Download
1 / 23
230 likes | 245 Vues
Chapter 25: Distributed Databases. Definitions. Distributed Database – a collection of of multiple logically interrelated databases distributed over a computer network

E N D
Definitions • Distributed Database– a collection of of multiple logically interrelated databases distributed over a computer network • Distributed Database Management System – A software system that manages a distributed database while making he distribution transparent to the user.
Motivations for Distributed DBs • No centralized point of failure. • Local Autonomy. • There’s a whole lot of data out there to store. • Replication of Data for Disaster Recovery and High Availability (think RAID on a network) • High-throughput query processing (either inter-query or intra-query parallelism), dynamic load-balancing, • Poor people can’t afford supercomputers.
Drawbacks of DDBs: • Security • Increased complexity of Database Design • Increased complexity of Software • Data integrity and resolution of concurrent operations. • Cost (But if you’re big enough to need one, you probably can afford one?)
Transparency: Transparency of Data: • Location Transparency – A command works the same no matter where in the system it is issued • Naming Transparency – We can refer to data by the same name, from anywhere in the system, with no further specification. • Replication Transparency – Hides multiple copies of data from user • Fragmentation Transparency – Hide the fact that data is fragmented (ie, different sections of correlated data may be in different locations)
Two Fundamental Patterns for Fragmenting Data • Horizontal – Store Whole Tuples on Different machines. • Nice because we can use standard relational algebra statements to define a restriction on a relation that creates these: • s”newyork” (City) s “chicago” (City) (Do we need to know all possible values for City in order to fully specify a fragmentation.)
Vertical – Store Different Fields of the same tuples on Different machines. Use Projection Op to declare these: P (Acct #, Branch, Client Name Account) P (Acct #, Balance Account) (Notice this requires redundant storage of at least one primary key per tuple)
Redundant / Non-Redundant Allocations: • Full Replication (Completely Redundant) • Good read time, good recoverability • Requires more coordination for multiple writers on same data, hogs disk space • No Replication (Non-Redundant) • Easier to coordinate multiple writers, multiple readers. But no backup in case of disaster. • Partial Replication • Trade-off between the above two options.
Global Directory • Global Centralized (Why have a DDBMS at all if you’re going to do this?) • Dispersed or no Global Directory • Completely Replicated • Local-Master Directory • Each node has its own catalog of data • Each node has a directory to all of its data that is replicated elsewhere.
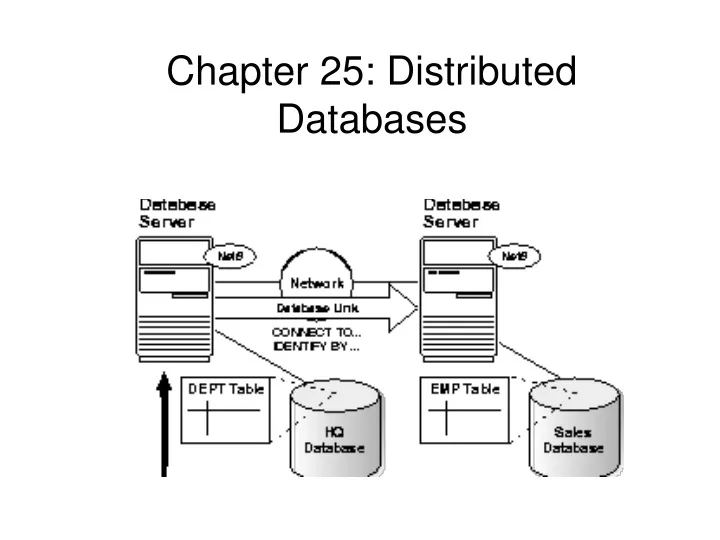
Each database in a distributed database is distinct from all other databases in the system and has its own global database name.
Name Resolution in Oracle8 • Every data object in every schema in every database has a unique identifying name: • SELECT * FROMscott.emp@sales.us.americas.acme_auto.com; • A remote query is a query that selects information from one or more remote tables, all of which reside at the same remote node. For example: • SELECT * FROM scott.dept@sales.us.americas.acme_auto.com;
Remote and Distributed SQL Statements in Oracle8 • A remote update is an update that modifies data in one or more tables, all of which are located at the same remote node. For example: • UPDATE scott.dept@sales.us.americas.acme_auto.com SET loc = 'NEW YORK' WHERE deptno = 10; • A distributed query retrieves information from two or more nodes. For example: • SELECT ename, dname FROM scott.emp, scott.dept@sales.us.americas.acme_auto.com d WHERE e.deptno = d.deptno;
A distributed update modifies data on two or more nodes. A distributed update is possible using a PL/SQL subprogram unit, such as a procedure or trigger, that includes two or more remote updates that access data on different nodes. For example: BEGIN UPDATE scott.dept@sales.us.americas.acme_auto.com SET loc = 'NEW YORK' WHERE deptno = 10; UPDATE scott.emp SET deptno = 11 WHERE deptno = 10; END;
2-Phase Commit Process • Easy to trigger with the COMMIT directive. • The Recoverer (RECO) background process on each server involved in the transaction coordinates to resolve any in-doubt transactions. • All RECOs either commit or roll-back the change in a consistent manner.
Data Warehousing “a subject-oriented, integrated, nonvolatile, time-variant collection of data in support of managements decisions” • Decision Support Systems or Executive Information Systems • Online Analytical Processing (OLAP) analysis of complex data from a data warehouse
Data Warehouses • Optimized for providing general information about large data sets instead of explicit information about individual data records • Multidimensional Matrices called Data Cubes (or hypercubes) • Efficient storage, data marts, distributed DW, federate DW
Some steps in Data Acquisition • Data is extracted (from multiple heterogeneous sources) • Data must be formatted • Data must be cleaned (the most involved step) Data can be backflushed to its source after cleaning. • Data must be converted from its source (relational, OO, hierarchical) to the DW’s multidimensional scheme. • The data must actually be loaded.
Basic Operations • Pivot (rotate) • Roll-Up (grouping) • Drill-Down (subdivision) • Slice and dice: Perform projection operations on dimensions. • Sort (data, by some criteria) • Select Data (by value or range)
Chunk-Offset Compression Only stores the addresses and data for valid cells in each chunk in a (offset, cellValue) format Heum-Geun Kang and Chin-Wan Chung, Exploiting versions for on-line data warehouse maintenance in MOLAP servers, VLDB, 2002.
Multidimensional Schema • Components: • Dimension Tables – tuples of attributes of the dimension • Fact Table – Holds tuples that correspond to recorded facts. • Patterns: • Star Schema – A single table for each dimension. • Snowflake Schema – obtained by normalizing a star schema, creating a new hierarchy of multiple dimensional tables • Fact Constellation – A set of fact tables that share some dimension tables
Data Warehousing vs. Materialized Views • DWs exist as persistent storage instead of being materialized on-demand. • DWs are multidimensional, not relational. Views of a relational database are relational. • DWs can be indexed to optimize performance. Views are dependant on the structure of the underlying database. • DWs contain compositions of data collected from multiple datasources. Views are derived from a single database.






















