Problem size : |S|=576, |A|=19, |O|=18 Action hierarchy :
r t-1 r t ... s t-1 s t ... World state: o t-1 o t a t-1 ?? Control layer: ... b t-1 ?? ... Robot belief: Belief state OBSERVATIONS STATE USER + WORLD + ROBOT ACTIONS subtask Patient room Act abstract action Move InvestigateHealth Navigate AskWhere CheckPulse


Problem size : |S|=576, |A|=19, |O|=18 Action hierarchy :
E N D
Presentation Transcript
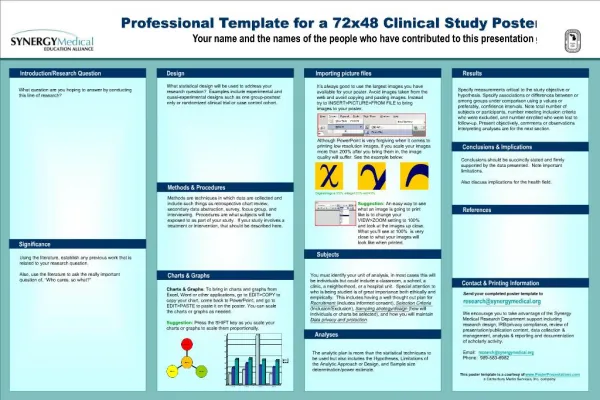
rt-1 rt ... st-1 st ... World state: ot-1 ot at-1 ?? Control layer: ... bt-1 ?? ... Robot belief: Belief state OBSERVATIONS STATE USER + WORLD + ROBOT ACTIONS subtask Patient room Act abstract action Move InvestigateHealth Navigate AskWhere CheckPulse CheckMeds Robot home North South East West primitive action Physiotherapy AMove ={AskWhere,Navigate} SMove ={X’,Y’,Destination} Move ={o0,…,op} ANav ={N,S,E,W} SNav ={X,Y} Nav ={o0,…,om} Move Navigate AskWhere West South East North High-level robot behavior control using POMDPs Joelle Pineau and Sebastian Thrun Carnegie Mellon University I - Background III - Experimental Setup Abstract: This paper describes a robot controller which uses probabilistic decision-making techniques at the highest-level of behavior control. The POMDP-based robot controller has the ability to incorporate noisy and partial sensor information, and can arbitrate between information-gathering and performance-related actions. We present a hierarchical variant of the POMDP model which exploits structure in the problem domain to accelerate planning. This POMDP controller is implemented and tested onboard a mobile robot in the context of an interactive service task. What are POMDPs? POMDPs model decision-theoretic planning problems. The goal is to find an action-selection strategy that maximizes reward, even in the presence of state uncertainty. Introducing Pearl, the nursing assistant robot: • Problem size: |S|=576, |A|=19, |O|=18 • Action hierarchy: • State features: • Robot location • Person Location • Person Status • Reminder Goal • Motion Goal • Conversation Goal • Observation features: • Words from speech recognition • Button presses from touchscreen • Laser readings • Reminder messages • We need a high-level controller that can: • select good behaviors or actions • share sensor information between modules • handle uncertainty • negotiate over goals from different specialized modules • arbitrate between information-gathering and performance actions Formally, a POMDP is an n-tuple {S,A,,b,T,O,R } POMDP task 1: Track state: After an action, what is the state of the world? POMDP task 2: Optimize policy: Which action should the controller apply next? • S : Set of states • A : Set of actions • : Set of observations • b(s) := Pr(s | t=0) • T(s,a,s’) := Pr(s’ | s,a) • O(s,a,o) := Pr(o | s,a) • R(s,a) Top controller • Task domain: Robot provides reminders and guidance to elderly user. • Experimental scenario: Robot must go meet subjects in their apartment and take them to a physiotherapy appointment, while also engaging in appropriate social interaction. • Environment: Nursing home near Pittsburgh, PA • Test subjects: Six elderly residents in assisted living facility. People tracking/following Autominder Not so hard. Speech recognition&synthesis Autonomous navigation Very hard! Our approach: High-level robot behavior control usingPartially Observable Markov Decision Processes (POMDPs) Exact policy optimization (task 2) is computationally intractable for large problems (~20+ states), therefore we need approximations. II - Robot control using Hierarchical POMDPs IV - Results Assumptions Approximating POMDPs for large domains Performance results for three contrasting users. Comparing performance of POMDP policy vs MDP policy. The MDP policy does not consider uncertainty during planning, and therefore is unable to ask clarification actions. For all users, performance is much better using the POMDP policy. Figure 1: Example of a successful guidance experiment. • Each subtask is a separate POMDP. • Each subtask has a subset of all actions. • Primitive actions are placed in leaf nodes, and are from the original action set. • Abstract actions are introduced in internal nodes. • Each subtask has a non-trivial reward function (i.e. R(s,a) is not constant). Key Idea:Exploit hierarchical structure in the problem domain to break a large problem into many “related” POMDPs. What type of structure?Action set partitioning (b) Reminding of appointment (a) Pearl approaching subject Planning with Hierarchical POMDPs (c) Guidance through corridor (d) Entering physiotherapy dept. • Given POMDP model M = { S, A, , b, T, O, R } and subtask hierarchy H • For each subtask h H: 1) Set components Ah children nodes Sh S h bh, Th, Oh, Rh 2) Minimize model Sh {zh(s0), …, zh(sn)} h {yh(o0), …, yh(op)} 3) Solve subtask h {bh, Th, Oh, Rh} Execution with Hierarchical POMDPs • Step 1 - Update belief: • Step 2 - Traversing hierarchy top-down, for each subtask: 1) Get local belief: 2) Consult local policy: 3) If a is leaf node, terminate. Else, go to that subtask. (e) Pearl leaves (e) Asking for weather forecast • Observations from nursing-home experiments: • 100% task completion rate amongst test subjects • overall high-level of excitement amongst subjects • adaptive speed control for robot is necessary • improved speech recognition would be great • more verbal interaction during guidance is recommended