Download

1 / 17
180 likes | 392 Vues
Computer assisted assessment of essays. Advantages Reduces costs of assessment Less staff is needed for assessment tasks Increases objectivity More than one assessor can be used without doubling the costs Automated marking is not prone to human error Instant feedback Helps students

E N D
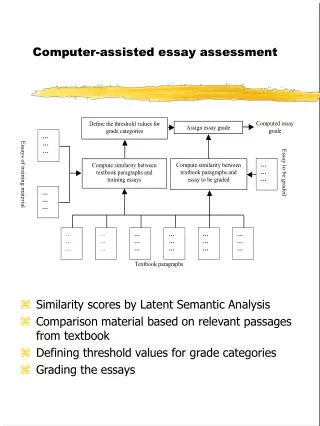
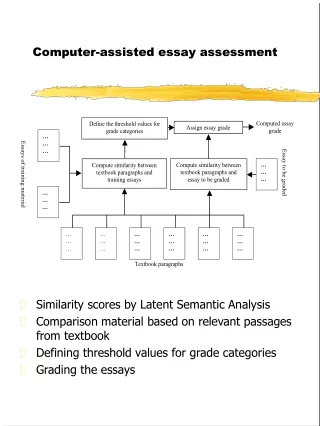
Computer assisted assessment of essays • Advantages • Reduces costs of assessment • Less staff is needed for assessment tasks • Increases objectivity • More than one assessor can be used without doubling the costs • Automated marking is not prone to human error • Instant feedback • Helps students • As accurate as human graders • Measured by correlation between grades given by humans and system • Training material • Basis of scores given by computer • Human graded essays • Training is done separately for each assignment • Usually 100 to 300 essays are needed • Surface features, structure, content
Computer assisted assessment of essays • Surface Features • Total number of words per essay • Number of commas • Average length of words • Number of paragraphs • The earliest systems where based solely on surface features • Rhetorical Structure • Identifying the arguments presented in essay • Measuring coherence • Content • Relevance to the assignment • Use of words
Analysis of Essay Content • Information retrieval methods • Vector Space Model • Latent Semantic Analysis • Naive-Bayes text categorization • Ways to improve efficiency • Stemming, term weighting, use of stop-word list • Stemming • Reduces the amount of index words • Reducing different word forms to common roots • Finding words that are morphological variants of the same word stem • apply -> applying, applies, applied
Local term weight Global term weight (entropy) Analysis of Essay Content • Term weighting • Raw word frequencies are transformed so that they tell more about the words’ importance in the context • Amplifies the influence of words, which occur often in a document, but relative rarely in the whole collection of documents • Information retrieval effectiveness can be improved significantly • Term-frequency – inverse document frequency (Tf-Idf), Entropy • Stop-word list • Removing the most common words • For example prepositions, conjunctions, nouns and articles (a, an, the, and , or...) • Common words have no additional meaning to the content of the text • Saves processing time and working memory
Comparison of Essay evaluation systems • Assessment systems • Project Essay Grade (PEG) • Text Categorization Technique (TCT) • Latent Semantic Analysis (LSA) • Electronic Essay Rater (E-Rater) • Content refers to what the essay says and style refers to the way it is said • System can simulate the score without great concern about the way it was produced (grading simulation) or measure the intrinsic variables of the essay (master analysis)
Project Essay Grade (PEG) • One of the earliest implementations of automated essay grading • Development began in 1960’s • Primarily relies on surface features and no natural language processing is used • Average word length • Number of commas • Standard deviation of word length • Regression model based on training material • Scoring by using regression equation
Text Categorization Technique (TCT) • Measures both content and style • Uses a combination of key words and text complexity features • Naive-Bayes categorization • Assesment of content • Analysis of the occurrence of certain key words in the documents • Probabilities estimating the likelihood that essay belong to a specified grade category • Text Complexity Features • Assesment of style • Surface features • Number of words • Average length of words
E-Rater • A hybrid approach of combining linguistic features with other document structure features • Syntax, discourse structure and content • Syntactic features • Measures the syntactic variety • Ratios of different clause types • Use of modal verbs • Discourse structure • Measures how well writer has been able to organize the ideas • Identifies the arguments in the essay by searching “cue” words or terms that signal where an argument begins and how it is been developed • Content • Analyzes how relevant the essay is to the topic by considering the use of words • Vector Space Model
Latent Semantic Analysis (LSA)aka Latent Semantic Indexing (LSI) • Several Applications • Information Retrieval • Information Filtering • Essay Assessment • Issues in Information Retrieval • Synonyms are separate words that have the same meaning. They tend to reduce recall. • For example: Football, soccer • Polysemy refers to words that have multiple meanings. This problem tends to reduce precision. • For example: "foot" as the lower part of the leg or as the bottom of a page or as a specific metrical measure • Both issues point to a more general problem • There is a disconnect between topics and keywords • LSA attempts to discover information about the meaning behind words • LSA is proposed as an automated solution to the problems of synonymy and polysemy
Latent Semantic Analysis (LSA) • Singular Value Decomposition • Reduces the dimensionality of word-by-document matrix • Using a reduced dimension new relationships between words and contexts are induced when reconstructing a close approximation to the original matrix • These new relationships are made manifest, whereas prior to the SVD, they were hidden or latent • Reduces irrelevant data and “noise” • Documents are presented as a matrix in which each row stands for a unique word and each column stands for a text passage (word-by-document matrix) • Truncated singular value decomposition is used to model latent semantic structure • Resulting semantic space is used for retrieval • Can retrieve documents that share no words with query .
Latent Semantic Analysis (LSA) • Word-by-document matrix
Latent Semantic Analysis (LSA) • Singular value decomposition
Latent Semantic Analysis (LSA) • Two dimensional reconstruction of word-by-document matrix
Word-by-document matrix Latent Semantic Analysis (LSA) • Semantic space is constructed from the training material • To grade an essay, a matrix for the essay document is built • Document vector of essay is compared to the semantic space • Grade is determined by averaging the grades with the most similar essays
A B Latent Semantic Analysis (LSA) • Document comparison • Euclidean distance • Dot product • Cosine measure • Cosine between document vectors • Dot product of vector divided by their lengths
Latent Semantic Analysis (LSA) • Precision comparison of LSA and Vector Space Model at 10 recall levels • Pros • Doesn’t just match on terms, tries to match on concepts • Cons • Computationally expensive, its not cheap to compute singular values • Choice of dimensionalityis somewhat arbitrary, done by experimentation








![Computer Assisted Learning [CAL]](https://cdn2.slideserve.com/3962806/slide1-dt.jpg)