Download

1 / 10
0 likes | 2 Vues
Explore greater nuances of retrieval augmented generation (RAG) in precision modeling; powering large language models seamlessly. Get details now!

E N D







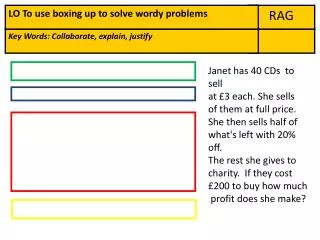











![[PDF] DOWNLOAD The Rag Rug Handbook](https://cdn7.slideserve.com/12446046/slide1-dt.jpg)
![[EBOOK] DOWNLOAD How To Do Rag Weaving: New Methods To Make Rag Weaving](https://cdn7.slideserve.com/12446077/slide1-dt.jpg)
![[PDF] DOWNLOAD Twined Rag Rugs](https://cdn7.slideserve.com/12446093/slide1-dt.jpg)