Download

1 / 30
300 likes | 412 Vues
Breaking the Memory Wall for Scalable Microprocessor Platforms. Wen-mei Hwu with John W. Sias, Erik M. Nystrom, Hong-seok Kim, Chien-wei Li, Hillery C. Hunter, Shane Ryoo, Sain-Zee Ueng, James W. Player, Ian M. Steiner, Chris I. Rodrigues, Robert E. Kidd,

E N D
Breaking the Memory Wall for Scalable Microprocessor Platforms Wen-mei Hwu with John W. Sias, Erik M. Nystrom, Hong-seok Kim, Chien-wei Li, Hillery C. Hunter, Shane Ryoo, Sain-Zee Ueng, James W. Player, Ian M. Steiner, Chris I. Rodrigues, Robert E. Kidd, Dan R. Burke, Nacho Navarro, Steve S. Lumetta University of Illinois at Urbana-Champaign
Semiconductor computing platform challenges S/W inertia O/S limitations reliability feature set performance security accelerators power cost Reconfigurability Microprocessors Mem. Latency/Bandwidth Power Constraints Intelligent RAM DSP/ASIP wire load fab cost leakage process variation billion transistors
ASIC/ASIP economics • Optimistically, ASIC/ASSP revenues growing 10–20% / year • Engineering portion of budget is supposed to be trimmed every year (but never is) • Chip development costs rising faster than increased revenues and decreased engineering costs can make up the difference • Implies 40% fewer IC designs (doing more applications) - every process generation!! Total ASIC/ASSP Revenues 10-20% 5-20% Engineering Costs × ≤ Number of IC Designs 40% Per-chip Development Cost 30-100%
Micro engine Micro engine Micro engine Micro engine SPI4 / CSIX RFIFO TFIFO Micro engine Micro engine Micro engine Micro engine XScale Core PCI Hash Engine Micro engine Micro engine Micro engine Micro engine Scratch- pad SRAM RDRAM RDRAM RDRAM Micro engine Micro engine Micro engine Micro engine CSRs QDR SRAM QDR SRAM QDR SRAM QDR SRAM ASIPs: non-traditional programmable platforms Level of concurrency mustbe comparable to ASICs ASIPs will be on-chip, high-performance multi-processors
Example embedded ASSP implementations VLIW MIPS Philips Nexperia (Viper) Intel IXP1200 Network Processor
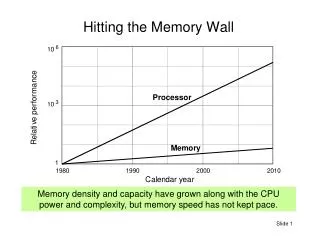
What about the general purpose world • Clock frequency increase of computing engines is slowing down • Power budget hinders higher clock frequency • Device variation limits deeper pipelining • Most future perf. improvement will come from concurrency and specialization • Size increase of single-thread computing engines is slowing down • Power budget limits number of transistors activated by each instruction • Need finer-grained units for defect containment • Wire delay is becoming a primary limiter in large, monolithic designs • The approach to covering all applications with a primarily single execution model is showing limitations
Impact of Transistor Variations 1.4 Frequency ~30% Leakage Power ~5X 30% 1.3 1.2 130nm Normalized Frequency 1.1 1.0 5X 0.9 1 2 3 4 5 Normalized Leakage (Isb) Source: Shekhar Borkar, Intel
Metal Interconnects 1000 1 100 Low-K ILD Line Res (Relative) Line Cap (Relative) 0.5 10 1 0 500 250 130 65 32 500 250 130 65 32 100 10000 Interconnect RC Delay 1000 Clock Period RC Delay (Relative) 10 100 Delay (ps) Copper Interconnect 0.7x Scaled RC Delay 10 RC delay of 1mm interconnect 1 1 500 250 130 65 32 350 250 180 130 90 65 Source: Shekhar Borkar, Intel
Measured SPECint2000 Performanceon real hardware with same fabrication technology Date: October 2003
General processor cores • Very low power compute and memory structures • O/S provides lightweight access to custom features Application processors • Lightweight compute engines • High-bandwidth, distributed storage (RAM, registers) • High-bandwidth, scalable interconnect Memory system • Data delivery to processor • O/S and virtual memory issues • Intelligent memory controllers Acceleration logic • Application specific logic • High-bandwidth, distributed storage (RAM, registers) • To developer, behave like software components Convergence of future computing platforms
Breaking the memory wall withdistributed memory and data movement
Parallelization with deep analysis: Deconstructing von Neumann [IWLS2004] • Memory dataflow that enables • Extraction of independent memory access streams • Conversion of implicit flows through memory into explicit communication • Applicability to mass software base requires pointer analysis, control flow analysis, array dependence analysis CPU CPU DRAM PE’s DRAM Az_4 PE’s Az_4 Weight_Ai (Az, F_ga3, Ap3) Weight_Ai (Az, F_g4, Ap4) synth synth Residu (Ap3, &syn_subfr[i],) res2 res2 Copy (Ap3, h, 11) Weight_Ai Weight_Ai Set_zero (&h[11], 11) m_syn m_syn (Ap4, h, h, 22, &h) Syn_filt Copy+ F_g3 Residu F_g3 Set_zero tmp = h[0] * h[0]; for (i = 1 ; i < 22 ; i++) tmp = tmp + h[i] * h[i]; F_g4 F_g4 tmp1 = tmp >> 8; Syn_filt tmp = h[0] * h[1]; for (i = 1 ; i < 21 ; i++) syn syn D R A M tmp = tmp + h[i] * h[i+1]; tmp2 = tmp >> 8; Corr0/Corr1 if (tmp2 <= 0) Ap3 Ap3 tmp2 = 0; else tmp2 = tmp2 * MU; Ap4 preemph Ap4 tmp2 = tmp2/tmp1; preemphasis (res2, temp2, 40) h h Syn_filt Syn_filt (Ap4, res2, &syn_p), tmp tmp 40, mem_syn_pst, 1); tmp1 tmp1 agc (&syn[i_subfr], &syn) agc 29491, 40) tmp2 tmp2
+ + preemphasis * res Memory bottleneck example(G.724 Decoder Post-filter, C code) • Problem: Production/consumption occur with different patterns across 3 kernels • Anti-dependence in preemphasis function (loop reversal not applicable) • Consumer must wait until producer finishes • Goal: Convert memory access to inter-cluster communication Residu Syn_filt * * * * * * * [39:0] [39:0] [0:39] [0:39] MEM time
+ + * Breaking the memory bottleneck • Remove anti-dependence by array renaming • Apply loop reversal to match producer/consumer I/O • Convert array access to inter-component communication Residu * * * preemphasis res Syn_filt res2 * * * * time Interprocedural pointer analysis + array dependence test + array access pattern summary+ interprocedural memory data flow
Full system environment Linux running on PowerPC Lean system with custom Linux (Nacho Navarro, UIUC/UPC) Virtex 2 Pro FPGA logic treated as software components Removing memory bottleneck Random memory access converted to dataflow Memory objects assigned to distributed Block RAM SW / HW communication PLB vs. OCM interface A prototyping experience with the Xilinx ML300
Projected filter latency 16000 15000 14000 Cycles 3000 ~8x 2000 ~32x 1000 0 Software Naïve Optimized Initial results from our ML300 testbed • Case study: GSM vocoder • Main filter in FPGA • Rest in software running under Linux with customized support • Straightforward software/ accelerator communications pattern • Fits in available resources on Xilinx ML300 V2P7 • Performance compared to all-software execution, with communication overhead Hardwareimplementation
Grand challenge • Moving the mass-market software base to heterogeneous computing architectures • Embedded computing platforms in the near term • General purpose computing platforms in the long run Applications and Systems Software Platforms OS support Programming models Accelerator architectures Restructuring compilers Communications and storage management
Taking the first step: pointer analysis • To what can this variable point? (points-to) • Can these two variables point to the same thing? (alias) • Fundamental to unraveling communications through memory: programmers like modularity and pointers! • Pointer analysis is abstract execution • Model all possible executions of the program • Has to include important facets, or result won’t be useful • Has to ignore irrelevant details, or result won’t be timely • Unrealizable dataflow = artifacts of “corners cut” in the model • Typically, emphasis has been on timeliness, not resolution, because expensive algorithms cause unstable analysis time – for typical alias uses, may be OK… • …but we have new applications that can benefit from higher accuracy • Data flow unraveling for logic synthesis and heterogeneous systems
How to be fast, safe and accurate? • An efficient, accurate, and safe pointer analysis based on the following two key ideas Efficient analysis of a large program necessitates that only relevant details are forwarded to a higher level component The algorithm can locally cut its losses (like a bulkhead) … … to avoid a global explosion in problem size
One facet: context sensitivity Example • Context sensitivity – avoids unrealizable data flow by distinguishing proper calling context • What assignments to a and g receive? • CI: a and g each receive 1 and 3 • CS: g receives only 1 and a receives only 3 • Typical reactions to CS costs • Forget it, live with lots of unrealizable dataflow • Combine it with a “cheapener” like the lossy compression of a Steensgaard analysis • We want to do better, but we may sometimes need to mix CS and CI to keep analysis fast Desired results
Context Insensitive (CI) • Collecting all the assignments in the program and solving them simultaneously yields a context insensitive solution • Unfortunately, this leads to three spurious solutions.
Context Sensitive (CS): Naïve process Excess statements unnecessary and costly Retention of side effect still leads to spurious results
CS: “Accurate and Efficient” approach Compact summary of jade used Summary accounts for all side-effects. DELETE assignment to prevent contamination Now, only correct result derived
Analyzing large, complex programs[SAS2004] Originally, problem size exploded as more contexts were encountered 1012 This results in an efficient analysis process without loss of accuracy 104 New algorithm contains problem size with each additional context
Example application and current challenges[PASTE2004] Improved efficiency increases the scope over which unique, heap-allocated objects can be discovered Example: Improved analysis algorithms provide more accurate call graphs (below) instead of a blurred view (above) for use by program transformation tools
systems systems Applications Operating systems systems Compiler systems systems Runtime and Tools Libraries systems Hardware From benchmarks to broad application code base • The long term trend is for all code to go through a compiler and be managed by a runtime system • Microsoft code base to go through Phoenix – OpenIMPACT participation • Open source code base to go through GCC/OpenIMPACT under Gelato • The compiler and runtime will perform deep analysis to allow tool to have visibility into software • Parallelizers, debuggers, verifiers, models, validation, instrumentation, configuration, memory managers, runtime, etc.
Global memory dataflow analysis • Integrates analyses to deconstruct memory “black box” • Interprocedural pointer analysis: allow programmer to use language and modularity without losing transformability • Array access pattern analysis: figure out communication among loops that communicate through arrays • Control and data flow analyses: enhance resolution by understanding program structure • Heap analysis extends analysis to much wider software base • SSA-based inductor detection and dependence test have been integrated into IMPACT environment
Example on deriving memory data flow main(...) { int A[100]; foo(A, 64); bar(A+1, 64) } foo writes A[0:63] stride 1 bar reads A[1:64] stride 1 procedure call Data flow analysis determines that A[64] is not from foo parameter mapping foo (int *s, int L) { int *p=s, i; for (i=0; i<L; i++) *p = ...; p++; } Write from *(s) to *(s+L) with stride 1 Procedure body Read from *(t) to *(t+M) with stride 1 summary for the whole loop Pointer relation analysis restates p/q in terms of s/t bar (int *t, int M) { int *q=t, i; for (i=0; i<M; i++) … = *q; q++; } Write *p loop body Read *q
Conclusions and outlook • Heterogeneous multiprocessor systems will be the model for both general purpose and embedded computing platforms in the future • Both are motivated by powerful trends • Shorter term adoption for embedded systems • Longer term for general purpose systems • Programming models and parallelization of traditional programs to channel software to these new platforms • Feasibility of deep pointer analysis demonstrated • Many need to participate in solving this grand challenge problem