Download

1 / 32
330 likes | 529 Vues
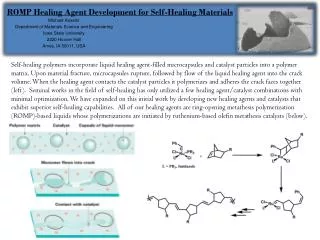
Visa Holopainen, visa@netlab.tkk.fi. Resiliency and self-healing. Reinforcement Learning for Autonomic Network Repair , M. Littman, N. Ravi, E. Fenson, R. Howard, 2004. Reinforcement learning Used to solve Markov decision problems (MDPs)

E N D
Visa Holopainen, visa@netlab.tkk.fi Resiliency and self-healing
Reinforcement Learning for Autonomic Network Repair, M. Littman, N. Ravi, E. Fenson, R. Howard, 2004 Reinforcement learning Used to solve Markov decision problems (MDPs) States, actions, rewards, transitions, transition probabilities Agent explores an environment in which it perceives its current state and takes actions to reach new states A reward is assosiated to every state Reinforcement learningtries to find a policy for maximizing cumulative reward for a task
(Simplified) Reinforcement Learning example Goal State Agent Goal State • Which direction should the agent move?
Reinforcement Learning example (cont) Goal State | V | V Goal State + Agent • Agent makes random moves until a Goal state is reached
Reinforcement Learning example (cont) Goal State Goal State • Now a policy is associated with the state from which the goal state was reached
Reinforcement Learning example (cont) Goal State S’ S Goal State • Now if at some point state S (that has policy associated to it) is reached from state S’, a policy is assigned to S’ also
Reinforcement Learning example (cont) Goal State Goal State • After some amount of iterations the optimal policies have been formed
Reinforcement Learning example (cont) Goal State -1 -2 -3 -1 -2 -3 -2 -2 -3 -2 -1 -3 -2 -1 Goal State • The corresponding state rewards
Implemented concept • Reinforcement learning is used to restore network connectivity after a failure • Starting state: no connectivity, Goal state: connectivity • Actions: PingGateway, PingIP, DNSLookup, UseCachedIP, FixIP, RenewLease, UseCachedIP • Learned policy in the picture • Prototype implemented • Nice concept but not very useful…
Approaches to Building Self HealingSystems using Dependency Analysis,J. Gao, G. Kar, P. Kermani, 2004 Problems Is there a way to automatically determine the root cause(s) of a downgraded performance of i.e. an Internet shopping site Provided that the root cause(s) can be determined, are there some ways to automatically fix this problem
Architecture • Distributed System • A typical multi-tier e-Business system (web access, database) • The Monitoring System • Includes monitoring agents that monitor 1) the response time of the system from user’s perspective and 2) the application components (servlets, EJBs,…) • The Dependency Matrix • Which transactions depend on which system components • Self-healing Engine • Launched when a performance problem is noticed by monitoring system
Problem description • Based on previous work a dependency matrix can be formed • The matrix informs which customer transactions depend on which system resources • Using this matrix the system resource that causes a preformance problem can be tracked • The initial goal was to minimize the needed transactions to find the root cause of a problem • This problem is found to be NP-hard -> a heuristic solution is presented
Solution No solution can be guaranteed to be found if two or more matrix columns are similar Assume that 1) all matrix colums are different and 2) there is only one broken system component Now the solution can be found by the following algorithm The set of all resources is denoted S. The set of all transactions is denoted T Run all transactions one by one If a trasaction succeeds then remove all resources that this trasaction depends on from S. Finally only one resource is left in S. This is the broken resource.
Solution (cont) If the fixed set of customer transactions cannot locate the root cause of performance problem, synthetic transactions need to be created and executed Many practical difficuties exists in doing so No testing
Ensembles of Models for Automated Diagnosis of System Performance Problems,S. Zhang, I. Cohen, M. Goldszmidt, J. Symons, A. Fox, 2005 Ensemble = collection SLA contains Service Level Objectives (SLO) SLO example: “Server downtime < X sec in a day” Problem: Which system metrics correlate with SLO violations? Example system metrics: CPU metrics, Memory, I/O, Network activity coming in and out of servers, Swapspace usage, Paging, etc… Tree Augmented Naïve Bayes (TAN) models Determine which low-level metrics most likely contributed to an SLO violation A mapping function is learned by the algorithm
TAN model example • ”Given SLO state (SLO violation) S, what is the most predictive set of system-level metrics for S” • Combinations of metrics more predictive of SLO violations than individual metrics • Small numbers of metrics (3-8) usually sufficient to predict SLO violation
Multiple TAN models TAN models that are built using data collected under some conditions don't work well on data collected under different conditions -> need to maintain multiple TAN models The model that best suits the current conditions is chosen by using Brier score Brier score is similar to Mean Squared Error (MSE) and offers a fine grained evaluation of a model
Results • Ensembles of models outperform single model • Also do slightly better than workload specific approach • Indicates that some workload conditions too complex for single model BA = Balanced Accuracy FA = False Alerts Det = Detections
TAN summary Ensemble of models perform better than single model The approach allows for rapid adaptation to changing conditions No domain specific knowledge is required Different workloads seem to be characterized by different metric-attribution “signatures” (future work)
Towards Autonomic Web Services: Achieving Self-Healing Using Web Services, S. Gurguis, A. Zeid, 2005 • CBE-log is a representation format into which log files of all different applications can be converted • Diagnosis Engine selects a set of repair actions • The Symptoms Database is an XML-file containing symptoms and recovery actions • Rule Engine decides which repair actions should be taken based on the Policy Database • No prototype implemented
A typical record in the Symptom Database presented in the picture • Possible application: legacy systems
Reflection, Self-Awareness and Self-Healing in OpenORB, G. Blair, G. Coulson, et al. 2002 OMG (Object Management Group) An open membership, not-for-profit consortium that produces and maintains computer industry specifications for interoperable enterprise applications OMG CORBA (Common Object Request Broker Architecture) Open, vendor-independent architecture and infrastructure that computer applications use to work together over networks Supports communication between different types of operating systems, programming languages and networks Interfaces defined in OMG IDL (Interface Definition Language) Mappings exists between IDL and C, C++, Java, COBOL, Smalltalk, Ada, Lisp, Python, and IDLscript OpenORB Provides a Java implementation of the OMG CORBA 2.4.2 specification
OpenORB self-healing Meta-interface supports access to the underlying platform Open ORB supports the ability to discover meta-information about the current system, both in terms of its structure and ongoing behaviour System properties can also be adapted by using the appropriate meta-interfaces Management component can be introduced (dynamically) into the various meta-space models ??
Measuring the Effectiveness of Self-Healing Autonomic Systems, A. Brown, C. Redlin, 2005 SPEC (Standard Performance Evaluation Group) Non-profit corporation that maintains a standardized set of relevant benchmarks applicable to the newest generation of high-performance computers SPEC jAppServer2004 Benchmark for measuring the performance of J2EE application servers An end-to-end application which exercises all major J2EE technologies Based on jAppServer2004 a benchmarking system was created that is capable of quantifying the autonomic self-healing capability of a large-scale J2EE software solution The system is used in various production environments
The Architecture • 30 different types of disturbances representing common failure modes can be injected into the SUT • Component shutdowns, data loss, resource exhaustion, load surges, operator errors, ... • Two metrics are used to evaluate SUT’s self-healing capacity • How effectively the SUT heals itself • Basically measured by counting how many requests the jAppServer2004 gets right in case of disturbance while compared to normal working conditions • How autonomic the healing response is • A 90-question survey is used
The Survey The 90-question survey assigns points to the SUT based on the level of automation present in its response to each disturbance (based on IBMs autonomic computing maturity model) 0 points for a basic manual response, 1 point for a managed response, 2 for predictive, 4 for adaptive, and 8 for autonomic “...Our baseline run on SUT #1 resulted in an average healing effectiveness score of 0.79 and an autonomic maturity score of 0.15 (both out of 1.0), indicating a relatively low level of autonomic self-healing capability. In comparison, SUT #2 attained an effectiveness score of 0.83 and a maturity score of 0.22. Comparing the two results indicates that SUT #2’s system management technology provided a small—but measurable—improvement in autonomic capability...”
Personal Autonomic Computing Self-Healing Tool, R. Sterritt, S. Chung, 2004 A self-healing tool consisting of pulse monitor and a health monitor Used in PC-environment Pulse Monitoring application (PBM) is an UDP-based peer-to-peer application which Checks whether hosts are providing a ‘heartbeat’ or not and Indicates the health level of the system (state of processes) Reboots a neighbor if no heartbeat is heard from it (security?) Health Monitoring runs on a host and restarts a process on the same host if it’s not responding Combines three old concepts: watchdog processes, hello-mechanism, and remote control
The Architecture • Pulse Monitor (Java) communicates with platform-specific Health Monitor (C) through JNI • Main monitor monitors Pulse monitor and Health monitor
Testing A proof-of-concept prototype system was built on MS. Windows platform Future topics: more autonomic functionality & supported platforms Maybe useful when human administration not possible (sensor networks?)
Conclusions Reinforcement Learning for Autonomic Network Repair Learn autonomically the best sequence of actions to repair a network outage Prototype implemented and tested (useful?) Approaches to Building Self Healing Systems using Dependency Analysis Determine the root-cause of downgraded performance and try to fix it No testing, use 3. instead? Ensembles of Models for Automated Diagnosis of System Performance Problems Suitable (tested) system for (Hewlett Packard) server systems Pinpoints causes of SLO violation Towards Autonomic Web Services: Achieving Self-Healing Using Web Services Autonomic web server healing system No testing
Conclusions Reflection, Self-Awareness and Self-Healing in OpenORB ? Measuring the Effectiveness of Self-Healing Autonomic Systems Suitable system for J2EE server systems Provides users with a quantitative way to measure the self-healing capability of their IT systems Implemented and in use Personal Autonomic Computing Self-Healing Tool Enables a group of PCs to monitor the health of each other Applications? Prototype implemented Overall much discussion about server self-healing