Download
1 / 1
10 likes | 119 Vues
Project Overview: Technology Based Assessment of Language and Literacy. The TBALL Project Data Collection: Making a Young Children's Speech Corpus

E N D
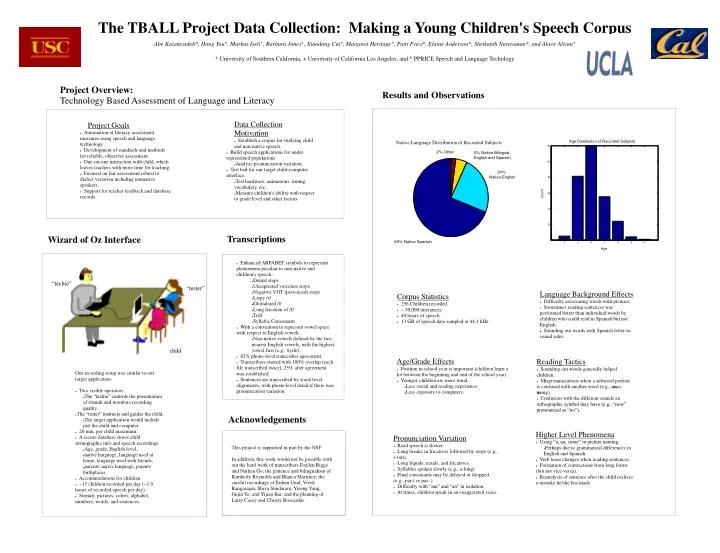
Project Overview: Technology Based Assessment of Language and Literacy The TBALL Project Data Collection: Making a Young Children's Speech Corpus Abe Kazemzadeh*, Hong You+, Markus Iseli+, Barbara Jones+, Xiaodong Cui+, Margaret Heritage+, Patti Price^, Elaine Anderson*, Shrikanth Narayanan*, and Abeer Alwan+ * University of Southern California, + University of California Los Angeles, and ^ PPRICE Speech and Language Techology Results and Observations Data Collection Motivation • Establish a corpus for studying child and non-native speech. • Build speech applications for under-represented populations. • Analyze pronunciation variation. • Test bed for our target child-computer interface. • Test hardware, animations, timing, vocabulary, etc. • Measure children's ability with respect to grade level and other factors Project Goals • Automation of literacy assessment measures using speech and language technology. • Development of standards and methods for reliable, objective assessment. • One-on-one interaction with child, which leaves teachers with more time for teaching. • Focused on fair assessment robust to dialect variation including nonnative speakers. • Support for teacher feedback and database records. Native Language Distribution of Recorded Subjects Transcriptions Wizard of Oz Interface • Enhanced ARPABET symbols to represent phenomena peculiar to non-native and children's speech: • Dental stops • Unaspirated voiceless stops • Negative VOT (prevoiced) stops • Lispy /s/ • Glottalized /t/ • Long frication of /f/ • Trill • Syllabic Consonants • With a convention to represent vowel space with respect to English vowels • Non-native vowels defined by the two nearest English vowels, with the highest vowel first (e.g., /iyih/). • 82% phone-level transcriber agreement. • Transcribers started with 100% overlap (each file transcribed twice), 25% after agreement was established. • Sentences are transcribed by word-level alignments, with phone-level detail if there was pronunciation variation. “techie” “tester” Language Background Effects • Difficulty associating words with pictures. • Sometimes reading sentences was performed better than individual words by children who could read in Spanish but not English. • Sounding out words with Spanish letter-to-sound rules. Corpus Statistics • 256 Children recorded. • ~ 30,000 utterances. • 40 hours of speech. • 13 GB of speech data sampled at 44.1 kHz. child Age/Grade Effects • Position in school year is important (children learn a lot between the beginning and end of the school year). • Younger children are more timid. • Less social and reading experience. • Less exposure to computers. Reading Tactics • Sounding out words generally helped children. • Mispronunciations when a subword portion is confused with another word (e.g., once, using). • Confusion with the different sounds an orthographic symbol may have (e.g., “now” pronounced as “no”). Our recording setup was similar to our target application: • Two visible operators: • The “techie” controls the presentation of stimuli and monitors recording quality. • The “tester” instructs and guides the child. • The target application would include just the child and computer. • 20 min. per child maximum. • A secure database stores child demographic info and speech recordings: • Age, grade, English level, • native language, language used at home, language used with friends, • parents' native language, parents' birthplaces. • Accommodations for children. • ~15 children recorded per day (~1.9 hours of recorded speech per day). • Stimuli: pictures, colors, alphabet, numbers, words, and sentences. Acknowledgements Higher Level Phenomena • Using “a, an, some” in picture naming. • Perhaps due to grammatical differences in English and Spanish. • Verb tense changes when reading sentences. • Formation of contractions from long forms (but not vice-versa). • Reanalysis of sentence after the child realizes a mistake he/she has made. Pronunciation Variation • Read speech is slower. • Long breaks in fricatives followed by stops (e.g., s-tart). • Long liquids, nasals, and fricatives. • Syllables spoken slowly (e.g., a-long). • Final consonants may be delayed or dropped (e.g., par-t or par- ). • Difficulty with “am” and “an” in isolation. • At times, children speak in an exaggerated voice. This project is supported in part by the NSF. In addition, this work would not be possible with out the hard work of transcribers Daylen Riggs and Nathan Go; the patience and bilingualism of Kimberly Reynolds and Blanca Martinez; the careful recordings of Erdem Unal, Vivek Rangarajan, Shiva Sundaram, Yirong Yang, Jinjin Ye, and Yijian Bai; and the planning of Larry Casey and Christy Boscardin.






















