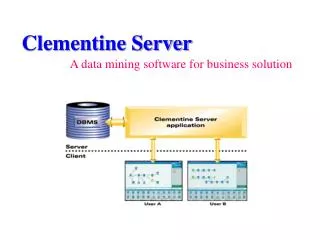
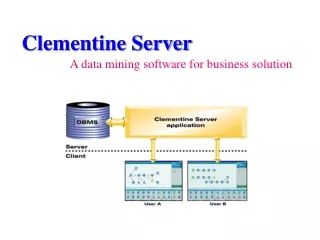
Data Mining with Clementine
Data Mining with Clementine Girish Punj Professor of Marketing School of Business University of Connecticut Agenda How to introduce data mining to students Why Clementine? Clementine features and capabilities A typical data mining class Useful teaching resources


Data Mining with Clementine
E N D
Presentation Transcript
Data Mining with Clementine Girish Punj Professor of Marketing School of Business University of Connecticut
Agenda • How to introduce data mining to students • Why Clementine? • Clementine features and capabilities • A typical data mining class • Useful teaching resources • Questions?
Introduce Data Mining to Students • Data mining chosen as one of top 10 emerging technologies..” (MIT Technology Review) • Data mining expertise is most sought after...” (Information Week Survey) • Data mining skills are an important part of the “toolkit” needed by managers in a complex business world • Data Mining for job advancement and as career insurance during good and bad economic times
Introduce Data Mining to Students “When I looked at what companies were doing with analytics I found it had moved from the back room to the board room…a number of companies weren’t just using analytics, they were now competing on analytics -- they had made analytics the central strategy of their business.” (Tom Davenport, author of ‘Competing on Analytics’) “We are drowning in information but starved for knowledge.” (John Naisbitt author of ‘Megatrends’)
Use data mining to understand customers’ wants, needs, and preferences Based on this information, deliver timely, personalized promotional offers Applications: Retail
Leverage data and text mining to speed claims processing and help reduce fraud Applications: Insurance
Applications: Manufacturing Model historical production and quality data to reduce development time and improve quality of production processes
Applications: Telecom Use data mining to identify appropriate customer segments for new marketing initiatives Predict likelihood of customer churn and target those likely to leave with retention campaigns
Data Mining and Knowledge Discovery • Data mining is the process of discovery of interesting, meaningful and actionable patterns hidden in large amounts of data (Han and Kamber 2006) • Knowledge Discovery (KD) as a more inclusive term • Knowledge Discovery using a combination of artificial and human intelligence • Data → Information → Knowledge
Data Mining No hypotheses are needed Can find patterns in very large amounts of data Uses all the data available Terminology used: field, record, supervised learning, unsupervised learning Statistics Uses Hypothesis testing Techniques are not suitable for large datasets Relies on sampling Terminology used: variable, observation, analysis of dependence, analysis of interdependence Data Mining and Statistics
Deal with Numerophobia http://www.youtube.com/watch?v=nRKzseCLja8 Emphasize Differences between Statistics and Data Mining to advantage (no probability distributions) Use a math primer for numerically challenged students
Introduce Software to Students • Clementine 12.0: • Student Version (Clementine GradPack) is of enterprise strength • Student License extends for about eight months beyond course completion date • Directly address cost concerns by discussing value of “investment”
Who was Clementine? http://www.empire.k12.ca.us/capistrano/mike/capmusic/the_wild_west/gold_rush/clemtine.mid Daughter of a miner during the 1849 California Gold Rush who developed a reputation… “In a cavern, in a canyon,Excavating for a mineDwelt a miner, forty niner,And his daughter Clementine…”
Introduce Software to Students • Visual approach makes model building an art form • Concept of “data flow” enables building of multiple models • Point-and-click model building (no manual coding) • Comprehensive portfolio of models for the Business Analyst as well as the Technical Expert
Create tables and charts for means, ranges, and correlations of all variables Clementine Basics: Visualize Data
Examine associations among variables using visual displays Clementine Basics: Visualize Data
Building Models in Clementine Up sell/ Cross sell Creating business rules for Up sell & Cross Sell Identify and target likely churn candidates, and create retention offerings to decrease their likelihood to churn Models Propensity to respond/purchase Customer Churn Develop models on desired purchase behavior, and target candidates that are most likely to respond
Can use auto “c.h.d” settings (beginning user) Modeling Approaches • But can also use expert capabilities (advanced user)
Estimation Prediction Classification Clustering Affinity/Association Data Mining Procedures
Estimation & Prediction: - Neural networks Classification: - Decision trees (2 types) Specific Methodologies Available
Specific Methodologies Available • Clustering: - K-means - Kohonen networks • Affinity/Association: - Association rules (2 types)
Positioning the Course Business Applications Theory and Concepts Clementine Models Focus of the Course
A Typical Class • Discuss business applications of methodology based on brief articles from the business press (30 minutes) • Present theory and concepts (30 minutes) • Build a Clementine model for students (30 minutes) • Ask students build a Clementine model (30 minutes) • Discuss homework assignment (15 minutes) • Students complete a homework assignment after class (requires three hours)
Discuss Business Applications “Wal-Mart's next competitive weapon is advanced data mining, which it will use to forecast, replenish and merchandise on a micro scale By analyzing years' worth of sales data--and then cranking in variables such as the weather and school schedules--the system could predict the optimal number of cases of Gatorade, in what flavors and sizes, a store in Laredo, Texas, should have on hand the Friday before Labor Day Then, if the weather forecast suddenly called for temperatures 5 hotter than last year, the delivery truck would automatically show up with more” From: “Can Wal-Mart Get Any Bigger,” Time, 13 January, 2003
Present Theory and Concepts ? Are window cleaning products also purchased when detergents and orange juice are bought together? ? Where should detergents be placed in the Store to maximize their sales? Is soda typically purchased with bananas? Does the brand of soda make a difference? ? How are the demographics of the neighborhood affecting what Customers are buying? ? From: Data Mining Techniques by Michael J. A. Berry and Gordon S. Linoff
Present Theory and Concepts • Start with a record of past purchase transactions that link items purchased together From: Data Mining Techniques by Michael J. A. Berry and Gordon S. Linoff
Create a co-occurrence matrix that pairs items purchased together in the form of a table Present Theory and Concepts The co-occurrence matrix shows the number of times the “row” item was purchased with the “column” item (note that the matrix is symmetrical) From: Data Mining Techniques by Michael J. A. Berry and Gordon S. Linoff
Rule Support = Percentage of transactions with both the items of interest What is the Support for the rule “If Soda, then OJ” ? OJ and Soda are purchased together in 2 out of 5 transactions Hence Support is 40% What is the support for the rule “If OJ, then Soda” ? Still 40% Present Theory and Concepts From: Data Mining Techniques by Michael J. A. Berry and Gordon S. Linoff
Confidence = Ratio of the number of transactions with both the items of interest to the number of transactions with the “If” items What is the Confidence for “If Soda, then OJ” ? 2 out of 3 soda purchase transactions also include OJ Hence Confidence is 66.66% What is the Confidence for “If OJ, then Soda” ? 2 out of 4 OJ purchase transactions also include soda Hence Confidence is 50% Present Theory and Concepts From: Data Mining Techniques by Michael J. A. Berry and Gordon S. Linoff
Present Theory and Concepts • Support (Prevalence): Percentage of records in the dataset that match the antecedent Support = p (antecedent) From: Data Mining Techniques by Michael J. A. Berry and Gordon S. Linoff
Present Theory and Concepts • Confidence (Predictability): Percentage of records in the dataset that match the antecedent and also match the consequent Confidence = p (antecedent and consequent) p (antecedent) From: Data Mining Techniques by Michael J. A. Berry and Gordon S. Linoff
Present Theory and Concepts • Lift (Improvement): How much better a rule is at predicting the consequent than chance alone? • Lift = • A rule is only useful if Lift is > 1 • confidence • p (consequent) From: Data Mining Techniques by Michael J. A. Berry and Gordon S. Linoff
Homework Assignment • Conduct a Market Basket Analysis on the dataset using both the Apriori and GRI modeling nodes in Clementine. • Reconcile the association rules discovered as a result of the Apriori and GRI modeling nodes. • Provide a narrative description that attempts to explain the convergence (or lack thereof) between the results obtained from the two modeling nodes. • Select those association rules discovered during your Market Basket Analysis that would make the most intuitive sense to the category managers involved and create demographic profiles of shoppers who appear to fit those rules.
Resources • “Data Mining Techniques” by Michael J. A. Berry and Gordon S. Linoff (second edition), Wiley, 2004 • “Discovering Knowledge in Data” by Daniel T. Larose, Wiley, 2005 • “Making Sense of Statistics” by Fred Pyrczak (fourth edition), Pyrczak Publishing, 2006 • Recent articles from the business press identified using the “Factiva” database and “data mining” “predictive analytics” as search keywords • www.kdnuggets.com
Thank you for your time and participation • Questions? • Additional Information: Please see my syllabus at http://www.spss.com/academic/educator/curriculum/index.htm?tab=1 • Comments and suggestions are welcome. Please send them to: Girish.Punj@business.uconn.edu