Download
1 / 1
10 likes | 119 Vues
Independent Study of Parallel Programming Languages. An Independent Study By: Haris Ribic, Computer Science - Theoretical Independent Study Advisor: Professor Daniel Bennett. WHY THIS STUDY?. “In 2007, the degree of parallelism for personal computing in current desktop systems

E N D
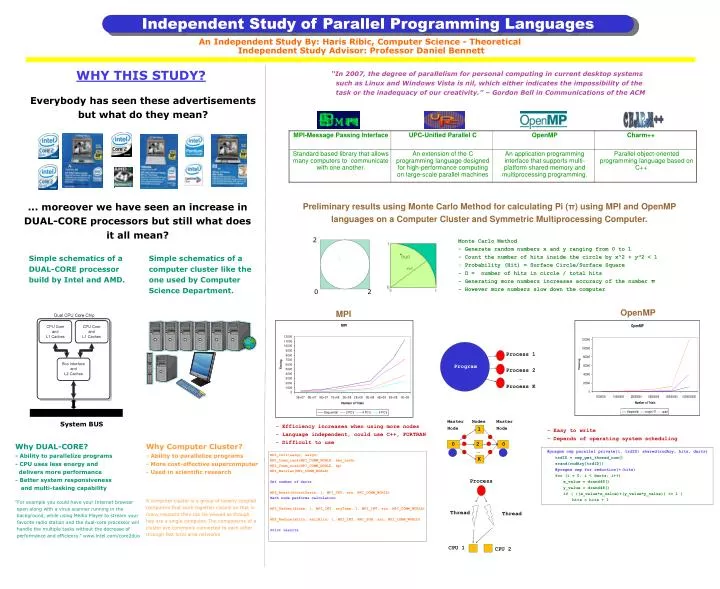
Independent Study of Parallel Programming Languages An Independent Study By: Haris Ribic, Computer Science - Theoretical Independent Study Advisor: Professor Daniel Bennett WHY THIS STUDY? “In 2007, the degree of parallelism for personal computing in current desktop systems such as Linux and Windows Vista is nil, which either indicates the impossibility of the task or the inadequacy of our creativity.” – Gordon Bell in Communications of the ACM Everybody has seen these advertisements but what do they mean? ... moreover we have seen an increase in DUAL-CORE processors but still what does it all mean? Preliminary results using Monte Carlo Method for calculating Pi (π) using MPI and OpenMP languages on a Computer Cluster and Symmetric Multiprocessing Computer. 2 • Monte Carlo Method • - Generate random numbers x and y ranging from 0 to 1 • - Count the number of hits inside the circle by x^2 + y^2 < 1 • - Probability (Hit) = Surface Circle/Surface Square • - Π = number of hits in circle / total hits • - Generating more numbers increases accuracy of the number π • - However more numbers slow down the computer Simple schematics of a DUAL-CORE processor build by Intel and AMD. Simple schematics of a computer cluster like the one used by Computer Science Department. 0 2 OpenMP MPI Process 1 Process 2 … Process K Program Master Nodes Master Node Node System BUS - Efficiency increases when using more nodes - Language independent, could use C++, FORTRAN - Difficult to use 1 - Easy to write - Depends of operating system scheduling #pragma omp parallel private(i, trdID) shared(rndAry, hits, darts) trdID = omp_get_thread_num() srand(rndAry[trdID]) #pragma omp for reduction(+:hits) for (i = 0; i < darts; i++) x_value = drand48() y_value = drand48() if ( ((x_value*x_value)+(y_value*y_value)) <= 1 ) hits = hits + 1 0 2 0 Why DUAL-CORE? - Ability to parallelize programs - CPU uses less energy and delivers more performance - Better system responsiveness and multi-tasking capability “For example you could have your Internet browser open along with a virus scanner running in the background, while using Media Player to stream your favorite radio station and the dual-core processor will handle the multiple tasks without the decrease of performance and efficiency.” www.intel.com/core2duo Why Computer Cluster? - Ability to parallelize programs - More cost-effective supercomputer - Used in scientific research A computer cluster is a group of loosely coupled computers that work together closely so that in many respects they can be viewed as though hey are a single computer. The components of a cluster are commonly connected to each other through fast local area networks. … MPI_Init(&argc, &argv)MPI_Comm_rank(MPI_COMM_WORLD, &my_rank) MPI_Comm_size(MPI_COMM_WORLD, &p)MPI_Barrier(MPI_COMM_WORLD) Get number of darts MPI_Bcast(&totalDarts, 1, MPI_INT, src, MPI_COMM_WORLD) Each node performs calculation MPI_Gather(&time, 1, MPI_INT, aryTime, 1, MPI_INT, src, MPI_COMM_WORLD) MPI_Reduce(&hits, &allHits, 1, MPI_INT, MPI_SUM, src, MPI_COMM_WORLD) Print results K Process Thread Thread CPU 1 CPU 2


















