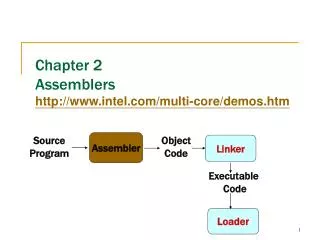
Multi-Core System on Chip 설계 동향 2 발표 : 조준동 교수 2003 년 12 월
Multi-Core System on Chip 설계 동향 2 발표 : 조준동 교수 2003 년 12 월. What is Software Radio. - A transceiver in which all aspects of its operation are determined using versatile general purpose hardware whose configuration is under software control


Multi-Core System on Chip 설계 동향 2 발표 : 조준동 교수 2003 년 12 월
E N D
Presentation Transcript
Multi-Core System on Chip설계 동향 2발표: 조준동 교수 2003년 12월
What is Software Radio - A transceiver in which all aspects of its operation are determined using versatile general purpose hardware whose configuration is under software control - Flexible all-purpose radios that can implement new and different standards or protocols through reprogramming. - Same hardware for all air interfaces and modulation schemes
Key Technological Constraints • High speed wide band ADCs. • High speed DSPs. • Real Time Operating Systems (isochronous software) • Power Consumption
Research and Commercialization • DARPA’s Adaptive computing system project • Virginia Tech –algorithms and architecture ; multi user receiver based on reconfigurable computing ; generic soft radio architecture for reconfigurable hardware • UC Berkeley –Pleiades, ultra low power, high performance multimedia computing ; high power efficiency by providing programmability • Sirius Inc –Software Reconfigurable Code Division Multiple Access (CDMAx)
Research and Commercialization • Brigham Young University –Development of JHDL to facilitate hardware synthesis in reconfigurable processors • Chameleon Systems- Reconfigurable Platform Architecture for wireless base station • MorphIC Inc -Programmable hardware reconfigurable code using DRL • Quicksilver Tech. Inc –Universal Wireless `Ngine (WunChip) baseband algorithms
Applications • User Applications and Base Station Applications • Evolve as a universal terminal • Spectrum management: Reconfigurability is a big advantage • Application updates, service enhancements and personalization
Programmable OFDM-CDMA Tranceiver. • CDMA suffers from Multiple access interference and ISI. • OFDM reduces interference and helps better spectrum utilization and attainment of satisfactory BER. • It is proposed that this might be implemented by using SDR.
SDR Architecture Hitachi Kokusai Electric Inc., teshima.isao@h-kokusai.com
Signal processing/control unit • The signal processing/control unit consists of the following module • Data converter • Quadrature Modem • Baseband Modem • Interface/Control • Every module is connected to each other by PCI bus, and provides a CPU in addition to the FPGA and DSP devices.
Quadrature modem module • The Quadrature modem uses FPGAs to process to generate baseband sampling rate • Quadrature modulation • Quadrature detection • Sampling rate conversion • Filtering
Baseband modem module • The Baseband modem processes • Multi-channel modulation • Multi-channel demodulation • Using four floating points DSP devices • individual DSP is assigned for each channel. Therefore, even if processing of either channel is under execution, a program can be downloaded to another channel.
A SDR/Multimedia SolutionW-CDMA / DAB / DVB / IEE802.11x; MPEG / JPEG Codecs
Architecture Goals • Provide template for the exploration of a range of architectures • Retarget compiler and simulator to the architecture • Enable compiler to exploit the architecture • Concurrency • Multiple instructions per processing element • Multiple threads per and across processing elements • Multiple processes per and across processing elements • Support for efficient computation • Special-purpose functional units, intelligent memory, processing elements • Support for efficient communication • Configurable network topology • Combined shared memory and message passing
Memory Memory Memory Memory RegFile RegFile FU FU FU FU FU RegFile RegFile DCT HUF FU FU FU ICache DCT HUF FU FU FU ICache ICache Architecture Template • Prototyping template for array of processing elements • Configure processing element for efficient computation • Configure memory elements for efficient retiming • Configure the network topology for efficient communication ...configure memory elements... ...configure PE... ...configure PEs and network to match the application...
Future Processing Element • Specialized memory systems for efficient memory utility • Multi-ported, banked, levels, and intelligent memory • Split register file allows greater register bandwidth to FUs • Groups of functional units have dedicated register files • Multiple contexts for a processing element provide latency tolerance • Hardware for efficient context switching to fill empty instruction slots • Specialized functional units and processing elements • SIMD instructions • Re-configurable fabrics for bit-level operations • Re-use IP blocks for more efficient computation • Custom hardware for the highest performance
PE PE PE PE PE PE PE PE PE PE PE PE PE PE PE PE PE PE Initial Distributed Architecture • Array of concurrent PEs and supporting network • Malleable network topology • Topology matches application • Efficient communication • Memory organized around a PE • Each PE has physical memory • Message passing between PEs
Future Distributed Architecture • Multiple processing elements share a memory space • Shared memory communication • Snooping cache coherency protocol • Directory based protocol required if PEs in a shared memory space is large • Introspective processing elements • Use processing elements to analyze the computation or communication • Identify dynamic bottlenecks and remove them on the fly • Reschedule and bind tasks as the introspective elements report
So What’s Different? • Traditional application hw/sw design requires • Hand selection of traditional general purpose OS components • Hand written customization of • device drivers • memory management… • Instead… • Application specific synthesis of OS components • scheduling • synchronization… • Automatic synthesis of hardware specific code from specifications • device drivers • memory management…
ASIP Design • Given a set of applications, determine micro architecture of ASIP (i. e., configuration of functional units in datapaths, instruction set) • To accurately evaluate performance of processor on a given application need to compile the application program onto the processor datapath and simulate object code. • The micro architecture of the processor is a design parameter!
Compiler Goals • Develop a retargetable compiler infrastructure that enables a set of interesting applications to be efficiently mapped onto a family of fully programmable architectures and microarchitectures. • 10 Year Vision: • Will have fully automatically-retargetable compilation, OS synthesis, and simulation for a class of architectures consisting of multiple heterogeneous processing elements with specialized functional units / memories • Compiled code size and performance will be within 10% of hand-coding
Compiler Research Issues • Synthesis of RTOS elements in the compiler • On the application side: Generation of an efficient application-specific static/run-time scheduler and synchronization • On the hardware side: Generation of device drivers, memory management primitives, etc. using hardware specifications • Automatic retargetability for family of target architectures while preserving aggressive optimization • Automatic application partitioning • Mapping of process/task-level concurrency onto multiple PEs using programmer guidance in programmer’s model • Effective visualization for family of target architectures
An Efficient Architecture Model for Systematic Design of Application-Specific Multiprocessor SoC DATE’ 2001 Amer Baghdadi Damien Lyonnard Nacer-E. Zergainoh Ahmed A. Jerraya TIMA Laboratory, Grenoble, France
Efficient application-specific multiprocessor design • Modularity • Flexibility • Scalability
A multiprocessor architecture platform for application-specific SoC design(1) Figure 1. A multiprocessor architecture platform
A multiprocessor architecture platform for application-specific SoC design(2) • Architecture platform parameters • Number of CPUs, • Memory sizes for each processor • I/O ports for each processor • Interconnections between processors • Communication protocols and the external connections (peripherals)
Application-specific multiprocessor SoC design flow (1) • Figure 2. The Y-chart: MFSAM-based architecture generation scheme
Application-specific multiprocessor SoC design flow(2) • Figure 3. MFSAM-based architecture generation flow for multiprocessor SoC
Architecture design(1) • Figure 4. Communication Interface
Architecture design(2) • Figure 5. Block diagram of the packet routing switch • (Point to Point network)
Architecture validation • Figure 6. A 4-processor cosimulation architecture of the packet routing switch
Analyzing the design cycle (1) • Figure 7. A 4-processor cosimulation architecture of the IS-95 CDMA
Analyzing the design cycle (2) • Table 1. Time needed to fit the IS95 CDMA on the multiprocessor platform
Conclusion • 1. Presented a generic architecture model for application- • specific multiprocessor system-on-chip design • 2. The proposed model is modular, flexible and scalable. • 3. Definition of the architecture model and a systematic • design flow that can be automated.
A Single-Chip Multiprocessor • Currently, processor designs dynamically extract parallelism by executing many instructions within a single, sequential program in parallel. • Future performance improvements will require processors to be enlarged to execute more instructions per clock cycle. • Two alternative micro-architectures that exploit multiple threads of control • SMT : simultaneous multithreading • CMP : chip multiprocessor
A Single-Chip Multiprocessor • Exploiting parallelism • Loop level parallelism results when the instruction level parallelism comes from data independent loop iterations. • Some compiler can also divide a program into multiple threads of control, exposing thread level parallelism. • A third form of very coarse parallelism, process level parallelism, involves completely independent applications running in independent processes controlled by the operations system.
Process Thread Levels of Parallelism Loop Instruction 1 10 100 1K 10K 100K 1M Grain Size (instructions) Exploiting Program Parallelism
SMT (simultaneous mutlithreading) • SMT processors augment wide (issuing many instructions at once) superscalar processors with hardware that allows the processor to execute instructions from multiple threads of control concurrently • Dynamically selecting and executing instructions from many active threads simultaneously. • Higher utilization of the processor’s execution resources • Provides latency tolerance in case a thread stalls due to cache misses or data dependencies. • When multiple threads are not available, however, the SMT simply looks like a conventional wide-issue superscalar.
Single-vs Multi-threaded single-threaded/blocking: CPU waits for accelerator; multithreaded/non-blocking: CPU continues to execute along With accelerator.
Mutithreading • Multiple threads to share the functional units of a single processor in an overlapping fashion. • The processor must duplicate the independent state of each thread. (register file, a separate PC, page table) • Memory can be shared through the virtual memory mechanisms, which already support multiprocessing • Needs hardware support for changing the threads.
Single-Chip Multiprocessor • CMPs use relatively simple single-thread processor cores to exploit only moderate amounts of parallelism within any one thread, while executing multiple threads in parallel across multiple processor cores. • If an application cannot be effectively decomposed into threads, CMPs will be underutilized.
Instruction Issue Reduced function unit utilization due to dependencies
Superscalar Issue Superscalar leads to more performance, but lower utilization
Simultaneous Multithreading Maximum utilization of function units by independent operations
Super scalar Architecture Issue up to 12 instructions per cycle
SMT Architecture 8 separate PCs , executes instructions from 8 diff thread concurrently Multi bank caches