition time) was probably used to assay the suitability for that technique (Logan will explain on the board!) – The ratio of excellent-promising-poor was 33/10/57 – thus, in the population, about 60% of the proteins are not suitable for structural studies.
First Description of Structural Proteomics in 2000 – the researchers made a decision tree to determine what factors were contributing to the poor solubility of some of the proteins – insoluble proteins are likely to have a hydrophobic stretch of > 20 aa to have a Gln composition < 4% to have an Asp+Glu composition < 17% to have an aromatic composition > 7% These rules together have an error rate of 14% versus 39% without the tree
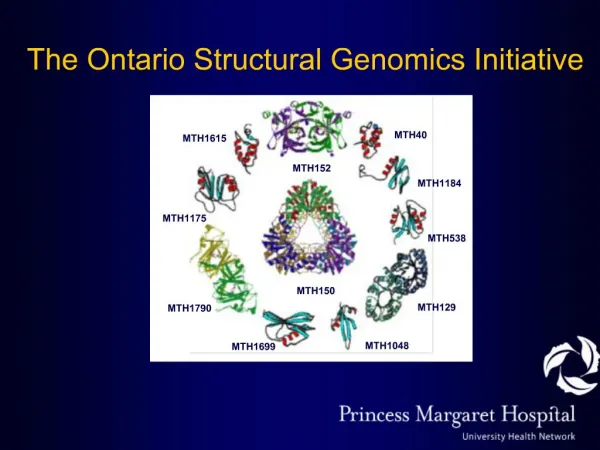
First Description of Structural Proteomics in 2000 – here are 10 of the structures that were determined by NMR and X-ray methods – although none had a homolog, once the structure was known, all had at least one structural homolog as determined by the program, DALI. – the authors then attempted to infer function from the structures... – 5 of the 10 structures had a bound ligand or cofactor, which helped immensely
First Description of Structural Proteomics in 2000 – MTH150 was solved with a bound NAD+ cofactor. – it also bears an HXGH motif which suggests an active site that can serve as an adenylyl transferase – futher biochemical studies on the protein confirmed that MTH150 is a nicotinamide adenylyltransferase
First Description of Structural Proteomics in 2000 – MTH1615 was solved by NMR methods. – the initial spectra were poor suggesting that there were many unstructured amino acids in the protein – limited protelolysis showed that the first 31 aa. were dispensible for the structure and a new clone was made – it has an ortholog invoved in programmed cell death – the structure suggested that it was a DNA binding protein which was confirmed against a random pool of 20-mer DNA duplexes
First Description of Structural Proteomics in 2000 – MTH1699 was predicted to be an archael bacterial translation elongation factor – the fold suggests that it is capable of binding RNA – the structure of human EF-1beta is very similar despite very low sequence identity – thus, the machinery supporting translation is under strong pressure to maintain a certain structure – a calcium ion was found in this protein, unlike the others. The authors speculate that the metal might make this form more thermostable