Download

1 / 23
240 likes | 264 Vues
GAMMA: An Efficient Distributed Shared Memory Toolbox for MATLAB. Rajkiran Panuganti 1 , Muthu Baskaran 1 , Jarek Nieplocha 2 , Ashok Krishnamurthy 3 , Atanas Rountev 1 , P. Sadayappan 1 1 The Ohio State University 2 PNNL 3 Ohio Supercomputer Center. Overview. Motivation

E N D
GAMMA: An Efficient Distributed Shared Memory Toolbox for MATLAB Rajkiran Panuganti1, Muthu Baskaran1, Jarek Nieplocha2, Ashok Krishnamurthy3, Atanas Rountev1, P. Sadayappan1 1 The Ohio State University 2 PNNL 3 Ohio Supercomputer Center
Overview • Motivation • GAMMA Programming Model • Implementation Overview • Experimental Evaluation • Conclusions
High Productivity Computing • Programmers’ productivity is extremely important • C/Fortran – Good performance but poor productivity • Parallel Programming in C/Fortran even harder • MATLAB, Python etc. – Good programmer productivity • Poor performance and inability to run large scale problems (memory limitations)
MATLAB and High Productivity • Numerous features resulting in High Programmer Productivity: • Array Based Semantics • Copy/Value based semantics • Debugging and Profiling Support • Integrated Development Environment • Numerous Domain Specific libraries (Toolboxes) • Visualization • And a lot more...... • Need to retain above features while addressing performance Issues
Problem Out-Of-Memory! Performance! Out-Of-Memory! 199 sec 10.19 s
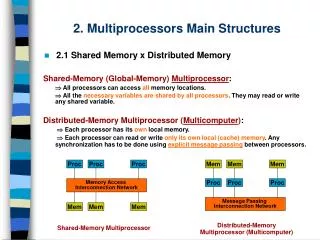
user user ParaM :- ‘Parallel MATLAB’ USER DParaM GAMMA Specialized Libraries mexMPI Library Writers Compiler MATLAB GA + MVAPICH GA + MVAPICH
Overview • Motivation • GAMMA Programming Model • Implementation Overview • Experimental Evaluation • Conclusions
Programming Model • Global Shared View of the distributed Array Physical View Logical View (1,1) P0 P1 (250,75) (700,610) P2 P3 (1024,1024) A = GA([1024, 1024],distr); Block = A(250:700,75:610);
Programming Model (Contd..) • Get-Compute-Put Computation Model Get() Put() Put() Process 0 Get() Compute Process 1 Compute
Other features in the Programming Model enabling Efficiency • Pass-by-reference semantics for distributed arrays • Intended for Library writers • Management of Data Locality (NUMA) • Distribution information can be retrieved by the programmer • Reference based access to the local data • Data replication • Support for replicating near-neighbor data
Other features in the Programming Model enabling Efficiency Contd.. • Asynchronous operations • Support for Library Writers • Interoperable with ‘Message Passing’ • Message Passing support using ‘mexMPI’ • Interoperable with some other ‘Parallel MATLAB’ projects • Interoperable with pMATLAB, Mathworks DCT
Illustration by Example (FFT2) – 2D FFT [rank, nprocs] = Begin(); dims = [N N]; distr = [N N/nproc]; A = GA(dims, distr); tmp=local(A); % GET() tmp = fft(tmp); % Compute() Put(A,tmp); % PUT() Sync(); ATmp = GA(A); Transpose(A,ATmp); % Collective Ops Tmp = local(ATmp); Put(ATmp,fft(Tmp)); Sync(); Transpose(ATmp,A); GA_End(); Transpose
Implementation Overview User MATLAB Front-End GAMMA mexMPI MATLAB Computation Engine GA MPI SCALAPACK
Overview • Motivation • GAMMA Programming Model • Implementation Overview • Experimental Evaluation • Conclusions
Evaluation • OSC Pentium 4 Cluster • Two 2.4 GHz Intel P4 processors per node, Linux kernel 2.6.6 , 4GB RAM, • MVAPICH 0.9.4 • Infiniband • MATLAB Version 7.01 • Fully distributed environment • Evaluation using NAS Benchmarks
Programmability Moderate Increase in SLOC Moderate Increase in SLOC Moderate Increase in SLOC Slight Increase in SLOC
Related Work • Early 90’s – MPI & Cluster Programming • 1995 – ‘Why there isn’t a Parallel MATLAB?’ – Cleve Moler • Embarrassingly Parallel • Paralize(’98); Multi(’00); PLab(‘00); Parmatlab(‘01); • Message Passing • MultiMatlab(’96); PT(’96); DPToolbox(‘99); MATmarks(‘99); PMI(’99); MPITB/PVMTB(‘00); CMTM(‘01); • Compilation Based • Conlab(‘93); Falcon(’95); ParAL(‘95); Otter(‘98); Menhir(’98); MaJIC(’98); MATCH(‘00); RTExpress(’00); • Backend Support • Matpar(‘98); DLab(‘99); Netsolve(‘01); Paramat(‘01);
Related Work (Currently Active) • Star-P (’97) – MIT • MatlabMPI(’98); pMATLAB(’02) – MIT-LL; • File-based Message Passing Communication • MATLAB_D (’00) – Rice • Telescoping Compilation + HPF + JIT Compilation • ParaM (’04) – OSU & OSC • Mathworks(’04) – MDCE/MDCT
Conclusions • Discussed an efficient Distributed Shared Memory Toolbox for MATLAB • Programming Model and Efficiency features of the toolbox • Demonstrated efficiency using NAS Benchmarks • Download available upon request
Questions ? Contact: panugant@cse.ohio-state.edud