Download
1 / 1
10 likes | 115 Vues
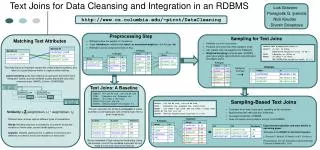
Text Joins for Data Cleansing and Integration in an RDBMS. Luis Gravano Panagiotis G. Ipeirotis Nick Koudas Divesh Srivastava. Similarity = Σ weight(token, t 1 ) * weight(token, t 2 ). token. Name. 1. HATRONIC CORP. 2. EUROAFT INC. 3. EUROAFT CORP. …. Name. 1. EUROAFT CORP. 2.

E N D
Text Joins for Data Cleansing and Integration in an RDBMS Luis Gravano Panagiotis G. Ipeirotis Nick Koudas Divesh Srivastava Similarity = Σweight(token, t1) * weight(token, t2) token Name 1 HATRONIC CORP 2 EUROAFT INC 3 EUROAFT CORP … Name 1 EUROAFT CORP 2 HATRONIC INC … Sampling for Text Joins http://www.cs.columbia.edu/~pirot/DataCleaning Preprocessing Step Matching Text Attributes • RiWeights store the weights for the tokens. • Tuple ‹tid,token,w› indicates that token has normalized weight w in the Ri tuple tid. • RiWeights can be computed entirely in SQL. • Similarity is a sum of products. • Products cannot be high when weight is small. • Can (safely) drop low weights from RiWeights. • Weightedsampling [Cohen&Lewis, SODA97] gives good weight approximations and eliminates low weight tokens. INSERT INTO RiSample(tid,token,c) SELECT rw.tid, rw.token, ROUND(S*rw.weight/rs.total, 0) AS c FROM RiWeights rw, RiSum rs WHERE rw.token = rs.token AND ROUND(S*rw.weight/rs.total, 0) > 0 R2Weights R2 R1Weights token w R1 1 HATRONIC 0.98 token w 1 CORP 0.02 1 EUROAFT 0.98 2 EUROAFT 0.95 1 CORP 0.02 RiWeights 2 INC 0.05 2 HATRONIC 0.98 token w RiSample Text matching is an important component of data cleaning systems, and relies on a good distance metric to capture entity matches. Cosine similarity gives high similarity to tuple pairs that share many “infrequent” tokens, and low similarity to pairs that share only a few, common tokens (WHIRL: [Cohen, SIGMOD98]). 3 EUROAFT 0.92 Sampling 20 times 2 INC 0.01 1 HATRONIC 0.98 3 CORP 0.07 … → 1 CORP 0.02 … 2 EUROAFT 0.95 2 INC 0.05 3 EUROAFT 0.92 3 CORP 0.07 … Infrequent token (high weight) Text Joins: A Baseline SELECTr1w.tid AS tid1, r2w.tid AS tid2 FROMR1Weights r1w, R2Weights r2w WHERE r1w.token = r2w.token GROUP BYr1w.tid, r2w.tid HAVINGSUM(r1w.weight*r2w.weight)≥ φ Sampling-Based Text Joins Common token (low weight) SELECT r1w.tid AS tid1, r2s.tid AS tid2 FROM R1Weights r1w, R2Sample r2s, R2sum r2sum WHEREr1w.token = r2s.token AND r1w.token = r2sum.token GROUP BY r1w.tid, r2s.tid HAVING SUM(r1w.weight*r2sum.total*r2s.c) ≥S*φ This join calculates the similarity of all pairs of tuples and filters out all tuple pairs with similarity lower than a given threshold φ. • Considers much fewer tuple pairs, speeding up join execution. • Approximates well real tuple-pair similarities. • Leverages scalability of RDBMS. • Does not require moving data in and out of the RDBMS. R2Sample Different token choices capture different types of mismatches: Words: Handles insertions and deletions of common words and variations of word order; cannot handle spelling errors. Q-grams: Handles spelling errors in addition to insertions and deletions of common words and variations of word order. R1Weights Experimental evaluation and more details in upcoming paper: Text Joins in an RDBMS for Web Data Integration L. Gravano, P. Ipeirotis, N. Koudas, and D. Srivastava Proceedings of the 12th International World-Wide Web Conference (WWW2003), 2003 = We are interested in high values for threshold φ. Using the baseline, most of the candidate tuple pairs do not make it to the final result of the text join.


















