Download

1 / 25
260 likes | 552 Vues
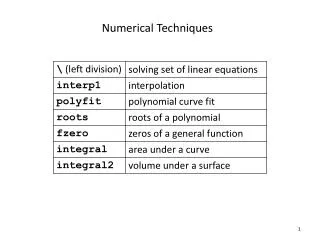
Numerical Data Masking Techniques for Maintaining Sub-Domain Characteristics. Krish Muralidhar University of Kentucky Rathindra Sarathy Oklahoma State University. Ideal Data Utility for Masking Numerical Data.

E N D
Numerical Data Masking Techniques for Maintaining Sub-Domain Characteristics Krish Muralidhar University of Kentucky Rathindra Sarathy Oklahoma State University
Ideal Data Utility for Masking Numerical Data • Ideally, results of all analyses using the masked data should be identical to that using the original data. • Impossible to achieve in practice.
Practical Data Utility • Results of most analyses using the masked data should be very similar to that using the original data. • Performance of the masking technique should be predictable (theory-based methods are preferable over ad hoc methods)
Practical Assessment of Data Utility • Univariate (Marginal) characteristics • Maintain some sufficient statistics • When sufficient statistics are maintained in the masked data, results for analyses based on these statistics using the masked data can be guaranteed to be exactly the same as that using the original data • Relationships • Linear • Monotonic • Non-monotonic
Sub-domain Characteristics • An important component of data utility for Government agencies and users is the need to maintain characteristics of the original data within sub-domains, in the masked data • With a few exceptions, this aspect of data utility has NOT been directly addressed when evaluating techniques for masking numerical data
Preferred Techniques • In this study, we investigate the performance of two techniques in maintaining sub-domain characteristics when masking numerical data. • Sufficiency Based perturbation approach (Burridge 2003; Muralidhar and Sarathy 2007) • Data Shuffling (Muralidhar and Sarathy 2006) • Why these two techniques? • These two techniques can maintain certain characteristics for sub-domains exactly • They dominate the performance of other techniques for masking numerical data
Sufficiency Based Linear Models • X, S, and Y represent the confidential, non-confidential, and masked data, respectively; ε represent the noise term. • Σrepresents the covariance matrix between variables. • Specification of β2 dictates the extent of relationship between original and masked data
Examples • Simulated example • Census Data • In our presentation, we will focus on the simulated data. The manuscript has a complete discussion of the results for the Census data.
Simulated Example • Number of observations = 50000 • Three categorical, non-confidential variables • Gender (Male or Female) • Marital Status (Married or Other) • Age Group (1 to 6) • Total of 24 sub-groups • Three numerical, confidential variables • Home value (Positive, non-normal) • Mortgage balance (Positive, non-normal) • Net value of assets (normal)
Methods • Data Shuffling • Three Sufficiency based perturbations • Given S • Y is conditionally independent of X (d = 0.00) • Y is moderately related to X (d = 0.50) • Y is closely related to X (d = 0.90) where d are the values of the diagonal elements of the diagonal matrix β2
Evaluation • Compare performance of techniques in sub-domains • Disclosure risk • Identity (assessed using the procedure by Fuller (1993) • Value (assessed by comparing proportion of variance explained in confidential variables, before & after masking) • Data utility • Marginal (or univariate) distribution • Linear relationship between variables • Non-linear relationship between variables
Risk of Value Disclosure • Perturbed data with d = 0.50, 0.90 results in increased predictive accuracy. • Does is matter?
Marginal (or Univariate) Distribution (Mortgage Balance) (Entire Data Set)
Sub-group Marginal Distribution(Home Value) (Gender = 0, Marital = 0, Age = 1)
Disclosure risk Identity disclosure risk is 1/n Providing access to masked data does not improve predictive ability [R2(X|S,Y) = R2(X|S)] The mean, covariance and in fact the entire univariate distributions of masked data are exactly the same as the original data for every sub-group and the entire data set Maintains (asymptotically) Covariance matrix Product moment correlation matrix Rank order correlation matrix for every sub-domain and the overall data set Comparison of the Methods Data Shuffling
Comparison of the MethodsSufficiency Based Method • Disclosure risk is minimized for the perturbed data set when d = 0, but not in the other cases. • The univariate distribution of the masked data is very different from the original data. • Maintains (exactly) • Mean Vector • Covariance matrix • Product moment correlation for every sub-domain and the entire data set. 4. Does not maintain rank order correlation
Conclusion • If it is known that the data will be used exclusively for traditional, parametric analysis, sufficiency based methods offer the best performance • In all other cases, Data shuffling offers the best performance
Future Research • We need to explore this topic further • Our initial result suggests that both techniques may even be capable of maintaining all types of relationships between the non-confidential variables and the masked variables. Is this true for all cases? • What if arbitrary sub-domains are created by using numerical variables?
For more details on our work, please visit: gatton.uky.edu/faculty/muralidhar/maskingpapersWe have CD’s with copies of our paper, presentation, and the data sets. We will be happy to share it with you. (krishm@uky.edu or rathin.sarathy@okstate.edu)
We welcome your questions or comments or suggestions.Thank you.