Download

1 / 75
750 likes | 771 Vues
Hidden Markov Models (HMMs) for Information Extraction. Daniel S. Weld CSE 454. Extraction with Finite State Machines e.g. Hidden Markov Models (HMMs). standard sequence model in genomics, speech, NLP, …. What’s an HMM?. Set of states Initial probabilities Transition probabilities

E N D
Hidden Markov Models (HMMs)for Information Extraction Daniel S. Weld CSE 454
Extraction withFinite State Machinese.g.Hidden Markov Models (HMMs) standard sequence model in genomics, speech, NLP, …
What’s an HMM? Set of states Initial probabilities Transition probabilities Set of potential observations Emission probabilities o1 o2 o3 o4 o5 HMM generates observation sequence
Hidden Markov Models (HMMs) Finite state machine Hidden state sequence Generates o1 o2 o3 o4 o5 o6 o7 o8 Observation sequence Adapted from Cohen & McCallum
Hidden Markov Models (HMMs) Finite state machine Hidden state sequence Generates o1 o2 o3 o4 o5 o6 o7 o8 Observation sequence Graphical Model Random variable yt takes values from sss{s1, s2, s3, s4} yt-2 yt-1 ... yt ... Hidden states Random variable xt takes values from s{o1, o2, o3, o4, o5, …} ... xt-2 xt-1 xt ... Observations Adapted from Cohen & McCallum
HMM Graphical Model Random variable yt takes values from sss{s1, s2, s3, s4} yt-2 yt-1 ... yt ... Hidden states Random variable xt takes values from s{o1, o2, o3, o4, o5, …} ... xt-2 xt-1 xt ... Observations Finite state machine Hidden state sequence Generates o1 o2 o3 o4 o5 o6 o7 o8 Observation sequence
HMM Graphical Model Random variable yt takes values from sss{s1, s2, s3, s4} yt-2 yt-1 ... yt ... Hidden states Random variable xt takes values from s{o1, o2, o3, o4, o5, …} ... xt-2 xt-1 xt ... Observations Need Parameters: Start state probabilities: P(y1=sk ) Transition probabilities: P(yt=si | yt-1=sk) Observation probabilities: P(xt=oj | yt=sk ) Training: Maximize probability of training obervations Usually multinomial over atomic, fixed alphabet
Example: The Dishonest Casino A casino has two dice: Fair die P(1) = P(2) = P(3) = P(5) = P(6) = 1/6 Loaded die P(1) = P(2) = P(3) = P(5) = 1/10 P(6) = 1/2 Dealer switches back-&-forth between fair and loaded die about once every 20 turns Game: You bet $1 You roll (always with a fair die) Casino player rolls (maybe with fair die, maybe with loaded die) Highest number wins $2 Slides from Serafim Batzoglou
The dishonest casino HMM 0.05 0.95 0.95 FAIR LOADED P(1|F) = 1/6 P(2|F) = 1/6 P(3|F) = 1/6 P(4|F) = 1/6 P(5|F) = 1/6 P(6|F) = 1/6 P(1|L) = 1/10 P(2|L) = 1/10 P(3|L) = 1/10 P(4|L) = 1/10 P(5|L) = 1/10 P(6|L) = 1/2 0.05 Slides from Serafim Batzoglou
Question # 1 – Evaluation GIVEN A sequence of rolls by the casino player 124552646214614613613666166466163661636616361… QUESTION How likely is this sequence, given our model of how the casino works? This is the EVALUATION problem in HMMs Slides from Serafim Batzoglou
Question # 2 – Decoding GIVEN A sequence of rolls by the casino player 1245526462146146136136661664661636616366163… QUESTION What portion of the sequence was generated with the fair die, and what portion with the loaded die? This is the DECODING question in HMMs Slides from Serafim Batzoglou
Question # 3 – Learning GIVEN A sequence of rolls by the casino player 124552646214614613613666166466163661636616361651… QUESTION How “loaded” is the loaded die? How “fair” is the fair die? How often does the casino player change from fair to loaded, and back? This is the LEARNING question in HMMs Slides from Serafim Batzoglou
What’s this have to do with Info Extraction? 0.05 0.95 0.95 FAIR LOADED P(1|F) = 1/6 P(2|F) = 1/6 P(3|F) = 1/6 P(4|F) = 1/6 P(5|F) = 1/6 P(6|F) = 1/6 P(1|L) = 1/10 P(2|L) = 1/10 P(3|L) = 1/10 P(4|L) = 1/10 P(5|L) = 1/10 P(6|L) = 1/2 0.05
What’s this have to do with Info Extraction? 0.05 0.95 0.95 TEXT NAME P(the | T) = 0.003 P(from | T) = 0.002 ….. P(Dan | N) = 0.005 P(Sue | N) = 0.003 … 0.05
IE with Hidden Markov Models Given a sequence of observations: Yesterday Pedro Domingos spoke this example sentence. and a trained HMM: person name location name background Find the most likely state sequence: (Viterbi) YesterdayPedro Domingosspoke this example sentence. Any words said to be generated by the designated “person name” state extract as a person name: Person name: Pedro Domingos Slide by Cohen & McCallum
IE with Hidden Markov Models For sparse extraction tasks : Separate HMM for each type of target Each HMM should Model entire document Consist of target and non-target states Not necessarily fully connected 16 Slide by Okan Basegmez
Or … Combined HMM Example – Research Paper Headers 17 Slide by Okan Basegmez
HMM Example: “Nymble” [Bikel, et al 1998], [BBN “IdentiFinder”] Task: Named Entity Extraction Person end-of-sentence start-of-sentence Org Train on ~500k words of news wire text. (Five other name classes) Other Results: Case Language F1 . Mixed English 93% Upper English 91% Mixed Spanish 90% Slide adapted from Cohen & McCallum
Finite State Model Person end-of-sentence start-of-sentence Org (Five other name classes) vs. Path Other y6 y5 y4 y3 y2 … y1 x1 x2 x3 x4 x5 x6 …
Question #1 – Evaluation GIVEN A sequence of observations x1 x2 x3 x4 ……xN A trained HMM θ=( , , ) QUESTION How likely is this sequence, given our HMM ? P(x,θ) Why do we care? Need it for learning to choose among competing models!
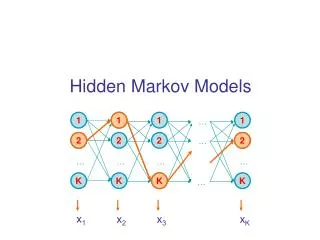
A parse of a sequence 1 1 1 1 … 2 2 2 2 … … … … … K K K K … Given a sequence x = x1……xN, A parse of o is a sequence of states y = y1, ……, yN person 1 2 2 other K location x1 x2 x3 xK Slide by Serafim Batzoglou
Question #2 - Decoding GIVEN A sequence of observations x1 x2 x3 x4 ……xN A trained HMM θ=( , , ) QUESTION How dow we choose the corresponding parse (state sequence) y1 y2 y3 y4 ……yN, which “best” explains x1 x2 x3 x4 ……xN ? There are several reasonable optimality criteria: single optimal sequence, average statistics for individual states, …
Question #3 - Learning GIVEN A sequence of observations x1 x2 x3 x4 ……xN QUESTION How do we learn the model parameters θ=( , , ) which maximize P(x, θ) ?
Three Questions Evaluation Forward algorithm Decoding Viterbi algorithm Learning Baum-Welch Algorithm (aka “forward-backward”) A kind of EM (expectation maximization)
Naive Solution to #1: Evaluation Given observations x=x1 …xNand HMM θ, what is p(x) ? Enumerate every possible state sequence y=y1 …yN Probability of x and given particular y Probability of particular y Summing over all possible state sequences we get 2T multiplications per sequence For small HMMs T=10, N=10 there are 10 billion sequences! NT state sequences!
Use Dynamic Programming Cache and reuse inner sums “forward variables” Many Calculations Repeated
Solution to #1: Evaluation Use Dynamic Programming: Define forward variable probability that at time t - the state is Si - the partial observation sequence x=x1 …xthas been emitted
Base Case: Forward Variable t(i) prob - that the state at t has value Si and - the partial obs sequence x=x1 …xthas been seen 1 person 2 other Base Case: t=1 1(i) = p(y1=Si) p(x1=o1) … K location x1
Inductive Case: Forward Variable t(i) prob - that the state at t has value Si and - the partial obs sequence x=x1 …xthas been seen 1 1 1 1 … … person 2 2 2 2 … … other Si … … … … K K K K location … … x1 x2 x3 xt
The Forward Algorithm t-1(1) t-1(2) t-1(3) t(3) t-1(K) SK SK yt-1 yt
The Forward Algorithm INITIALIZATION INDUCTION TERMINATION Time: O(K2N) Space: O(KN) K = |S| #states N length of sequence
Three Questions Evaluation Forward algorithm (also Backward algorithm) Decoding Viterbi algorithm Learning Baum-Welch Algorithm (aka “forward-backward”) A kind of EM (expectation maximization)
#2 – Decoding Problem Given x=x1 …xNand HMM θ, what is “best” parse y1 …yT? Several possible meanings of ‘solution’ States which are individually most likely Single best state sequence We want sequencey1 …yT, such that P(x,y)is maximized y* = argmaxy P( x, y ) Again, we can use dynamic programming! 1 1 1 1 … 1 2 2 2 2 … 2 2 … … … … K K K K … K o1 o2 o3 oT ? ? ? ? ? ? ? ?
δt(i) Like t(i) = prob that the state, y, at time t has value Si and the partial obs sequence x=x1 …xt has been seen Define δt(i) = probability of most likely state sequence ending with state Si, given observations x1, …, xt P(y1, …,yt-1, yt=Si | o1, …, ot, )
δt(i) = probability of most likely state sequence ending with state Si, given observations x1, …, xt P(y1, …,yt-1, yt=Si | o1, …, ot, ) Base Case: t=1 Maxi P(y1=Si) P(x1=o1 | y1 = Si)
Inductive Step P(y1, …,yt-1, yt=Si | o1, …, ot, ) t-1(1) t-1(2) Take Max t-1(3) S3 t(3) t-1(K) K K
The Viterbi Algorithm DEFINE INITIALIZATION INDUCTION TERMINATION | o1, …, ot, Backtracking to get state sequence y*
The Viterbi Algorithm x1 x2 ……xj-1 xj……………………………..xT State 1 Maxiδj-1(i) * Ptrans* Pobs 2 δj(i) i K Remember: δt(i) = probability of most likely state seq ending with yt = state St Slides from Serafim Batzoglou
Terminating Viterbi x1 x2 …………………………………………..xT δ State 1 δ 2 Choose Max δ i δ K δ
Terminating Viterbi x1 x2 …………………………………………..xT State 1 δ* Max 2 i K MaxiδT-1(i) * Ptrans* Pobs How did we compute *? Now Backchain to Find Final Sequence Time: O(K2T) Space: O(KT) Linear in length of sequence
The Viterbi Algorithm Pedro Domingos 44
Three Questions Evaluation Forward algorithm (Could also go other direction) Decoding Viterbi algorithm Learning Baum-Welch Algorithm (aka “forward-backward”) A kind of EM (expectation maximization)
If we have labeled training data! Input: Solution to #3 - Learning person name location name background } states & edges, but no probabilities Many labeled sentences YesterdayPedro Domingosspoke this example sentence. • Output: • Initial state & transition probabilities: p(y1), p(yt|yt-1) • Emission probabilities: p(xt | yt)
Input: Supervised Learning person name location name background } states & edges, but no probabilities YesterdayPedro Domingosspoke this example sentence. Daniel Weldgave his talk in Mueller 153. Sieg 128 is a nasty lecture hall, don’t you think? The next distinguished lecture is byOren Etzionion Thursday. • Output: • Initial state probabilities: p(y1) • P(y1=name) = 1/4 • P(y1=location) = 1/4 • P(y1=background) = 2/4
Input: Supervised Learning person name location name background } states & edges, but no probabilities YesterdayPedro Domingosspoke this example sentence. Daniel Weldgave his talk in Mueller 153. Sieg 128 is a nasty lecture hall, don’t you think? The next distinguished lecture is byOren Etzionion Thursday. • Output: • State transition probabilities: p(yt|yt-1) • P(yt=name | yt-1=name) = • P(yt=name | yt-1=background) = • Etc… 3/6 2/22
Input: Supervised Learning person name location name background } states & edges, but no probabilities Many labeled sentences YesterdayPedro Domingosspoke this example sentence. • Output: • Initial state probabilities: p(y1), p(yt|yt-1) • Emission probabilities: p(xt | yt)
Input: Supervised Learning person name location name background } states & edges, but no probabilities Many labeled sentences YesterdayPedro Domingosspoke this example sentence. • Output: • Initial state probabilities: p(y1), p(yt|yt-1) • Emission probabilities: p(xt | yt)
Solution to #3 - Learning Given x1 …xN, how do we learn θ=( , , ) to maximize P(x)? Unfortunately, there is no known way to analytically find a global maximum θ* such thatθ* = arg max P(o | θ) But it is possible to find a local maximum; given an initial model θ, we can always find a model θ’ such that P(o | θ’) ≥ P(o | θ)
Chicken & Egg Problem If we knew the actual sequence of states It would be easy to learn transition and emission probabilities But we can’t observe states, so we don’t! • If we knew transition & emission probabilities • Then it’d be easy to estimate the sequence of states (Viterbi) • But we don’t know them! 52 Slide by Daniel S. Weld