Download

1 / 46
460 likes | 464 Vues
Kirrkirr is a Java-based tool for visualizing XML dictionaries of Australian languages. It provides innovative ways for representing dictionaries, with practical and educational programs. The tool allows users to explore the richness of lexical structure and offers various modules like animated graph layouts, formatted dictionary entries, multimedia support, and advanced searching interfaces.

E N D
Kirrkirr: A Java-based visualisation tool for XML dictionaries of Australian Languages Kevin Jansz Department of Computer Science, University of Sydney, Australia Christopher Manning Computer Science and Linguistics, Stanford University, USA Nitin Indurkhya School of applied Science, Nanyang Technological University, Singapore
Project Objectives • providing innovative ways for representing a dictionary, through creative use of the medium of computers • providing practical educationally useful programs as a result (at low labour cost) • examining the richness of lexical structure Initial target: the Warlpiri dictionary.
Talk Outline • The research agendas • Kirrkirr: A Warlpiri dictionary browser • The (XML) Lexical Database • exploiting the strengths of XML • indexing XML data • Visualisation of Dictionary Content • User studies
Research Program: Lexicon • A language is more than individual words with a definition • it is a vast network of associations between words and within and across the concepts represented by words • The aim of this work is to provide people with a better understanding of this conceptual map. • Traditional paper dictionaries offer very limited ways for making such networks visible • On a computer, there are no such limitations to the way information can be displayed
Research: Computational Lexicography • Dictionaries on computers are now commonplace • But there has been little attempt to utilise the potential of the new medium • Many present a plain, search-oriented representation of the paper version • Goal: fun dictionary tools that are effective for language learning, browsing • Like flicking through pages of a paper dictionary • Difference is words are grouped by meaning rather than spelling
MRD Structure • The internal structures of current Machine Readable Dictionaries (MRDs) usually merely mimic the structure of the printed form (Boguraev 1990) • Some work, notably WordNet (Miller 1995) has involved a fundamental rethinking of dictionary content and organisation (in WordNet, organisation via “synsets” which are related via links of part, subkind, opposite) • But there has been little in the way of software to make such research truly usable by different communities of users.
Initial focus: Warlpiri • Warlpiri is an Australian Aboriginal language spoken in the Tanami desert (NW of Alice) • There are a number of factors influencing this choice: • Rich lexical materials have been collected by linguists over decades (Ken Hale, MIT, from 1950’s) resulting in one of the most comprehensive lexical databases for any Australian Language • There is a relatively large community of people interested in learning their traditional language • Until now, results haven’t been produced in a format usable by the community (only raw printouts)
Educational goals • Dictionary structure and usability are often dictated by professional linguists, while the needs of others (speakers, semi-speakers, young users, second language learners) are not met • The low level of literacy in the region makes an e-dictionary potentially more useful than a paper edition • less dependent on good knowledge of spelling and alphabetical order. • Making it fun and easy to use, and providing multimedia content and the pronunciations of words is a considerable help as well.
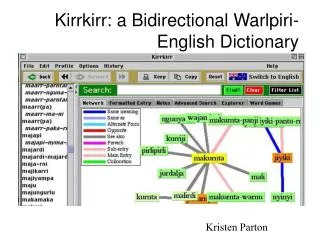
Kirrkirr: A Warlpiri dictionary browser (Jansz 1998; Jansz, Manning and Indurkhya 1999) • An environment for the interactive exploration of dictionaries. • Although our current work has just been with Warlpiri, the design is general (Arrernte coming soon!) • Attempts to more fully utilise graphical interfaces, hypertext, multimedia, and different ways of indexing and accessing information • Written in Java, it can either be run over the web [high bandwidth] or run locally (here Java’s main advantage is cross-platform support).
Overview Kirrkirr provides various modules • Animated Graph layout of word relationships • Formatted dictionary entries • A notes facility for ‘jotting in the margin’ • Multimedia: audio, pictures • Advanced searching interfaces • others in planning: formatting (XSL) editing, figuration patterns, semantic domain browsing • These attempt to cater to users with different interests and competence levels
The lexical database • Original materials are stored in an ad hoc format of markup using backslash codes with some (rather odd) nesting of structural tags • These were converted to XML using an error-correcting stack-based parser (written in PERL). • The inconsistency and flexibility of dictionary entries actually made this a surprisingly difficult task. • But parser tries to impose data integrity • Use of XML gives a clear structure to the lexical data, and makes available many (free) tools
XML • XML separates the structure of the data from its presentation • Much of the recent enthusiasm for XML has centred around representing simple and rigid structures such as database records • Dictionary entries are thoroughly suited to XML • rich hierarchical structure • entires vary greatly depending on the word being defined • Result remains a portable, tangible text file
Alternative: a standard database • Has clear advantages: structure, indexing, query language, relationships, integrity. • Many people have suggested using a database for lexical data and some have actually done it (IITLEX, Austin and Nathan) • But in general lexicographers oppose the rigidity, and, in practice, standard relational databases are quite ill-suited to dictionaries • Dictionary entries vary enormously in structure • A Database model is inflexible to extending the dictionary structure • Lessens portability
Alternative: Object Databases • Dictionary can be viewed as a set of entries (objects) • Problems: off-the-shelf products not widely accepted • retrieval via customised query languages • Proprietary storage formats reduce portability • ObjectStore, Versant, Objectivity the main big vendors • Restricted API places limits on extensibility • Generic object browsers not suitable for dictionaries
XML database • Document Object Model widely accepted • XML document can be searched and accessed • XML tools such as XML Parsers, XSL processors are freely available and easy to use • Query languages on the way • XQL: a recent (and evolving) W3C proposal for querying XML documents
XQL - Potential • An alternative to investigate for the future is using a standard query language – such as XQL – to get material out of the XML dictionary, rather than using our ad hoc index. • At the moment not a huge issue since most retrieval is focussed on components of a particular word • XQL standard not stable yet • Very preliminary implementations from vendors
XML indexing - challenges • Despite the various XML parsers available, it is surprising that there has been little consideration in making single entries retrievable from the file • Present XML Parsers tend to put the entire XML document in memory (or its parsed tree form), before the data extraction process begins • This is not practical when parsing significant XML databases (e.g., the Warlpiri dictionary is approx. 10Mb).
XML Indexing - solutions • The hierarchical structure of XML lends itself to indexing, as each separate entry in the XML file can be considered as a separate entity • To make the Warlpiri dictionary usable for Kirrkirr an ad hoc indexing system was developed • Uses a slightly modified Ælfred XML parser • Entries are indexed by headword in a separate index file • The system returns an XML document object containing the single dictionary entry, facilitating: • processing for related words (Graph layout) • XSL processing to HTML
Kirrkirr’s XML Index Process Index in Memory XML Formatted Warlpiri dictionary file headword file position headword file position headword file position <DICTIONARY> <ENTRY> ... </ENTRY> <ENTRY> ... </ENTRY> <ENTRY> ... </ENTRY> </DICTIONARY> Across file system or web Kirrkirr Dictionary Browser XML Parser XML Document Object
Kirrkirr Index Processing • The use of the XML indexing process considerably improves efficiency as only requested entries are parsed, hence conserving time and bandwidth • Once whole entries are parsed, they are kept temporarily in a cache • Thus Kirrkirr uses XML as a median between the structure and indexing of a relational database, with the freedom and functionality of text.
Visualisation of dictionary information • For dictionaries with simple textual content behind them, there is little that can be done but an on-line reflection of a printed page • We present much more than just definitions of words • we want to know their relationships to other words, and the patterning in these relationships • In a computational approach, the program can mediate between the lexical data and the user • The interface can select from and choose how to present information (according to the user’s preferences) – in many different ways
Previous work • Current systems present the search-dominated interface of classic Information Retrieval systems: you type a word in a search box • Results try to mimic, but are generally inferior to, the printed version of the dictionary • But these systems do little to utilise the captivating qualities of computers: interactivity, user control and adaptability (Brown 1985).
Previous work (2) • Search-oriented systems are only effective when user has a clearly specified information need – even here, we are ignoring the distinction between information gained and knowledge sought (Sharpe 1995) • Lack browsing, and chances for incidental or curiosity driven learning • We wish to exploit the essence of hypertext, which is “click to explore” browsing
Graph-based visualisation • There is a little previous work on graphical representations of dictionaries • For instance, the visual-thesaurus by plumbdesign derived from WordNet • But it is also a good demonstration of how chaotic and confusing graphical interfaces can become.
Graph-based visualisation (Jansz 1998; Jansz, Manning and Indurkhya 1999) • Classic graph layout problem • Adapts work by Eades et al. (1998) and Huang et al. (1998) on visualisation and navigation of WWW document linkages • Uses the spring algorithm. Big advantage is that it is an iterative updating algorithm, and so gives an easy interactivity: • it wiggles and people can play with it. • Clarity and simplicity of graph: Software maintains a set of focus nodes to prevent overcrowding
Educational advantages • Alphabetical order is important, but • A web of words offers other effective opportunities for learning • A student can opportunistically explore words that are related in various ways • Important semantic relationships can be understood
Formatted dictionary entries • Are produced automatically from the XML by using XSL (via James Clark’s XT) • XSL allows easy modelling of some user preferences. • Most trivially, one can leave out information such as part of speech, or detailed definitions, which we do by providing several stylesheets to choose from • This is useful as many users find information overload quite confusing and demotivating • Can produce bilingual or monolingual dictionary • Opportunities for various output styles, and formats such as RTF or TeX for printing.
Rich typology of link types • The semantically rich types of linkages present in a dictionary (synonym, antonym, hyponym, subheadword, variant, coverbs, …) solves one of the major problems of the web: we have many link types with a clear semantic interpretation • Use consistent colour-coded text and edges to show these link types • Gives a richer browsing experience • Unlike HTML, you can tell where you are going before clicking
Browsing • Work (at PARC and elsewhere: Pirolli et al. 1996) has stressed role for browsing as well as searching in information access • It provides a context for learning • We provide browsing in several ways: • network-based display of words • conventional hypertext • but with rich semantically-interpreted links • their colour-coding matches network edges • Other methods being investigated: • browsing through semantic domains • deriving terminology sets (words that are used together in culturally important activities) automatically from text corpora
Multimedia (currently pictures and audio) Can hear pronunciations - enables better understanding than phonetic symbols pictures of plants and animals are more intelligible than descriptions (future: videos of Warlpiri sign language …) Advanced search page search various fields, regular expressions, fuzzy spelling etc. Notes: one can annotate dictionary entries (to correct or personalise) Other components
User study Mim Corris (Yuendumu, Willowra) Jane Simpson (Lajamanu) • User testing with primary and (lower) secondary students • Observation of trainee Warlpiri literacy workers • Comments from teachers, other adults etc. • Purely qualitative observational study of dictionary use. (Doing anything much else would be difficult.) • Initial reactions are very enthusiastic • Could use as a basis for classroom activities (better with some further development: games and puzzles)
A positive anecdote “One of the introductory Warlpiri literacy students, who had not been very interested in the literacy class, spent nearly 3/4 hour looking at Kirrkirr apparently in absorbed concentration. She wasn’t especially interested in the sound and picture possibilities. She moved between words, scrolling along the list, typing in the search, clicking on the words in the network pane. She wasn’t even put off when the dictionary definitions stopped appearing – looking at the networks of words instead. This is quite unlike her attitude to the backslash coded electronic dictionary (where she lost interest quickly because of the difficulty for her of narrowing down searches). After the Kirrkirr demo she asked if she could have a printed dictionary to take away with her to use in camp to learn the words. I interpret this as a desire to learn words in her own time and place.”
Conclusions • Kirrkirr is just a prototype of what one can do to develop new ways to visualise lexicons • We have addressed the challenge of making dictionary information usable in the creation of an application which mediates between well-structured data and users’ needs for searching/browsing and presentation • While we have focused our research on Warlpiri, the system can be easily applied to other languages
Conclusions (cont.) • “... The best future applications of MRDs in education will be those most able to respond to the insights and needs of their users” (Kegl 1995) • Kirrkirr can be seen as a step towards the future of edictionaries
Links • Kevin’s Thesis Homepage:http://www.cs.usyd.edu.au/~kjansz/thesis • Kirrkirr homepage:http://www.sultry.arts.usyd.edu.au/kirrkirr
Kirrkirr: A Java-based visualisation tool for XML dictionaries of Australian Languages Kevin Jansz Department of Computer Science, University of Sydney, Australia Christopher Manning Computer Science and Linguistics, Stanford University, USA Nitin Indurkhya School of applied Science, Nanyang Technological University, Singapore