Download

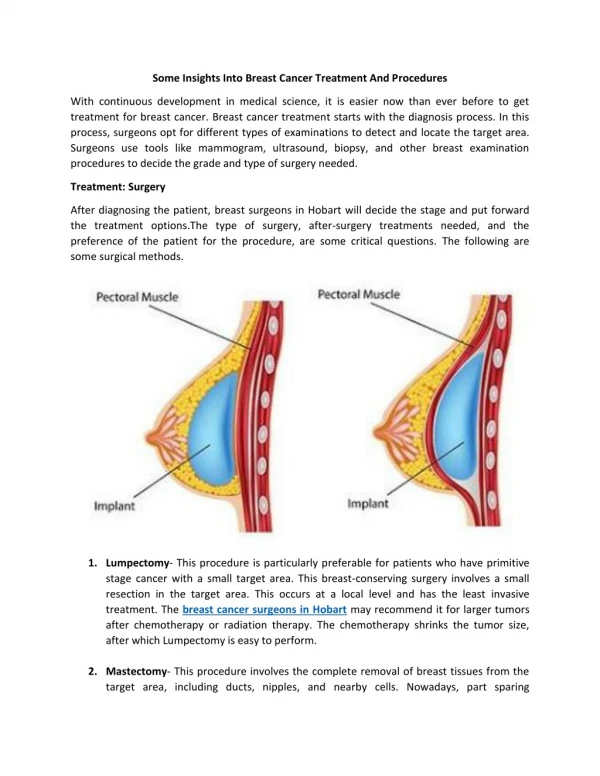
1 / 19
190 likes | 200 Vues
Some Insights into Data Weighting in Integrated Stock Assessments. André E. Punt 21 October 2015. Index-1 length-4. Background. “Integrated” models potentially involve numerous data sources: Indices of abundance (CPUE, surveys)

E N D
Some Insights into Data Weighting in Integrated Stock Assessments André E. Punt 21 October 2015 Index-1 length-4
Background • “Integrated” models potentially • involve numerous data sources: • Indices of abundance (CPUE, surveys) • Length-composition data • Age-composition data • Discards • Mean body weight • Conditional age-at-length data • Moreover, each data source may be • available for more than one “fleet” Johnson et al. PFMC Sablefish Assessment
Objectives • Outline alternative methods of weighting for: • Length- and age-composition data • Conditional age-at-length data • Evaluate the performance of these methods given model mis- • specification.
Methods for tuning length (and age) composition data-I Let be the observed proportion of animals in length-class L during year y, and be the model-predicted proportion of animals in length-class L during year y. Under the assumption that length samples are multinomial (as is the case in Synthesis, ASAP, etc), the weight assigned to the data is the “effective sample size”, : where the are the input effective sample sizes.
Methods for tuning length (and age) composition data-II McAllister-Ianelli: This method sets the effective sample size by comparing the residual variance with the variance expected under a multinomial distribution: To compute an overall effective sample size, , it is necessary to average over the . Two options are commonly used: McAllister-Ianelli-1: McAllister-Ianelli-2:
Methods for tuning length (and age) composition data-III But residuals for length-compositions are seldom uncorrelated between length-classes – enter “Francis weighting”. The idea behind Francis weighting is to base on the mean age or length, i.e.: where is the mid-point of length-class L.
Methods for tuning conditional age-at-length-I Conditional age-at-length (CAL) data are (essentially) age-length keys. These data provide information on year-class strength and growth. CAL data are matrices by year, which makes application of standard weighting schemes difficult.
Methods for tuning conditional age-at-length-II Let be the observed proportion of animals in length-class L during year y that are of age a, and be the model-predicted proportion of animals in length-class L during year y that are of age a. Under the assumption that age samples are multinomial conditional on length, the negative log-likelihood is: where the are the input effective sample sizes.
Methods for tuning conditional age-at-length-III The McAllister-Ianelli and Francis methods can be extended (naively) to handle conditional age-at-length data: McAllister-Ianelli: McAllister-Ianelli-1: McAllister-Ianelli-2: Francis-A:
Methods for tuning conditional age-at-length-IV The Francis-A can be criticised because it treats each row of an age-length key as being independent. This is unlikely to be true. The Francis weighting method for length (and age) data can be generalized to age-length keys (Francis-B) by applying the basic algorithm to the mean age of the age-length key, i.e.: where: is the fraction of animals during year y observed to be in length-class L.
Simulation StudY EVALUATION consciouslyenlightened.com www.scottmcd.net
Simulation Details-I • Spatial structure: • One zone OR • Two zones with spatial variation in F • Fleet structure: • Non-trawl fleet • Trawl fleet • Data (by fleet and zone): • CPUE series (all years; CV = 0.1) • Length frequencies (all years; = 100) • Age-at-length data (50% of year-fleet-zone combinations; = 500) • Logistics: • 100 simulations • Single-area estimation method • Performance measure: spawning biomass (summed over zones).
Tuning algorithms Each tuning algorithm (except Francis / Francis-A*) is applied five times • McAllister-Ianelli-1: Tune the residual variance for the CPUE data and use the McAllister-Ianelli-1 method for both length and CAL data. • McAllister-Ianelli-2: As for McAllister-Ianelli-1 except use the McAllister-Ianelli-2 method for both length and CAL data. • Francis / Francis-A: As for McAllister-Ianelli-1 except use Francis weighting for the length data and Francis-A weighting for the CAL data. • Francis / Francis-B: As for McAllister-Ianelli-1 except use Francis weighting for the length data and Francis-B weighting for the CAL data.
Results: One-zone operating model • The estimation model is not mis-specified so the correct effective sample sizes are known. This allows some questions about the “in principle” performance of the methods (and tuning algorithms) to be explored. • Does estimation performance depend on the initial weights? • Yes – results not shown here • Does estimation performance depend on the tuning algorithm? • Yes – results not shown here • Which method for calculating weights performs best?
The one-zone operating model McAllister-Ianelli-1 is biased for both length-frequency and conditional age-at-length data. McAllister-Ianelli-2 performs best at calculating effective sample sizes for length data (Francis is unbiased, but imprecise). McAllister-Ianelli-2 performs best at calculating effective samples for conditional age-at-length data (Francis-A and Francis-B are unbiased, but imprecise).
The two-zone operating model The untuned method performs poorer than when tuning is applied (except for when McAllister-Ianelli-1 is applied). McAllister-Ianelli-1 leads to the poorest performance. Francis / Francis-B leads to estimates with least bias for final spawning biomass (and final / initial spawning biomass), but not by much.
The two-zone operating model • With model-specification: • Francis leads to lower weights than McAllister-Ianelli-1 • Francis-B leads to lower weights than Francis-A and McAllister-Ianelli-2. • Francis and Francis-B are imprecise (compared to McAllister-Ianelli-2 and Francis-A). • We don’t know the correct effective sample size for this case.
Overall conclusions • General • Avoid McAllister-Ianelli-1 (averaging of effective sample sizes). • McAllister-Ianelli-2 (harmonic mean) performs adequately over all cases (but was not optimal when there was model mis-specification). • Francis / Francis-B was the least biased tuning algorithm, but the estimates of effective sample size showed the highest between-simulation variation
Questions & Acknowledgements This work was partially supported by NOAA grant NA10OAR4320148 Chris Francis is thanked for discussions that led to the Francis-A and Francis-B methods.