
Uploaded by
amable
1 SLIDES
116 VUES
10LIKES
Enhancing Natural Language Processing with UPenn Tagset Utilization
DESCRIPTION
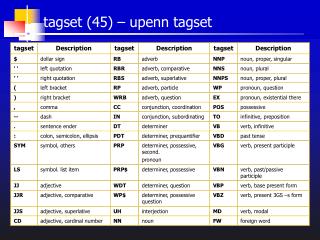
The UPenn Tagset is a widely-used system for part-of-speech tagging in natural language processing (NLP). This tagset, developed by the University of Pennsylvania, categorizes words in a sentence into defined grammatical categories, aiding in syntactic and semantic analysis. Leveraging the UPenn Tagset enables researchers and developers to improve language models, enhance text analysis, and facilitate more accurate machine learning applications. Understanding these categories is crucial for tasks such as text classification, sentiment analysis, and linguistics research.
Download
1 / 1
Télécharger la présentation 
Enhancing Natural Language Processing with UPenn Tagset Utilization
An Image/Link below is provided (as is) to download presentation
Download Policy: Content on the Website is provided to you AS IS for your information and personal use and may not be sold / licensed / shared on other websites without getting consent from its author.
Content is provided to you AS IS for your information and personal use only.
Download presentation by click this link.
While downloading, if for some reason you are not able to download a presentation, the publisher may have deleted the file from their server.
During download, if you can't get a presentation, the file might be deleted by the publisher.
E N D






















More Related