Download

1 / 43
440 likes | 501 Vues
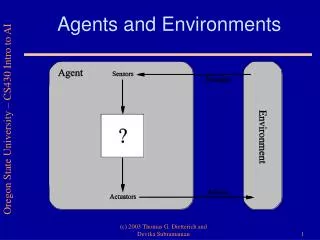
Agents and environments. Environment types. Fully observable (vs. partially observable): An agent's sensors give it access to the complete state of the environment at each point in time .

E N D
Environment types • Fully observable (vs. partially observable): An agent's sensors give it access to the complete state of the environment at each point in time. • Deterministic (vs. stochastic): The next state of the environment is completely determined by the current state and the action executed by the agent. • Episodic(vs. sequential): The agent's experience is divided into atomic "episodes" (each episode consists of the agent perceiving and then performing a single action), and the choice of action in each episode depends only on the episode itself.
Environment types • Static(vs. dynamic): The environment is unchanged while an agent is deliberating. • Discrete (vs. continuous): A limited number of distinct, clearly defined percepts and actions. • Single agent (vs. multiagent): An agent operating by itself in an environment. • Adversarial (vs. benign): There is an opponent in the environment who actively trying to thwart you.
Example • Some of these descriptions can be ambiguous, depending on your assumptions and interpretation of the domain
Environment types Chess with Chess without Taxi driving a clock a clock Fully observable Yes Yes No Deterministic Yes Yes No Episodic No No No Static Semi Yes No Discrete Yes Yes No Single agent No No No? • The real world is partially observable, stochastic, sequential, dynamic, continuous, multi-agent
Games vs. search problems • Search: only had to worry about your actions • Games: opponent’s moves are often interspersed with yours, need to consider opponent’s action • Games typically have time limits • Often, an ok decision now is better than a perfect decision later
Games • Card games • Strategy games • FPS games • Training games • …
Two-Player, Deterministic, Zero-Sum Games • Zero-sum: one player’s gain (or loss) of utility is exactly balanced by the losses (or gains) of the utility of other player(s) • E.g., chess, checkers, rock-paper-scissors, …
Two-Player, Deterministic, Zero-Sum Games • : the initial state • : defines which player has the move in a state • : defines the set of legal moves • : the transition model that defines the result of the move • : returns true if the game is over. In that case is called a terminal state. • : a utility function (objective function) that defines the numeric value of the terminal state for player
Minimax • “Perfect play” for deterministic games • Idea: choose move to position with highest minimax value = best achievable payoff against best play
Is minimax optimal? • Depends • If opponent is not rational could be a better play • Yes • With assumption both players always make best move
Properties of minimax • Complete? • Yes (if tree is finite) • Space complexity? • O(bd) (depth-first exploration) • Optimal? • Yes (against an optimal opponent) • Time complexity? • O(bd) • For chess, b ≈ 35, d ≈100 for "reasonable" games ≈ 10154 exact solution completely infeasible
How to handle suboptimal opponents? • Can build model of opponent behavior • Use that to guide search rather than MIN • Reinforcement learning (later in the semester) provides another approach
α-β pruning • Do we need to explore every node in the search tree? • Insight: some moves are clearly bad choices
But, what if we had these values? 1 99 It doesn’t matter, they won’t make any difference so don’t look at them.
Properties of α-β • Pruning does not affect final result • i.e. returns the same best move • (caveat: only if can search entire tree!) • Good move ordering improves effectiveness of pruning • With "perfect ordering," time complexity = O(bm/2) • Can come close in practice with various heuristics
Bounding search • Similar to depth-limited search: • Don’t have to search to a terminal state, search to some depth instead • Find some way of evaluating non-terminal states
Evaluation function • Way of estimating how good a position is • Humans consider (relatively) few moves and don’t search very deep • But they can play many games well • evaluation function is key • A LOT of possibilities for the evaluation function
A simple function for chess • White = 9 * # queens + 5 *# rooks + 3 * # bishops + 3 * # knights + # pawns • Black= 9 * # queens + 5 *# rooks + 3 * # bishops + 3 * # knights + # pawns • Utility= White - Black
Other ways of evaluating a game position? • Features: • Spaces you control • How compressed your pieces are • Threat-To-You – Threat-To-Opponent • How much does it restrict opponent options
Implications • Larger branching factor (relatively) harder for computers • People rely more on evaluation function than on search
Deterministic games in practice • Othello: human champions refuse to compete against computers, who are too good. • Chess: Deep Blue defeated human world champion Garry Kasparov in a six-game match in 1997. • Checkers: Chinook ended 40-year-reign of human world champion Marion Tinsley in 1994. In 2007 developers announced that the program has been improved to the point where it cannot lose a game. • Go: human champions refuse to compete against computers, who are too bad.
More on checkers • Checkers has a branching factor of 10 • Why isn’t the result like Othello? • Complexity of imagining moves: a move can change a lot of board positions • A limitation that does not affect computers
Summary • Games are a core (fun) part of AI • Illustrate several important points about AI • Provide good visuals and demos • Turn-based games (that can fit in memory) are well addressed • Make many assumptions (optimal opponent, turn-based, no alliances, etc.)