Comprehensive Data Structure for Bioinformatics Analysis
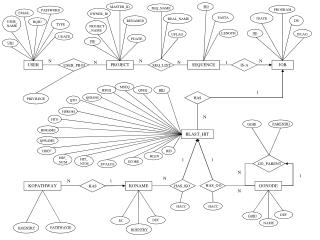
This document outlines a detailed data structure essential for bioinformatics projects. It encompasses various attributes such as unique identifiers, project information, user details, and measurement data that facilitate robust analysis and reporting of biological datasets. Key components include identifiers for sequences, programs, and user roles alongside analytical parameters such as scores, pathways, and gene ontology terms. This dataset supports efficient retrieval and manipulation of biological information, improving collaboration and research outcomes in genomics and proteomics studies.

Comprehensive Data Structure for Bioinformatics Analysis
E N D
Presentation Transcript
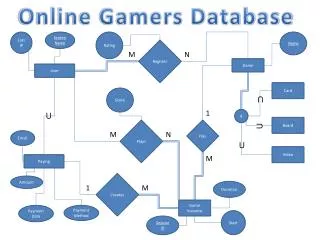
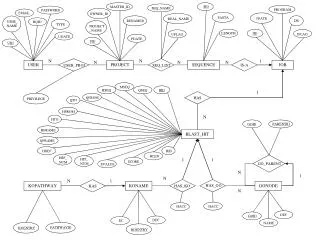
HDEF SID MASTER_ID SEQ_NAME PROGRAM PASSWORD EMAIL OWNER_ID FASTA JDATE REAL_NAME DB RENAMED USER_NAME BQID TYPE PROJECT_NAME LENGTH JID JFLAG UFLAG UDATE PDATE PID UID N N 1 N N N JOB USER PROJECT SEQUENCE IS-A USER_PROJ SEQ_LIST MSEQ BID HSEQ QSEQ 1 QFROM HAS PRIVILEGE QTO HFROM N HTO PARENTID GOID HFRAME BLAST_HIT QFRAME HID HLEN HSP_NUM 1 1 HIT_ NUM SCORE GO_PARENT EVALUE N 1 N N 1 KONAME HAS_GO GONODE KOPATHWAY HAS_KO HAS N HACC HACC DEF GOID DEF EC NAME PATHWAYID KOENTRY KOENTRY