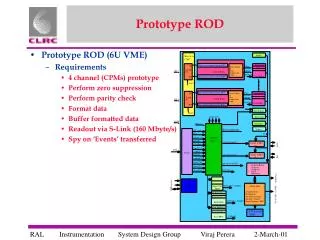
Pond: the OceanStore Prototype
360 likes | 389 Vues
The Pond: the OceanStore Prototype is a self-organizing and self-maintaining system that guarantees data consistency and durability in an untrusted infrastructure. It uses Tapestry for distributed object location and routing, erasure codes for fault tolerance, and Byzantine agreement for consensus. This presentation outlines the system overview, implementation, performance results, and concludes with the vision of the OceanStore.

Pond: the OceanStore Prototype
E N D
Presentation Transcript
Pond: the OceanStore Prototype Sean Rhea, Patrick Eaton, Dennis Geels, Hakim Weatherspoon, Ben Zhao, and John Kubiatowicz {srhea,eaton,geels,hweather,ravenben,kubitron}@cs.berkeley.edu University of California, Berkeley
OceanStore Assumptions • Untrusted Infrastructure: • The OceanStore is comprised of untrusted components • Only ciphertext within the infrastructure • Responsible Party: • Some organization (i.e. service provider) guarantees that your data is consistent and durable • Not trusted with content of data, merely its integrity • Mostly Well-Connected: • Data producers and consumers are connected to a high-bandwidth network most of the time • Exploit multicast for quicker consistency when possible • Promiscuous Caching: • Data may be cached anywhere, anytime • Optimistic Concurrency via Conflict Resolution: • Avoid locking in the wide area • Applications use object-based interface for updates
me HotOS Attendee Paul Hogan The OceanStore “Vision”
The Challenges • Maintenance • Many components, many administrative domains • Constant change • Must be self-organizing • Must be self-maintaining • All resources virtualized—no physical names • Security • High availability is a hacker’s target-rich environment • Must have end-to-end encryption • Must not place too much trust in any one host
Talk Outline • Introduction • System Overview • Tapestry • Erasure codes • Byzantine agreement • Putting it all together • Implementation and Deployment • Performance Results • Conclusion
The Technologies: Tapestry • Tapestry performs Distributed Object Location and Routing • From any host, find a nearby… • replica of a data object • Efficient • O(log N ) location time, N = # of hosts in system • Self-organizing, self-maintaining
Two-levels of Routing • Fast, probabilistic search for “routing cache”: • Built from attenuated bloom filters • Approximation to gradient search • Not going to say more about this today • Redundant Plaxton Mesh used for underlying routing infrastructure: • Randomized data structure with locality properties • Redundant, insensitive to faults, and repairable • Amenable to continuous adaptation to adjust for: • Changing network behavior • Faulty servers • Denial of service attacks
Automatic Maintenance All Tapestry state is Soft State • State maintained during transformations of network • Periodic restoration of state • Self-Tuning of link structure • Dynamic insertion: • New nodes contact small number of existing nodes • Integrate themselves automatically • Later, introspective optimization will move data to new servers • Dynamic deletion: • Node detected as unresponsive • Pointer state routed around faulty node (signed deletion requests authorized by servers holding data)
HotOS Attendee Paul Hogan The Technologies: Tapestry (con’t.)
W X f Y Z W f -1 Z The Technologies: Erasure Codes • More durable than replication for same space • The technique:
More on Erasure Coding • Much higher fault tolerance for same storage cost as replication • Divide block into m fragments • Encode these into n fragments, where n>m • Original object can be reconstructed from any m fragments • Rate of encoding r = m/n • Prototype uses Cauchy Reed-Solomon code with m=16, n=32
More on Erasure Coding • Apply an update at the primary replica • All newly-created blocks are erasure-coded • Resulting fragments are distributed via the Tapestry overlay to OceanStore archive servers for storage • To reconstruct a block, host uses Tapestry to discover m fragments and perform decoding • A technique that is being used in increasing number of distributed file systems
The Technologies: Byzantine Agreement • Guarantees all non-faulty replicas agree • Given N =3f +1 replicas, up to f may be faulty/corrupt • All non-faulty participants reach same decision as long as more than 2/3 of participants follow protocol correctly • Expensive • Requires O(N2) communication • Combine with primary-copy replication • Small number participate in Byzantine agreement • Multicast results of decisions to remainder
More on Byzantine Agreement • Implement primary replica as small set of cooperating servers called “inner ring” • Primary replica is a virtual resource • Can be mapped to different physical servers at different times • Avoid giving single machine complete control over user’s data • Inner ring servers use Byzantine-fault-tolerant protocol to agree on all updates to the data object • Digitally sign the result
More on Byzantine Agreement • Requires that participants authenticate messages they send • Use symmetric-key message authentication codes (MACs) on inner ring • Authenticate messages between two fixed machines • Use public key cryptography to communicate with other machines • Digital signature certifies each agreement results • So secondary replicas can locally verify authenticity of data received from other replicas • Most read traffic can be satisfied by second tier of replicas • Generating signatures is expensive; amortized over the number of replicas that receive the result
Cached Data Objects • Reconstructing a block from erasure codes is expensive • Oceanstore also employs whole-block caching • When a host reads a block from the archive, it queries Tapestry for block • If not available, reconstructs from fragments • Host caches a copy that can then be discovered later by other clients • host publishes its possession of the block in Tapestry • Reconstructed blocks are soft state; can be discarded by LRU policies
Updating Secondary Replicas • Efficient, push-based update of secondary replicas • Organized into an application-level multicast tree • Rooted at the primary replica for the object • When a primary replica applies an update to create a new version, sends update and heartbeat down dissemination tree • Multicast directly to secondary replicas
Archival Servers (for durability) HotOS Attendee Other Researchers Primary Replicas Secondary Replicas (soft state) Putting it all together: the Path of a Write
Talk Outline • Introduction • System Overview • Implementation and Deployment • Performance Results • Conclusion
Prototype Implementation • All major subsystems operational • Self-organizing Tapestry base • Primary replicas use Byzantine agreement • Secondary replicas self-organize into multicast tree • Erasure-coding archive • Application interfaces: NFS, IMAP/SMTP, HTTP • Event-driven architecture • Built on Staged Event-Driven Architecture (SEDA) • 280K lines of Java (J2SE v1.3) • JNI libraries for cryptography, erasure coding
Deployment on PlanetLab • http://www.planet-lab.org • ~100 hosts, ~40 sites • Shared .ssh/authorized_keys file • Pond: up to 1000 virtual nodes • Using custom Perl scripts • 5 minute startup • Gives global scale for free
Talk Outline • Introduction • System Overview • Implementation and Deployment • Performance Results • Andrew Benchmark • Stream Benchmark • Conclusion
Andrew Benchmark Loopback Server Pond Daemon Pond API fwrite syscall NFS Write Msg to Primary Linux Kernel Network Performance Results: Andrew Benchmark • Built a loopback file server in Linux • Translates kernel NFS calls into OceanStore API • Lets us run the Andrew File System Benchmark
Pond faster on reads: 4.6x • Phases III and IV • Only contact primary when cache older than 30 seconds • But slower on writes: 7.3x • Phases I, II, and V • Only 1024-bit are secure • 512-bit keys show CPU cost Performance Results: Andrew Benchmark • Ran Andrew on Pond • Primary replicas at UCB, UW, Stanford, Intel Berkeley • Client at UCB • Control: NFS server at UW
Closer Look: Write Cost • Byzantine algorithm adapted from Castro & Liskov • Gives fault tolerance, security against compromise • Fast version uses symmetric cryptography • Pond uses threshold signatures instead • Signature proves that f +1 primary replicas agreed • Can be shared among secondary replicas • Can also change primaries w/o changing public key • Big plus for maintenance costs • Results good for all time once signed • Replace faulty/compromised servers transparently
Small writes Signature dominates Threshold sigs. slow! Takes 70+ ms to sign Compare to 5 ms for regular sigs. • Large writes • Encoding dominates • Archive cost per byte • Signature cost per write Closer Look: Write Cost (times in milliseconds)
Closer Look: Write Cost (run on cluster)
Throughput in the wide area: Closer Look: Write Cost • Wide Area Throughput • Not limited by signatures • Not limited by archive • Not limited by Byzantine process bandwidth use • Limited by client-to-primary replicas bandwidth
Talk Outline • Introduction • System Overview • Implementation and Deployment • Performance Results • Andrew Benchmark • Stream Benchmark • Conclusion
Archival Servers HotOS Attendee Other Researchers Primary Replicas Secondary Replicas Closer look: Dissemination Tree
Closer look: Dissemination Tree • Self-organizing application-level multicast tree • Connects all secondary replicas to primary ones • Shields primary replicas from request load • Save bandwidth on consistency traffic • Tree joining heuristic (“first-order” solution): • Connect to closest replica using Tapestry • Take advantage of Tapestry’s locality properties • Should minimize use of long-distance links • A sort of poor man’s CDN
Performance Results: Stream Benchmark • Goal: measure efficiency of dissemination tree • Multicast tree between secondary replicas • Ran 500 virtual nodes on PlanetLab • Primary replicas in SF Bay Area • Other replicas clustered in 7 largest PlanetLab sites • Streams writes to all replicas • One content creator repeatedly appends to one object • Other replicas read new versions as they arrive • Measure network resource consumption
Performance Results: Stream Benchmark • Dissemination tree uses network resources efficiently • Most bytes sent across local links as second tier grows • Acceptable latency increase over broadcast (33%)
Related Work • Distributed Storage • Traditional: AFS, CODA, Bayou • Peer-to-peer: PAST, CFS, Ivy • Byzantine fault tolerant storage • Castro-Liskov, COCA, Fleet • Threshold signatures • COCA, Fleet • Erasure codes • Intermemory, Pasis, Mnemosyne, Free Haven • Others • Publius, Freenet, Eternity Service, SUNDR
Conclusion • OceanStore designed as a global-scale file system • Design meets primary challenges • End-to-end encryption for privacy • Limited trust in any one host for integrity • Self-organizing and maintaining to increase usability • Pond prototype functional • Threshold signatures more expensive than expected • Simple dissemination tree fairly effective • A good base for testing new ideas
More Information and Code Availability • More OceanStore work • Overview: ASPLOS 2000 • Tapestry: SPAA 2002 • More papers and code for Pond available at http://oceanstore.cs.berkeley.edu