Download

1 / 13
130 likes | 263 Vues
Hiding Synchronization Delays in a GALS Processor Microarchitecture. Greg Semeraro David H. Albonesi Grigorios Magklis Michael L. Scott Steven G. Dropsho Sandhya Dwarkadas. Why GALS?. Simplified clock distribution network Reduced clock power dissipation

E N D
Hiding Synchronization Delays in a GALS Processor Microarchitecture Greg Semeraro David H. Albonesi Grigorios Magklis Michael L. Scott Steven G. Dropsho Sandhya Dwarkadas
Why GALS? • Simplified clock distribution network • Reduced clock power dissipation • Allows modular design of the processor • Can run each domain at optimal frequency • Can use conventional design and testing methods • Fine-grained DVS/DFS ASYNC 2004 - University of Rochester
But there is a cost… • Inter-domain synchronization can hurt performance • Synchronization circuit costs in area and power • We have to be careful how we divide the processor ASYNC 2004 - University of Rochester
Integer int. register file int. FUs CPU IIQ Main Memory Frontend ROB Memory L2 unified cache L1 data cache fetch IFQ dispatch LSQ L1 instr. cache branch predict rename Floating Pt fp. register file fp. FUs FIQ The MCD Microprocessor ASYNC 2004 - University of Rochester
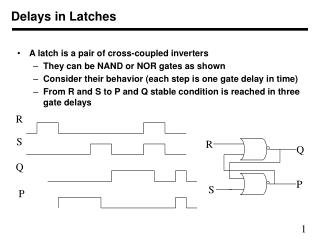
Inter-domain Synchronization • Queue design based on Chelcea and Nowick (WVLSI ’00) • Modified for Issue Queue configuration • Synchronization circuit based on Nyström and Martin (WCED ’02) • Converted to single-rail logic • Timing analysis based on Sjogren and Myers (ARVLSI ’97) • Skip a cycle rather than pause the clock ASYNC 2004 - University of Rochester
FIFO Queue Issue Queue Synchronization via Queues ASYNC 2004 - University of Rochester
1 4 CLK1 2 3 CLK2 T Timing Analysis • Source runs with CLK1, destination with CLK2 • Source writes at edge 1 • If T > Ts then the data can be used at edge 2 • If T < Ts then the data can be used at edge 3 • 25% < Ts < 35% ASYNC 2004 - University of Rochester
Simulation Methodology • Two processor pipelines • Alpha 21264 • StrongARM SA-1110 • Synchronization penalty was measured against an identical synchronous design • 30 benchmarks • MediaBench, Olden, SPEC 2000 ASYNC 2004 - University of Rochester
Simulation Methodology • Simplescalar + Wattch + MCD • Independent clock for each domain • Independent jitter for each domain • Next edge based on period, last edge, jitter • When source and destination clocks are too close, one cycle penalty is assessed ASYNC 2004 - University of Rochester
Synchronization Analysis • OoO and superscalar capabilities removed from Alpha ASYNC 2004 - University of Rochester
Synchronization Analysis • OoO and superscalar capabilities added to StrongARM ASYNC 2004 - University of Rochester
What we have learned • Synchronization penalty doesn’t mean performance loss • Out-of-order execution allows useful work to be performed when instructions are delayed • Superscalar design means that synchronization penalties can be “shared” across multiple instructions • For Alpha 95% of penalty hidden • For StrongARM++ 63% of penalty hidden • We have to be careful • Cannot have too many domains • Careful where you split! ASYNC 2004 - University of Rochester
Conclusions • GALS is a good idea for real processors • small IPC loss • clock network simplification • reduction in power dissipation • higher frequency • independent domain tuning ASYNC 2004 - University of Rochester