Download
1 / 1
10 likes | 143 Vues
Further Modeling using the Information Integration Model of Consciousness Michael W. Hadley, Matt McGranaghan , Chun Wai Liew and Elaine R. Reynolds Neuroscience Program and Department of Computer Science, Lafayette College, Easton PA 18042. Introduction.

E N D
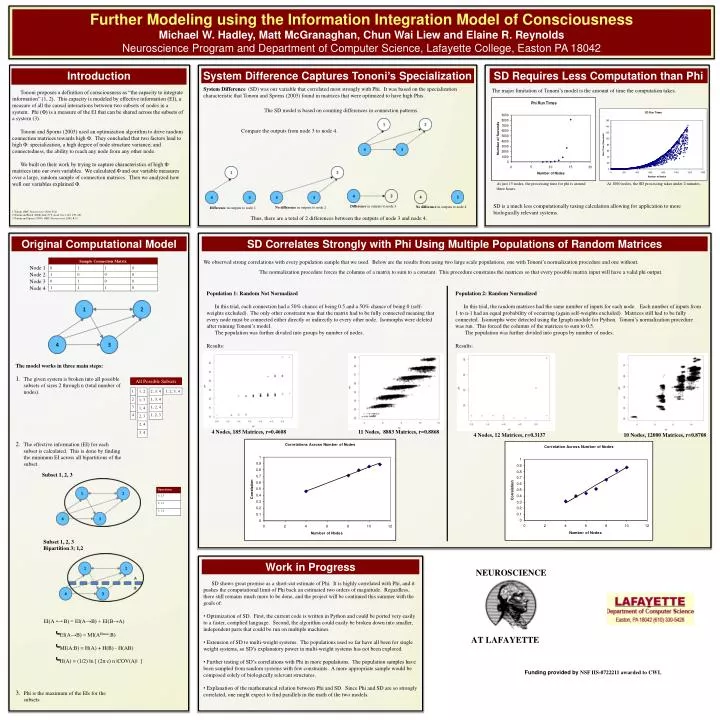
Further Modeling using the Information Integration Model of Consciousness Michael W. Hadley, Matt McGranaghan, Chun WaiLiew and Elaine R. Reynolds Neuroscience Program and Department of Computer Science, Lafayette College, Easton PA 18042 Introduction System Difference Captures Tononi’s Specialization SD Requires Less Computation than Phi System Difference (SD) was our variable that correlated most strongly with Phi. It was based on the specialization characteristic that Tononi and Sporns (2003) found in matrices that were optimized to have high Phis. The major limitation of Tononi’s model is the amount of time the computation takes. Tononi proposes a definition of consciousness as “the capacity to integrate information” (1, 2). This capacity is modeled by effective information (EI), a measure of all the causal interactions between two subsets of nodes in a system. Phi (Φ) is a measure of the EI that can be shared across the subsets of a system (3). Tononi and Sporns (2003) used an optimization algorithm to drive random connection matrices towards high Φ. They concluded that two factors lead to high Φ: specialization, a high degree of node structure variance; and connectedness, the ability to reach any node from any other node. We built on their work by trying to capture characteristics of high Φ matrices into our own variables. We calculated Φ and our variable measures over a large, random sample of connection matrices. Then we analyzed how well our variables explained Φ. 1 Tononi BMC Neuroscience 2004, 5:42 2 Tononi and Koch (2008) Ann. N.Y. Acad. Sci. 1124: 239–261 3 Tononi and Sporns (2003) BMC Neuroscience 2003, 4:31 The SD model is based on counting differences in connection patterns. Compare the outputs from node 3 to node 4. At just 15 nodes, the processing time for phi is around three hours. At 1000 nodes, the SD processing takes under 2 minutes. SD is a much less computationally taxing calculation allowing for application to more biologically relevant systems. Difference in outputs to node 3 No difference in outputs to node 4 No difference in outputs to node 2 Difference in outputs to node 1 Thus, there are a total of 2 differences between the outputs of node 3 and node 4. Original Computational Model SD Correlates Strongly with Phi Using Multiple Populations of Random Matrices Node 1 We observed strong correlations with every population sample that we used. Below are the results from using two large scale populations, one with Tononi’s normalization procedure and one without. Node 2 The normalization procedure forces the columns of a matrix to sum to a constant. This procedure constrains the matrices so that every possible matrix input will have a valid phi output. Node 3 Node 4 Population 1: Random Not Normalized In this trial, each connection had a 50% chance of being 0.5 and a 50% chance of being 0 (self-weights excluded). The only other constraint was that the matrix had to be fully connected meaning that every node must be connected either directly or indirectly to every other node. Isomorphs were deleted after running Tononi’s model. The population was further divided into groups by number of nodes. Results: Population 2: Random Normalized In this trial, the random matrices had the same number of inputs for each node. Each number of inputs from 1 to n-1 had an equal probability of occurring (again self-weights excluded). Matrices still had to be fully connected. Isomorphs were detected using the Igraph module for Python. Tononi’s normalization procedure was run. This forced the columns of the matrices to sum to 0.5. The population was further divided into groups by number of nodes. Results: The model works in three main steps: The given system is broken into all possible subsets of sizes 2 through n (total number of nodes). The effective information (EI) for each subset is calculated. This is done by finding the minimum EI across all bipartitions of the subset. Phi is the maximum of the EIs for the subsets All Possible Subsets 4 Nodes, 185 Matrices, r=0.4608 11 Nodes, 8883 Matrices, r=0.8868 4 Nodes, 12 Matrices, r=0.3137 10 Nodes, 12000 Matrices, r=0.8708 Subset 1, 2, 3 Subset 1, 2, 3 Bipartition 3; 1,2 EI(A→B) = MI(AHmax:B) MI(A:B) = H(A) + H(B) - H(AB) H(A) = (1/2) ln [ (2π e) n |COV(A)| ] Work in Progress EI(A B) = EI(A→B) + EI(B→A) • SD shows great promise as a short-cut estimate of Phi. It is highly correlated with Phi, and it pushes the computational limit of Phi back an estimated two orders of magnitude. Regardless, there still remains much more to be done, and the projectwill be continued this summer with the goals of: • Optimization of SD. First, the current code is written in Python and could be ported very easily to a faster, complied language. Second, the algorithm could easily be broken down into smaller, independent parts that could be run on multiple machines. • Extension of SD to multi-weight systems. The populations used so far have all been for single weight systems, so SD’s explanatory power in multi-weight systems has not been explored. • Further testing of SD’s correlations with Phi in more populations. The population samples have been sampled from random systems with few constraints. A more appropriate sample would be composed solely of biologically relevant structures. • Explanation of the mathematical relation between Phi and SD. Since Phi and SD are so strongly correlated, one might expect to find parallels in the math of the two models. Funding provided by NSF IIS-0722211awarded to CWL