Download
1 / 23
230 likes | 295 Vues
Relevant Previous Algorithms. Linear discrimination LMS Gradient descent. Features. Simple but powerful Nonlinear functions Multilayers Heuristic. Feedforward Operation Example. y, Perceptron. Fourier’s Theorem. Kolmogorov. Universal expressive power.

E N D
Relevant Previous Algorithms • Linear discrimination • LMS • Gradient descent
Features • Simple but powerful • Nonlinear functions • Multilayers • Heuristic
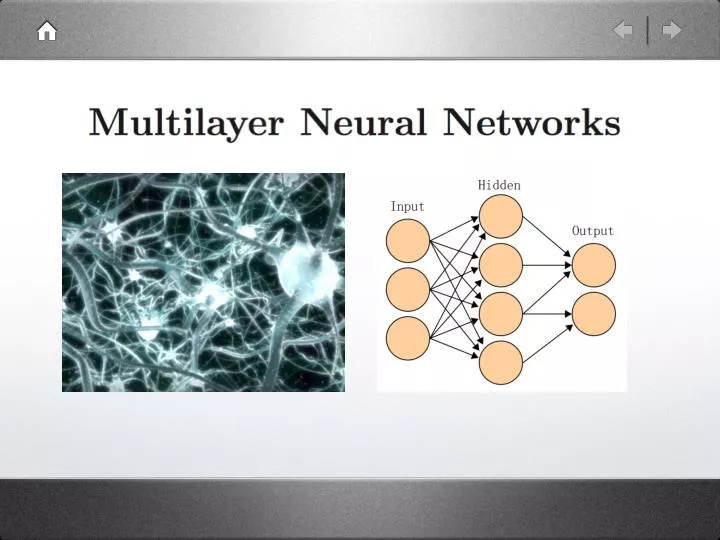
Feedforward Operation Example y, Perceptron
Fourier’s Theorem Kolmogorov Universal expressive power too complex, cannot be smooth, don’t know how to find
Gradient descent Iteration Back Propagation Algorithm Criterion function
- Back Propagation Algorithm Hidden-to-output
Back Propagation Algorithm Input-to-output Back Propagation
Learning Curves Back Propagation Algorithm • Stochastic • Batch • On-line • Queries Training Protocols
Error with small networks Back Propagation Algorithm
Back Propagation Algorithm Training Examples
Improving B-P Sigmoid i.e. hyperbolic tangent Transfer function • Gaussian • Nonlinear • Saturate • Continuity and smoothness • Monotonicity • Linear for small value of net • computational simplicity
Improving B-P • Shift • Scale • on-line Scaling inputs Setting bias • Teaching • Limit net activation • Keep balance
Improving B-P • Small training set • Virtual training patterns • Gaussian noise • More information • Representative • Rotation Training with noise Training with noise
Improving B-P • Expressive power • Complexity of decision boundary • Based on pattern distribution Number of hidden units Rule of thumb: n/10
Improving B-P Initialize weights Fast and uniform learning
( ) -1 Improving B-P • Convergence • Speed • Quality Learning rates Optimal learning rate is the one which leads to the local error minimum in one learning step
Improving B-P • Learn more quickly with plateaus • Speeding up even far from error plateaus Momentum
Small weights Heuristic: Improved network performance Implementation: Improving B-P Weight decay
Improving B-P Hints Add information or constraints to aid category learning.
Improving B-P • Overfitting • Less than some preset value • Error on a validation set reaches a minimum • Equivalent to weight decay Stopped Training
Improving B-P How many hidden Layers?




















