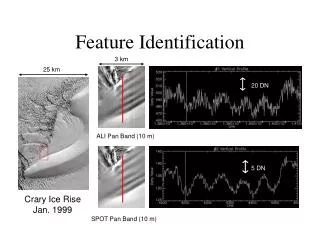
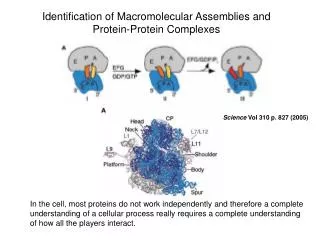
Download

1 / 102
1.05k likes | 1.2k Vues
Protein Feature Identification. David Wishart Depts. Computing & Biological Science University of Alberta david.wishart@ualberta.ca. Proteins. Exhibit far more sequence and chemical complexity than DNA or RNA

E N D
Protein Feature Identification David Wishart Depts. Computing & Biological Science University of Alberta david.wishart@ualberta.ca
Proteins • Exhibit far more sequence and chemical complexity than DNA or RNA • Properties and structure are defined by the sequence and side chains of their constituent amino acids • The “engines” of life • >95% of all drugs target proteins • Favorite topic of post-genomic era
The Post-genomic Challenge • How to rapidly identify a protein? • How to rapidly purify a protein? • How to identify post-trans modification? • How to find information about function? • How to find information about activity? • How to find information about location? • How to find information about structure? Answer: Look at Protein Features
Protein Features ACEDFHIKNMF SDQWWIPANMC ASDFDPQWERE LIQNMDKQERT QATRPQDS... Sequence View Structure View
Different Types of Features • Composition Features • Mass, pI, Absorptivity, Rg, Volume • Sequence Features • Active sites, Binding Sites, Targeting, Location, Property Profiles, 2o structure • Structure Features • Supersecondary Structure, Global Fold, ASA, Volume
Where To Go http://www.expasy.org/
Glycine and Proline H C C HN COOH H2N COOH H H P G
Aliphatic Amino Acids CH3 CH3 CH3 CH3 V I C C H2N COOH H2N COOH H H CH3 CH3 CH3 A L C H2N COOH C H2N COOH H H
Aromatic Amino Acids N N N W H C C H2N COOH H2N COOH OH H H Y F C C H2N COOH H2N COOH H H
Charged Amino Acids H - COO + N D NH3 R C NH H2N COOH + C H NH3 H2N COOH - COO H E K C C H2N COOH H2N COOH H H
Polar Amino Acids CH3 OH CONH2 N T C C H2N COOH H2N COOH H H CONH2 OH Q S C C H2N COOH H2N COOH H H
Sulfo-Amino Acids CH3 S SH C C H2N COOH H2N COOH H H M C
Compositional Features • Molecular Weight • Amino Acid Frequency • Isoelectric Point • UV Absorptivity • Solubility, Size, Shape • Radius of Gyration • Free Energy of Folding
Molecular Weight • Useful for SDS PAGE and 2D gel analysis • Useful for deciding on SEC matrix • Useful for deciding on MWC for dialysis • Essential in synthetic peptide analysis • Essential in peptide sequencing (classical or mass-spectrometry based) • Essential in proteomics and high throughput protein characterization
Molecular Weight • Crude MW calculation: MW = 110 X Numres • Exact MW calculation: MW = SAAi x MWi • Remember to add 1 water (18.01 amu) after adding all res. • Note isotopic weights • Corrections for CHO, PO4, Acetyl, CONH2
Amino Acid versus Residue R R C C N CO H2N COOH H H H Amino Acid Residue
Protein Identification via MW • MOWSE • http://srs.hgmp.mrc.ac.uk/cgi-bin/mowse • CombSearch • http://ca.expasy.org/tools/CombSearch/ • Mascot • http://www.matrixscience.com/search_form_select.html • AACompSim/AACompIdent • http://ca.expasy.org/tools/
Molecular Weight & Proteomics 2-D Gel QTOF Mass Spectrometry
Amino Acid Frequency • Deviations greater than 2X average indicate something of interest • High K or R indicates possible nucleoprotein • High C’s indicate stable but hard-to-fold protein • High G, P, Q, or N says lack of stable structure
Isoelectric Point (pI) • The pH at which a protein has a net charge=0 • Q = S Ni/(1 + 10pH-pKi) Transcendental equation
Isoelectric Point • Calculation is only approximate (+/- 1 pH) • Does not include 3o structure interactions • Can be used in developing purification protocols via ion exchange chromatography • Can be used in estimating spot location for isoelectric focusing gels • Can be used to decide on best pH to store or analyze protein
UV Absorptivity • UV (Ultraviolet light) has a wavelength of 200 to 400 nm • Most proteins and peptides (and all nucleic acids) absorb UV light quite strongly • UV spectroscopy is the most common form of spectroscopy performed today • UV spectra can be used to identify or classify some proteins or protein classes
C C H2N H2N COOH COOH H H UV Absorptivity • OD280 = (5690 x #W + 1280 x #Y)/MW x Conc. • Conc. = OD280 x MW/(5690 X #W + 1280 x #Y) OH N
Hydrophobicity • Indicates Solubility • Indicates Stability • Indicates Location (membrane or cytoplasm) • Indicates Globularity or tendency to form spherical structure
Average Hydrophobicity AH = S AAi x Hi Hydrophobic Ratio RH = S H(-)/S H(+) Hydrophobic % Ratio RHP = %philic/%phobic Linear Charge Density LIND = (K+R+D+E+H+2)/# Solubility SOL = RH + LIND - 0.05AH Average AH = 2.5 + 2.5 Insol > 0.1 Unstrc < -6 Average RH = 1.2 + 0.4 Insol < 0.8 Unstrc > 1.9 Average RHP = 0.9 + 0.2 Insol < 0.7 Unstrc > 1.4 Average LIND = 0.25 Insol < 0.2 Unstrc > 0.4 Average SOL = 1.6 + 0.5 Insol < 1.1 Unstrc > 2.5 Hydrophobicity
Protein Dimensions • Radius and Radius of Gyration • Molecular and Partial Specific Volume • Accessible Surface Area • Provides a size estimate of a protein • Used in analytical techniques such as neutron or X-ray scattering, analytical ultracentrifugation, light scattering
Radius & Radius of Gyration • RAD = 3.875 x NUMRES 0.333 (Folded) • RADG = 0.41 x (110 x NUMRES) 0.5 (Unfolded) RadiusRadius of Gyration
Partial Specific Volume • Measured in mL/g • Inverse measure of protein density (0.70-75) • Depends on protein’s composition and compactness • Measured via sedimentation analysis • PSV = S PSi x Wi
Packing Volume Loose Packing Dense Packing Protein Proteins are Densely Packed
Packing Volume (VP) • Determined via X-ray or NMR structure • “True” measure of volume occupied by protein • Approximate Value VP = 1.245 x MW • Exact Value VP = S AAi x Vi
Different Types of Features • Composition Features • Mass, pI, Absorptivity, Rg, Volume • Sequence Features • Active sites, Binding Sites, Targeting, Location, Property Profiles, 2o structure • Structure Features • Supersecondary Structure, Global Fold, ASA, Volume
Sequence Features AHGQSDFILDEADGMMKSTVPN… HGFDSAAVLDEADHILQWERTY… GGGNDEYIVDEADSVIASDFGH… *[LIVM][LIVM]DEAD*[LIVM][LIVM]* (EIF 4A ATP DEPENDENT HELICASE)
Probability & Seq. Features • Expectation value (e) is the expected number of hits for a given sequence pattern or motif • e = N x f1 x f2 x f3 x .... fk • N is the number of residues in DB (108) • fi is the frequency of a given amino acid(s)
Example #1 ACIDS e = 108*0.088*0.021*0.054*0.059*0.065 e = 38.3 #Found in OWL database = 14
Example #2 A*ACI[DEN]S e = 108*0.088*1.000*0.088*0.021*0.054 *{0.059 + 0.059 + 0.046}*0.065 e = 9.4 #Found in OWL database = 9
Minimum Pattern Lengths e = 108*0.088 = 0.17 min = 8 e = 108*0.057 = 0.08 min = 7 e = 108*0.036 = 0.07 min = 6 f = 0.08 f = 0.05 f = 0.03
How Long Should a Sequence Motif or Sequence Block Be? • How many matching segments of length “l” could be found in comparing a query of length M to a DB of N ? • Answer: n(l) = M x N x fl • Assume f = 0.05, M = 300, N = 100,000,000
Rule of Thumb Make your protein sequence motifs at least 8residues long
Sites that Support Pattern Queries • OWL Database • http://bioinf.man.ac.uk/dbbrowser/OWL/ • PIR Website • http://pir.georgetown.edu/pirwww/search/patmatch.html • SCNPSITE at EXPASY • http://ca.expasy.org/tools/scanprosite/ • FPAT (Regular Expression Query) • http://stateslab.bioinformatics.med.umich.edu/service/fpat/
Regular Expressions • C[ACG]T - Matches CAT, CCT and CGT only • C . T - Matches CAT, CaT, C1T, CXT, not CT • CA?T - Matches CT or CAT only • C+T - Matches CT, CCT, CCCT, CCCCT… • C(HE)?A[TP] - Matches CHEAT, CAT, CHEAP, CAP • S[A-I,L-Q,T-Z]?LK[A-I,L-Q,T-Z]?A - Matches S*LK*A
PROSITE Pattern Expressions C - [ACG] - T - Matches CAT, CCT and CGT only C - X -T - Matches CAT, CCT, CDT, CET, etc. C - {A} -T - Matches every CXT except CAT C - (1,3) - T - Matches CT, CCT, CCCT C - A(2) - [TP]- Matches CAAT, CAAP [LIV] - [VIC] - X(2) - G - [DENQ] - X - [LIVFM] (2) -G
Sequence Feature Databases • PROSITE - http://ca.expasy.org/prosite/ • BLOCKS - http://www.blocks.fhcrc.org/ • DOMO - http://www.infobiogen.fr/services/domo/ • PFAM - http://pfam.wustl.edu • PRINTS - http://www.bioinf.man.ac.uk/dbbrowser/PRINTS/ • SEQSITE - PepTool
C C C H2N H2N H2N COOH COOH COOH H H H Phosphorylation Sites pY pT pS PO4 CH3 PO4 PO4