Download
1 / 25
260 likes | 360 Vues
c. b. a. d. T 1. T 1. T 2. T 2. savings. checking. Section 8 # 20. 08_Transactions_LECTURE3. Deadlock Management. Deadlocks can occur when a WAITING POLICY is used for CC. How can deadlocks be PREVENTED (precluding the possibly of one ever happening),

E N D
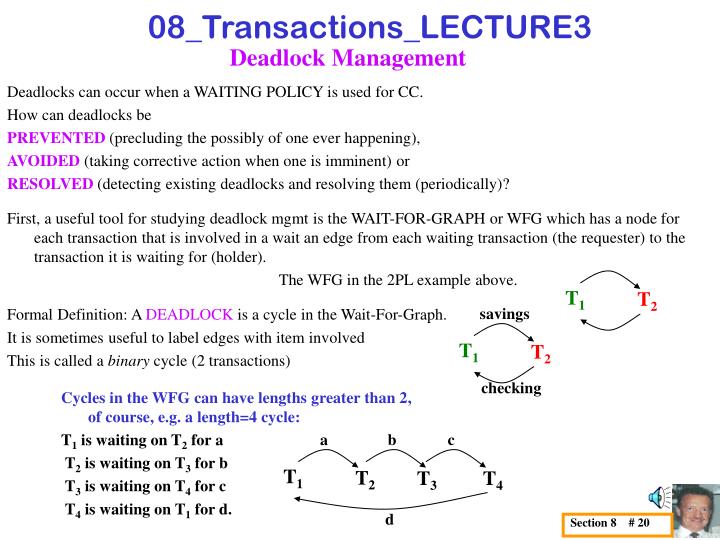
c b a d T1 T1 T2 T2 savings checking Section 8 # 20 08_Transactions_LECTURE3 Deadlock Management Deadlocks can occur when a WAITING POLICY is used for CC. How can deadlocks be PREVENTED (precluding the possibly of one ever happening), AVOIDED(taking corrective action when one is imminent) or RESOLVED (detecting existing deadlocks and resolving them (periodically)? First, a useful tool for studying deadlock mgmt is the WAIT-FOR-GRAPH or WFG which has a node for each transaction that is involved in a wait an edge from each waiting transaction (the requester) to the transaction it is waiting for (holder). The WFG in the 2PL example above. Formal Definition: A DEADLOCK is a cycle in the Wait-For-Graph. It is sometimes useful to label edges with item involved This is called a binary cycle (2 transactions) Cycles in the WFG can have lengths greater than 2, of course, e.g. a length=4 cycle: T1 is waiting on T2 for a T2 is waiting on T3 for b T3 is waiting on T4 for c T4 is waiting on T1 for d. T1 T2 T3 T4
Construction Zone Section 8 # 21 Deadlock Prevention Deadlock Prevention Action is taken to prevent even the possibility of a deadlock. E.g., flu shot is a preventative action (you may not have gotten the flu anyway) 1. Transaction Scheduling (Transactions obtain access to all needed data items before beginning execution AKA C2PL). Transaction Scheduling: a. prevents deadlocks. b. comes from construction zone management: Need GO permission from both flag persons before proceeding into the zone.
Section 8 # 22 Other Deadlock Prevention Methods: 2. Serial Execution (prevents deadlock) 3. Wond-Wait and Wait-Die are timestamp-based prevention methods to decide who can wait whenever a conflict arizes. Timestamp = unique ordinal transaction-id or "stamp" (usually start-time i.e., DoB (Date of Birth), so we can talk about one transaction being "older than" another, meaning its timestamp is lower (born before the other) ). WOUND_WAIT: When a requesting trans (the requester) finds that the requested data item is held by another trans (the holder): if REQUESTER is OLDER (has lower timestamp), then REQUESTER WOUNDS HOLDER, else REQUESTER WAITS; where WOUND means holder is given a short time to finish with the item, otherwise it must restart (bleeds to death from wound?) NOTES: WW is a pre-emptive method. The only waits allowed are YOUNGER REQUESTERS waiting for OLDER HOLDERS. Assumes waits are blocking (e.g., if requester waits, it waits idly), there is never a cycle in WFG. Why not? M Luo, M.S. 87; M Radhakrishnan, M.S. 92; and T Wang, M.S. 96 advanced this protocol as their M.S. theses (and also published their results).
Section 8 # 23 Deadlock Prevention Action is taken to prevent even the possibility of a deadlock. 3. Wond-Wait and Wait-Die WAIT_DIE: When a requesting transaction (the requester) finds that the requested data item is held by another transaction (the holder): if the REQUESTER is OLDER (has lower timestamp), then the REQUESTER WAITS, else the REQUESTER DIES; NOTES: WD is non-preemptive. W. Yao modified wound-wait and wait-die to allow forward and backward waiting by introducing an additional parameter assigned to each waiting trans, called "orientation". (Information Science Journal, V103:1-4, pp. 23-26, 1997.)
Wait for C? Wait for A Wait fo B Section 8 # 24 Wait-die • Transactions given a timestamp when they arrive …. ts(Ti) • Ti can only wait for Tj if ts(Ti)< ts(Tj) ...else die T1 (ts =10) T2 (ts =20) T3 (ts =25)
Section 8 # 25 Wait-die-1 requests A: wait for T2 or T3 or both? (in my html notes, I assume both) T1 (ts =22) T2 (ts =20) T3 (ts =25) Note: ts between 20 and 25. wait(A)
wait(A) wait(A) Section 8 # 26 Wait-die-1 One option: T1 waits just for T3, transaction holding lock. But when T2 gets lock, T1 will have to die! (also lots of WFG revision) T1 (ts =22) T2 (ts =20) T3 (ts =25) wait(A)
Section 8 # 27 Wait-die-2 Another option: T1 waits for both T2, T3 E.g., (saves having to revise WFG) T1 allowed to wait iff there is at least one younger trans wait-involved with A. But again, when T2 gets lock, T1 must die! T1 (ts =22) T2 (ts =20) T3 (ts =25) wait(A) wait(A) wait(A)
wait(A) Section 8 # 28 Wait-die-3 Yet another option: T1 preempts T2 (T2 is just waiting idly anyway), so T1 only waits for T3; T2 then waits for T3But,T2 may starve? And lots of WFG work for Deadlock Mgr (shifting edges) T1 (ts =22) T2 (ts =20) T3 (ts =25) wait-A
Section 8 # 29 Wound-wait • Transactions given a timestamp when they arrive … ts(Ti) • Ti wounds Tj if ts(Ti)< ts(Tj) else Ti waits “Wound”: Tj rolls back (if it cannot finish in small interval of time) and gives lock to Ti
Wait C Section 8 # 30 Wound-wait T1 (ts =25) T2 (ts =20) T3 (ts =10) Wait A Wait B
Section 8 # 31 Wound-wait-2 requests A: wait for T2 or T3? T1 (ts =15) T2 (ts =20) T3 (ts =10) Note: ts between 10 and 20. wait(A)
Section 8 # 32 Wound-wait-2 One option: T1 waits just for T3, transaction holding lock. But when T2 gets lock, T1 waits for T2 and wounds T2. T1 (ts =15) T2 (ts =20) T3 (ts =10) Wait A wait(A) wait(A)
Section 8 # 33 Wound-wait-3 Another option: T1 waits for both T2, T3 T2 wounded right away! T1 (ts =15) T2 (ts =20) T3 (ts =10) wait(A) wait(A) wait(A)
Section 8 # 34 Wound-wait-4 Yet another option: T1 preempts T2, so T1 only waits for T3; T2 then waits for T3 and T1... T2 is spared! Lots of WFG work for Deadlock Mgr (shifting edges) and T2 may starve. T1 (ts =15) T2 (ts =20) T3 (ts =10) wait-A wait(A)
Section 8 # 35 Deadlock Avoidance and Detection/Resolution deadlock avoidance (Avoiding all deadlocks. When one is about to happen, take some action to avoid it.) 1. Request Denial: Deny any request that would result in deadlock (This requires having and checking a WaitForGraph (WFG) for a cycle every time a wait is requested.) deadlock detection and resolution All Deadlock detection/resolution protocols use the Wait-For-Graph (WFG). Put an edge in WFG representing each new wait, then periodic analysis WFG for cycles, if one is found, then select a victim transaction to be restarted from each cycle (break the cycle). Victim selection criteria can vary. S ome system use "youngest" others use "oldest", others use "been waiting the longest time" and still others use "been waiting the shortest time".....
Section 8 # 36 Deadlock Management Timeout can also be used to manage deadlocks. 1. When a TRANSACTION BEGINs, a timeout clock is set. If transaction is still active when the timeout clock runs down to zero, then transaction is aborted. 2. When a TRANSACTION has to WAIT, a timeout clock is set. If transaction is still waiting when the timeout clock runs down to zero, then transaction is aborted. (reduces timeout clock overhead). Potential improvements probably leap to mind for 2, e.g., 2.1 only set timeout clock if the item requested is already in LockTable (meaning that there is already a wait in progress for that item). General Notes: Deadlock management is still a very important area of research and there's still much to be done, even though there are many methods described in the literature. One reason: Deadlocks which involves data distributed across a network are a much harder problem than centralized deadlocks. Locking, as a concurrency control method, REQUIRES a CENTRALIZED lock-table object (logically at least) with a SINGLE THREADED lock manager (a monitor or critical section) The Locking protocols presented above are called PESSIMISTIC. OPTIMISTIC locking assumes there will be no conflict and then tests that assumption for validity at COMMIT time. If assumption proved false, entire (completed) transaction is aborted.
Section 8 # 37 Other Concurrency Control Methods BASIC TIMESTAMP ORDERING (BTO) is a RESTART POLICY (no waiting). Each transaction gets a unique timestamp (ts) (usually arrival time). Note that timestamps were introduced already in the context of deadlock management schemes to accompany Locking Concurrency Control. Now we are going to use timestamps for concurrency control itself! (no deadlock management will be necessary here since the CC method is a "restart" method, not a "waiting" method). BTO SCHEDULING DECISION: When Scheduler receives a READ request, it rejects it iff a YOUNGER trans has written that item. When Scheduler receives a WRITE request, it rejects it iff a YOUNGER transaction has written or read that item. NOTES on BTO: Timestamp is usually "arrival time" but can be ANY linear ordering. When the SCHEDULER rejects a request, the requesting transaction restarts. BTO must also schedule accepted operations to DM in timestamp order also. In order to make the SCHEDULE decisions, scheduler must know the timestamp, ts, of last transaction to write each item and ts of last transaction to read each item. Thus, the system must keep both of these "data-item timestamps" for EVERY data item, x, in the system, namely a data item read timestamp, rts(x), and a data item write timestamp, wts(x). Usually these are kept right with the data item as an part of the data item that only the system can access. That takes a lot of extra space e.g. if there are 10 billion data items (records) in the DataBase (not uncommon), data-item-timestamps may take up 160 GB, assuming an 8 byte ts (note that 4 bytes won't do). BTO is a pure RESART policy (uses only restart conflict resolution. BTO CC is deadlock free (since waiting is not used). BTO, however, can experience livelocks (trans continuously restarting for the same reason over and over). BTO results in lower concurrency in central systems (studies have shown) BTO, works better in distributed systems. Why? All the Scheduler has to have in order to make the scheduling decision when a transaction, t asks for a data item, x, is the transaction-timestamp, ts(t), and data-item-write-timestamp, wts(x) (for a read request) and the data-item-read-timestamp, rts(x) and the data_item_write timestamp, wt(x), (for a write request).
Section 8 # 38 DISTRIBUTED BTO SCHEDULERS NEED NO INFORMATION FROM OTHER SITES ts(t) comes along with the transaction, t (part of its identifier) wts(x) and rts(x) are stored with the data item, x, at that site. Again, one can see, that there is system overhead in BTO since EVERY DATA ITEM has to have a read_timestamp (rts) and a write_timestamp (wts) each could be 8 bytes, so additional 16 bytes of system data for each record. A large database can have billions and even trillions of DATA ITEMS (Records). By contrast, a distributed 2PL scheduler must maintain Lock Table at some 1 site. Then any request coming from any site for data at any other site would have to be sent across the network from the request-site to the LT-site and then the reply wold have to be sent from the LT site to the data site(s). However, LT is not nearly as large. One further downside to BTO: The BTO Scheduler must submit accepted conflicting operations to DM in ts-order BTO could issue them in a serial manner: Wait to issue next one until previous is ack'ed. That's very inefficient! (serial execution is almost always inefficent) Usually a complex "handshake" protocol is used to optimize this. DO NOT CONFUSE BTO with Wound-Wait or Wait-Die Deadlock Management! Both are timestamp-based, but BTO is Concurrency Control Scheduler, while WW/WD are deadlock prevention methods (to go with a, e.g., 2PL scheduler)
Section 8 # 39 Optimistic Concurrency Control assumes optimistically, no conflicts will occur. Transactions access data without getting any apriori permissions. But, a Transaction must be VALIDATED when it completes (just prior to COMMIT) to make sure its optimistism was correct. If not, it must abort. VALIDATION (validation must be single threaded - a monitor or mutually excluding): A commiting transaction is "validated" if it is in conflict with no active transaction else it is declared "invalid" and must restarted. So a transaction must list the data items it has accessed and the system must maintain an up-to-date list of "active transactions" with t(ts) and accessed data-item-ids? Basically, an optimistic concurrency control can be thought of as being BTO, in which the "timestamping" is done at its commit time, not at start time, (transaction is validated iff it is not "too late" accessing any of its data) since active transactions are younger than the committing transaction. Validation must be an atomic, single threaded process. Therefore if any active trans has already read a item that the committing trans wants to write (all writes are delayed until validation) it's too late for committing trans to write it in ts order and thus, must be restarted. Note that this is non-prememptive optimistic CC.
Section 8 # 41 CSMA/CD Concurrency control CSMA/CD like CC: Need to write a simple Concurrency Controller (Scheduler) for your boss? This is a very simple and effective SCHEDULER (no critical section coding required) in which cooperating TMs do "self service" 2PL using the ethernet LAN CSMA/CD protocol CSMA/CD = Carrier Sense Multiple Access with Collision Detect CSMA/CD-Concurrency Control: A cooperating TM, t, seeks access to item, x, it will: 1. Check availability of x (analogous with "carrier sensing") (Is another trans using it in a conflicting mode?). 2. If x is available, set lock on x (TM does this itself! in a LockTable File) else try later (after some backoff random period). 3. Check for collision (with other cooperating trans that might have been setting conflicting locks concurrently (analogous to "collision detecting") 4. If collision, TM removes all lock(s) it set and tries later (after some backoff period). 5. Release all locks after completion (COMMIT or ABORT) (Strict 2PL). (This is a S2PL protocol WITHOUT an active scheduler).
Section 8 # 41 CD Concurrency Control CD like CC continued: To make it even simpler, we can dispense with the carrier sense step: CD-Only Method: When a cooperation trans, t, seeks access to a data item, x, it must: 2. Set lock. 3. Check for collisions. 4. If there is a collision, remove all locks and try later (after backoff). 5. Release all locks after completion (COMMIT or ABORT). (This is also a S2PL protocol without an active scheduler). In fact, one can write this code in SQL, something like: Assume there is a file acting as the LockTable, called LT, such that LT(TID, RID, MODE) where TID is column for the Trans' ID number, RID is column for Record's ID number, and MODE is either "shared" or "exclusive" (S or X). Below shows some of the code for a CD-like CC Method (what additional code would be required for a CSMA/CD like method?). If T7 (transaction with TID = 7) needs an XLOCK on the data item with RID = (53,28), the TM for T7 issues: BEGIN INSERT INTO LT VALUES ('7', '(53,28)', 'X'); V = SELECT COUNT(*) FROM LT WHERE RID='(53,28)'; IF V = 1, THEN COMMT ELSE ABORT (try again later), DELETE FROM LT WHERE TID='7';
Section 8 # 42 Request Order Link List Concurrency Control uses Cooperation Transaction Managers and no Scheduler: (Note this technology - together with a later refinement called ROCC, is patent pending concurrency control technology at NDSU. In reverse time order, it can be called ROCC and ROLL Concurrency Control). A further enhancement of this approach, ROCC and MVROCC are patent pending technologies at this time by NDSU). ROLL is a generalized model which includes aspects of locking and timestamp ordering as well as other methods. ROLL is: 1 non-blocking (no idle waiting) 2 restart free and thus livelock free. 3 deadlock free 4 self-service for trans mgrs (no active singlethread scheduler other than an enqueue operation) 5 very parallel (little critical sectioning) 6 ROLL is easily distributed Data items are requested by a transaction using a REQUEST VECTOR (RV) bit vector. Each data item is mapped to specific bit position using an assignment table (Domain Vector Table or DVT). A 1-bit at a position indicates that that item is requested by the trans and a 0-bit means it is not requested. If read and write modes are to be distinguished, use 2 bits, a read-bit and a write-bit for each item. ROLL could use a bit vector for the items to be read, ReadVector and another bit vector for the items to be written, the WriteVector. ROLL can be thought of as an object with data structure a queue of Request Vectors, one for each transaction. 010010...0 Ti |010010...0 Tj . . . |010010...0 Tk tail
Section 8 # 43 Other Concurrency Control Methods ROLL has 3 basic methods: POST (allows a transaction to specify its requests) POST is an atomic "enqueue" operation (the only atomicity required the only critical section). CHECK (determines availability). CHECK returns the logical OR of all RVs ahead of requesters POSTED vector in the ROLL. The vector resulting from this OR operation is (called the "Access Vector" or AV and represents a "lock table" for that transaction (specifies which items are available and which are not). If we have a separate ReadROLL and WriteROLL, in order to determine what can be read, a trans CHECKs the WriteROLL only and to determine what can be written, a trans CHECKS both WriteROLL and ReadROLL. reCHECKing can be done any time eg., when trans finishes data items found available on first CHECK, it would issue another CHECK expecting that some of the previously unavailable items have become available in the interim.) RELEASE: (releases dataitems to the next requester) RELEASE set some or all of trans' 1-bits to 0-bits. ROLL (Request Order Link List) Concurrency Control VALIDATE: (can be added for optimistic transactions) 1. Optimistic transactions would read data without POSTing 2. Optimistic transactions would buffer all writes until commit 3. Upon reading x, optimistic transaction would record rts(x), by copying the current ROLL tail-pointer. 4. before commit, Optimistic trans would have to VALIDATE VALIDATE: POST its request vector CHECK the intevening ROLL interval from its vector to its reads If there are no intervening writes in conflict with its reads, the Transaction is valid and can be committed, else it must be restarted. A garbage collector can operate in the background to remove zeroed vectors. PROBLEMS? Excessive Vector length for fine data item granularity. 1-bits are most space efficient way to indicate a needed item. Zero-bits are unnecessary except to maintain positional matchup. SOLUTIONS: Partitioning DB (eg, by files or ranges of records within files) Designate a separate ROLL for each partition)
Section 8 Thank you.


















