Download

1 / 25
250 likes | 365 Vues
Enterprise Systems. Distributed databases and systems - DT211 4. Concepts. Distributed Database A logically interrelated collection of shared data (and a description of this data), physically distributed over a computer network. Distributed DBMS

E N D
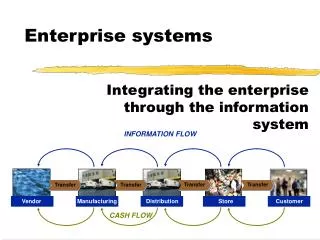
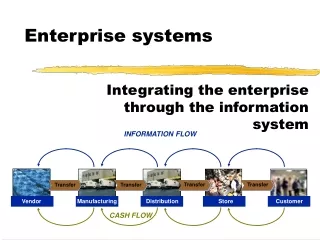
Enterprise Systems Distributed databases and systems - DT211 4
Concepts Distributed Database A logically interrelated collection of shared data (and a description of this data), physically distributed over a computer network. Distributed DBMS Software system that permits the management of the distributed database and makes the distribution transparent to users.
Concepts • Collection of logically-related shared data. • Data split into fragments. • Fragments may be replicated. • Fragments/replicas allocated to sites. • Sites linked by a communications network. • Each DBMS participates in at least one global application.
Advantages of DDBMSs • Reflects organizational structure • Improved shareability and local autonomy • Improved availability • Improved reliability • Improved performance
Disadvantages of DDBMSs • Complexity • Cost • Security • Integrity control more difficult • Database design more complex
Types of DDBMS • Homogeneous DDBMS • Heterogeneous DDBMS • Sites may run different DBMS products, with possibly different underlying data models. • Occurs when sites have implemented their own databases and integration is considered later: ad hoc planning. Enterprise resource planning (ERP) is the new approach that attempts to overcome this problem
Functions of a DDBMS • DDBMS to have at least the functionality of a DBMS. • Also must have following functionality: • Distributed query processing. • Extended concurrency control. • Extended recovery services.
Distributed Database Design • Three key issues: Fragmentation Relation may be divided into a number of sub-relations, which are then distributed. Allocation Each fragment is stored at site with "optimal" distribution (see principles of distribution design). Replication Copy of fragment may be maintained at several sites.
Fragmentation • Quantitative information (replication) used for may include: • frequency with which an application is run; • site from which an application is run; • performance criteria for transactions and applications. • Qualitative information (fragmentation) may include transactions that are executed by application: relations, attributes and tuples.
Correctness of Fragmentation • Three correctness rules: Completeness If relation R is decomposed into fragments R1, R2, ... Rn, each data item that can be found in R must appear in at least one fragment. Reconstruction • Must be possible to define a relational operation that will reconstruct R from the fragments. • Reconstruction for horizontal fragmentation is Union operation and Join for vertical . Disjointness • If data item di appears in fragment Ri, then it should not appear in any other fragment.; Exception: vertical fragmentation, where primary key attributes must be repeated to allow reconstruction. • For horizontal fragmentation, data item is a tuple (row) • For vertical fragmentation, data item is an attribute.
Horizontal Fragmentation • Consists of a subset of the tuples of a relation. • Defined using Selection operation of relational algebra: p(R) • For example: P1 = type='House'(PropertyForRent) P2 = type='Flat' (PropertyForRent) Result (PNo., St, City, postcode,type,room,rent,ownerno.,staffno., branchno.) • This strategy is determined by looking at predicates used by transactions. • Reconstruction involves using a union eg R = r1 U r2
Vertical Fragmentation • Consists of a subset of attributes of a relation. • Defined using Projection operation of relational algebra: a1, ... ,an(R) • For example: S1 = staffNo, position, sex, DOB, salary(Staff) S2 = staffNo, fName, lName, branchNo(Staff) • Determined by establishing affinity of one attribute to another. • For vertical fragements reconstruction involves the join operation; Each fragment is disjointed except for the primary key
Mixed Fragmentation • Consists of a horizontal fragment that is vertically fragmented, or a vertical fragment that is horizontally fragmented. • Defined using Selection and Projection operations of relational algebra: p(a1, ... ,an(R)) or a1, ... ,an(σp(R))
Transparencies in a DDBMS • Distribution Transparency • Fragmentation Transparency • Location Transparency • Replication Transparency • Transaction Transparency • Concurrency Transparency • Failure Transparency
Concurrency Transparency • All transactions must execute independently and be logically consistent with results obtained if transactions executed one at a time, in some arbitrary serial order. • Same fundamental principles as for centralized DBMS. • Replication makes concurrency more complex. • If a copy of a replicated data item is updated, update must be propagated to all copies. • However, if one site holding copy is not reachable, then transaction is delayed until site is reachable.
Failure Transparency • DDBMS must ensure atomicity and durability of global transaction. • Means ensuring that sub-transactions of global transaction either all commit or all abort. • Thus, DDBMS must synchronize global transaction to ensure that all sub-transactions have completed successfully before recording a final COMMIT for global transaction. • Must do this in the presence of site and network failures.
Performance Transparency • Must consider fragmentation, replication, and allocation schemas. • DQP has to decide e.g. : • which fragment to access; • which copy of a fragment to use; • which location to use.
Performance Transparency • DQP produces execution strategy optimized with respect to some cost function. • Typically, costs associated with a distributed request include: • I/O cost; • Communication cost: WAN….
Performance Transparency - Example Property(propNo, city) 10000 records in London Client(clientNo,maxPrice) 100000 records in Glasgow Viewing(propNo, clientNo) 1000000 records in London SELECT p.propNo FROM Property p INNER JOIN Client c INNER JOIN Viewing v ON c.clientNo = v.clientNo) ON p.propNo = v.propNo WHERE p.city=‘Aberdeen’ AND c.maxPrice > 200000; • This query selects properties that viewed in aberdeen that have a price greater than £200, 000.
Performance Transparency - Example Assume: • Each tuple in each relation is 100 characters long. • 10 renters with maximum price greater than £200,000. • 100 000 viewings for properties in Aberdeen. • In addition the data transmission rate is 10,000 characters per sec and there is a 1 sec access delay to send a message.
Performance Transparency - Example • Derive the following :
Parallel Data Management • The argument goes: • if your main problem is that your queries run too slowly, use more than one machine at a time to make them run faster (Parallel Processing). • SMP – All the processors share the same memory and the O.S. runs and schedules tasks on more than one processor without distinction. • in other words, all processors are treated equally in an effort to get the list of jobs done. • However, SMP can suffer from bottleneck problems when all the CPUs attempt to access the same memory at once. • MPP - more varied in its design, but essentially consists of multiple processors, each running their own program on their own memory i.e. memory is not shared between processors. • the problem with MPP is to harness all these processors to solve a single problem. • But they do not suffer from bottleneck problems
There are two possible solutions dividing up the data: Static and Dynamic Partitioning. • InStatic Partitioningyou break up the data into a number of sections. Each section is placed on a different processor with its own data storage and memory. The query is then run on each of the processors, and the results combined at the end to give the entire picture. This is like joining a queue in a supermarket. You stay with it until you reach the check-out. • The main problem with Static Partitioning is that you can’t tell how much processing the various sections need. If most of the relevant data is processed by one processor you could end up waiting almost as long as if you didn’t use parallel processing at all. • In Dynamic Partitioningthe data is stored in one place, and the data server takes care of splitting the query into multiple tasks, which are allocated to processors as they become available. This is like the single queue in a bank. As a counter position becomes free the person at the head of the queue takes that position • With Dynamic Partitioning the performance improvement can be dramatic, but the partitioning is out of the users hands.
Sample type question • Fragmentation, replication and allocation are the three important characteristics discuss their importance in relation to distributed databases.