System R: Relational Approach to Database Management
390 likes | 665 Vues
System R: Relational Approach to Database Management. CIS 661 Data Management Course Instructor: Vasilis Megalooikonomou By: Sarika Notani. Contents:. Introduction Architecture & System Structure Relational Data System Host Language Interface Query Facilities

System R: Relational Approach to Database Management
E N D
Presentation Transcript
System R: Relational Approach to Database Management CIS 661 Data Management Course Instructor: Vasilis Megalooikonomou By: Sarika Notani
Contents: Introduction Architecture & System Structure Relational Data System Host Language Interface Query Facilities Data Manipulation Facilities Data Definition Facilities Data Control Facilities Optimizer Modifying Cursors Simulation of Nonrelational Data Models
Contents: Relational Storage System Segments Relations Images Links Transaction Management Concurrency Control System Checkpoint and Restart Summary and Conclusion
Introduction: System R is a database management system which provides a high level relational data interface. Why a relational approach? (advantages) To provide solutions to various problems in database management. For example: Data independence problems. Providing database user with a very high level, non- procedural data sublanguage for accessing data. Currently being implemented and evaluated at the IBM San Jose Research Laboratory.
Introduction: Permits definition of a variety of relational views on common underlying data. Includes data control features like Authorization Integrity assertions Triggered transactions Logging and recovery subsystem Facilities for maintaining data consistency in a shared-update environment
Introduction: Comparison with other Relational Systems: It is the only relational system which provides a complete database management capabilities-including application programming, query capability, concurrent access support, system recovery etc. Other systems provide solutions to various specific problems only. E.g.. The extended relational memory (XRM) system developed at the IBM Cambridge Scientific center has been used as a single user access method by other relational systems.
Architecture and System Structure Can be described from two viewpoints System as seen by a single transaction (monolithic) System as seen by multi-users Current operating system environment is VM/370. Implements technique for the selective sharing of read/write virtual memory across any number of virtual machines through processor interrupts- supports multi-user. Supports concurrent transactions-for each logged-on user there is a dedicated database machine which contains all code and tables needed to execute all data management functions.
Architecture and System Structure Monitor machine Contains system administrator facilities like Controls logon authorization Schedules periodic checkpoints Maintains usage and performance statistics for reorganization and accounting purposes
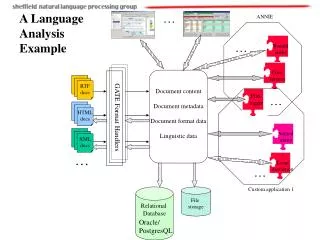
Architecture and System Structure RDS RSS M1 Programs to support various interfaces . . . . . . M n RDI Relational Data System Monitor RSI Relational Storage System Architecture of System R Use of Virtual Machines in System R
Relational Data System Relational Data Interface (RDI): Principal external interface which can be called directly from a programming language or used to support various emulators and other interfaces. Functions: Data retrieval Data manipulation and definition- By high level SEQUEL language which is embedded within RDI Data definition allows a variety of alternative relational views to be defined on common underlying data. Data control
Relational Data System The SEQUEL language can be supported: As a stand-alone interface by a simple program, written on top of RDI & it handles terminal communications-Such an interface is called User-Friendly Interface (UFI) Programs may be written on top of the RDI to support other relational interfaces, such as Query By Example.
Host Language Interface RDI Operators: SEQUEL: associates a cursor with the set of tuples which satisfy the query & position it just before the first such tuple. No tuples are actually materialized. FETCH: Retrieves tuple, one at a time. BIND: gives the system the addresses of the program variables to be used into which the resulting tuples are to be delivered. Here, the degree & data types of the tuples to be retrieved is known. CALL BIND (‘X’, ADDR (X)); CALL SEQUEL (C1, ‘SELECT NAME:X FROM EMP WHERE JOB = ‘‘CLERK’’ ’); CALL FETCH (C1); In case, the degree & data are not known, the program issues a SEQUEL query, followed by DESCRIBE operator-(returns the degree & data types). Then specify the destination of the tuples in FETCH commands.
Host Language Interface OPEN: shorthand method to associate a cursor with an entire relation preferable to SEQUEL to open a cursor on a relation –as OPEN avoids the use of the SEQUEL parser. CLOSE: deactivates a cursor KEEP: tuples identified by a cursor are copied to form a new permanent relation in the database, having specified relation name & field name FETCH-HOLD: for explicit locking Same as FETCH except that it acquires a “hold” on the tuple returned RELEASE: Releases the tuple on which the cursor is positioned. If no cursor is furnished, it releases all tuples currently held by the user.
Query Facilities: One important change made to the SEQUEL Query facilities since their original publication is handling of Block labels, which were replaced by more symmetrical notation. JOIN Operator: Joins table in the FROM clause Joins row in the WHERE clause Queries are processed in the following order: Tuples are selected by the WHERE clause Groups are formed by the GROUP BY clause Groups are selected which satisfy the HAVING clause ORDER BY: Allows user to specify a value ordering for his query result.
Query Facilities: OF CURSOR ON: Allows a query to qualify tuples by comparing them with the current tuple of some active cursor SELECT * FROM EMP WHERE DNO = DNO OF CURSOR C5 ON DEPT Since elimination of duplicates from a query result is an expensive process, RDS does not eliminate duplicates unless explicitly requested – (UNIQUE).
Data Manipulation Facilities: Insertion Deletion Update CURRENT TUPLE OF CURSOR: a predicate which selects the current tuple of a particular cursor for some operation. CALL SEQUEL (‘UPDATE EMP SET SAL = PVSAL WHERE CURRENT TUPLE OF CURSOR C3’); BIND: sets value of the tuple to constants, or to new values computed from the old values, or to the content of a program variable INSERT: provide only some of the values for the new tuples, specifying the field names. Fields which are not provided are set to null. ASSIGNMENT: same as KEEP.
Data Definition Facilities: Invoked by RDI operator SEQUEL SEQUEL commands: CREATE TABLE: creates new base relation DROP TABLE: it deletes base relation DEFINE VIEW: used to define a view as a relation derived from one or more relations. Queries can be written against it, other views may be defined on it and may be updated if the tuples of the view are associated one-to-one with tuples of an underlying base relation. KEEP TABLE: causes a temporary table to become permanent Temporary tables are destroyed when the user who creates them logs off. EXPAND TABLE: adds a new field to an existing table all views, images and links defined on the original table are retained.
Data Definition Facilities: DROP VIEW: indicated view and all other views defined in terms of it disappear from the system. System R currently relies on the user to specify RSS access paths to be maintained on the base tables. Access path include images and binary link which may be specified by means of create and drop They do not contain any logical information other than that derivable from the data values themselves RDI user has no explicit control over the placement of tuples in images and links nor can explicitly use an image or link for accessing data- all choices are made automatically by the optimizer.
Data Control Facilities: Has four aspects: Transactions: Is a series of RDI calls which the user wishes to be processed as an atomic act. User controls transactions by BEGIN_TRANS and END_TRANS. SAVE: to save points within a transaction RESTORE: back up to the beginning of transaction or to any internal save point. It restores changes made to the database and cursors involved. The RDI transactions are implemented directly by RSI transactions.
Data Control Facilities: Authorization: CREATE TABLE, DEFINE VIEW: each user creates his own data object. Creator receives full authorization to perform all operations on the object. GRANT: Grant selected capabilities for his object to other users. System R relies on its view mechanism for read authorization-USER interpreted as the user id of the current user. Integrity assertions ASSERT: when made, its truth is checked and if true assertion is automatically enforced. ASSERT ON UPDATE TO EMP: NEW SAL >= OLD SAL DROP ASSERTION: assertion is explicitly dropped. Are checked and enforced at the end of each transactions.
Data Control Facilities: IMMEDIATE: Assertion cannot be suspended within a transaction and is enforced after each data modification (each RDI call). ENFORCED INTEGRITY: establishes “integrity points” within a transaction. Trigger Causes a pre specified sequence of SEQUEL statements to be executed whenever some triggering event occurs. The RDS automatically maintains a set of catalog relations which describe other relations, views, images, links and triggers. DEFINE TRIGGER EMPINS ON INSERTION OF EMP: (UPDATE DEPT SET NEMPS = NEMPS + 1 WHERE DNO = NEW EMP. DNO)
Optimizer Attempts to minimize the expected number of pages to be fetched from secondary storage into the RSS buffers during execution of the statements. Since cost measure is based on disk page accesses, the physical clustering of tuples in the database is of great importance. Each relation may have at most one clustering image- that’s why tuples near each other in the image ordering are stored physically near each other in the database. Begins by classifying the SEQUEL statement according to features like join and GROUP BY.
Optimizer It then examines system catalogs to find the set of images and links related to the given statement. A rough decision procedure is executed to find methods of executing the statement- if more then one method, minimum-cost method is chosen. After analyzing the statement, the optimizer produces an Optimized Package (OP) containing the parse tree and a plan for executing the statement.
Modifying Cursors When modification is made to one of the tuples in the active set of cursors it may change the ordinal position of the tuple or even disqualify it. If a cursor is opened on a base relation the modification is done and immediately becomes visible via the cursor. If the cursor is on result of a SEQUEL query then any modification in the underlying relation results in “potentially invalid” answer list.
Simulation of Nonrelational Data Models Dept EMP Equip
The RDI is designed in such a way that programs can be written on top of it to simulate “navigation oriented” database interfaces. • These interfaces are characterized by collections of records connected in a network structure. • To represent each record as a relation and to represent information about ordering and connections between records in the form of explicit fields. • At database definition time, a relation is created to simulate each record type. • Each DEPT relation must have a sequence-number field to represent the ordering of the DEPT records. • The EMP and EQUIP relations must have sequence-number and one or more fields identifying their “parent” records (assume the key of DEPT is DNO). • During optimization process, any direct physical support for the hierarchy will be discovered. Simulation of Nonrelational Data Models
Calls to the RSI require explicit use of data areas called segments & access paths called images & links • Provides a degree of data independence at a low level of the system • RSI has been designed so that new relations, indexes, adding new fields to the existing relations can be created anytime, or existing ones destroyed, without quiescing the system & without dumping & reloading the system. • RSS include: • Dynamic definition of new data types & access paths • Dynamic binding & unbinding of disk space to data segments • Efficient technique for system checkpoint & restart The Relational Storage System
Multiple levels of isolation from the actions of other concurrent usres • Automatic locking at the level of segments, relations & single tuples • No parsing or optimization is done in response to a command to move the “current position”- system employs the POP for t he view which was optimized at database definition time. • System is capable of simulating connections which have no direct physical support – optimizer will find an appropriate access path. The Relational Storage System
In the RSS, all data is stored in a collection of logical address spaces called segments which are employed to control physical clustering • Used to store data, access path structures, internal catalog information & intermediate results generated by RDS • All tuples of any relation must reside within a single segment chosen by the RDS • A given segment may contain several relations • RSS has the responsibility for mapping logical segment spaces to physical extents on disk storage, & for supporting system recovery • Within the RSS, each segment consist of a sequence of equal sized pages • Physical page slots in the disk extents are allocated to segments dynamically upon first reference & are freed when access path structures or contents of the segment are destroyed the RSS maintains a page map for each segment, which is used to map each segment page to its location on disk Segments
Two separate buffers are managed-for page map blocks & other for segment pages themselves • To handle segment recovery, it associates two page maps, called current & backup, with each recoverable segment • OPEN_SEGMENT: makes the segment available for processing • SAVE_SEGMENT: disk pages bound to segments are brought up to date by storing through all buffer pages which have been updated • RESTORE_SEGMENT: current page is set equal to the backup page & newly allocated page slots are released Segments
The main data object of the RSS is the n -ary relation, which consists of time varying number of tuples, each containing n fields • A new relation can be defined at any time within any segment • An existing relation & its associated access path structures can be dropped anytime ,with all storage space made reusable • New fields can be added ,even after a relation is defined, without a database reload & without immediate modification to existing tuples • Two field types are supported: fixed & variable length • Operators: • INSERT & DELETE: single tuples • FETCH & UPDATE: any fields in a tuple • OPEN_SCAN: for fetching tuples on a particular access path Relations
Associated with every tuple of a relation is a tuple-identifier or TID • Each tuple is generated by RSS & is available to the RDS for addressing tuples • Each tuple is stored as a contiguous sequence of field values within a single page • A prefix is stored with the tuple within RSS-contains information like relation identifier, TIDs, no of stored data fields & no of pointer fields • Each tuple identifier is a concatenation of a page number within the segment, along with a byte offset from the bottom of the page Relations
Is a logical reordering of an n- ary relation with respect to values in one or more sort fields • RDS can rapidly fetch a tuple from an image by keying on the sort field values • Can also open a scan at a particular point in the image & retrieve a sequence of tuples or subtuples with a given range of sort values • A new image can be defined at any time on any combination of fields in a relation • RSS maintains each image through the use of a multi page index structure • Each index is composed of one or more pages within the segment containing the relation Images
A link in the RSS is an access path which is used to connect tuples in one or two relations • RDS determines which tuples will be on the a link & determines their relative position through explicit CONNECT & DISCONNECT operations • A link can be scanned using OPEN_SCAN & NEXT opeartion • A unary link involves a single relation & is used to maintain tuple ordering specifications • Access path is a binary link which provides a path from single tuples (parents) in one relation to sequences of tuples (children) in another relation-imp for supporting relational join operations & for navigational processing through network • A given tuple can appear only once within a given link • Advantages: • When the child tuple have been clustered on the same page as the parent, no extra pages are touched using the link-fast associative access • Links are maintained in the RSS by storing TIDs in the prefix of tuples • New links can be defined & an existing link can be dropped at anytime Links
Is a sequence of RSI calls issued in behalf of one user • Serves as a unit of consistency & recovery • RSS transaction consists of those calls generated by the RDS to execute all RDI operators in the transaction • An RSS transaction is marked by the START_TRANS & END_TRANS operations • SAVE_TRANS: returns a save point number for subsequent reference. • RESTORE_TRANS: issued by monitor or RDS, to undo all the changes made by that transaction to recoverable data since the given save point Transaction Management
Since System R is a concurrent user system, locking techniques must be employed for synchronization, both at physical level of pages & logical level of objects like relations & tuples • At the logical level, ”lost update” problem must be handled • Physical locking is handled by setting & holding locks on one or more pages during the execution of a single RSI operation • Logical locking is handled by setting locks on segments, relations, TIDs & key value intervals & holding them until they are explicitly released or at the end of transaction • System R automates all the locking functions, physical & logical • When a transaction is started at the RSI, one of the three consistency levels must be specified. The differences in the level occur during read operations • Level 1: offers least isolation from user, lowest overhead & lock contention-no locks required for read purposes • Level 2: read access require a share lock with immediate duration Concurrency Control
Level 3: eliminates the problem of lost updates & also guarantees reading a consistent version of tuples- share locks maintained on all tuples & index values for the duration of transaction • The RSS employs a single lock mechanism to synchronize access to all objects • A request to lock an object has several parameters: the name of the object, the mode of the lock (shared/exclusive etc),& the indication of the lock duration-depends on type of the action requested by the user & the level of transaction • If the RDS requests a lock in exclusive mode on a single relation but do not wish exclusive access to the entire segment, then RSS first generates a request for a lock in intent-exclusive mode on the segment, before requesting an exclusive lock on the relation • This intent-exclusive lock is compatible with other intent locks but incompatible with share & exclusive locks Concurrency Control
The RSS provides functions to recover the database to a consistent state in the event of a system crash: • First mechanism uses disk storage to recover in the event of “soft” failure which causes the contents of main memory to be lost-frequent checkpoints & rapid recovery • Second mechanism uses tape storage to recover in relatively infrequent case that disk storage is destroyed-less frequent checkpoint • The Monitor Machine schedules checkpoints • When a checkpoint is required, it quiesces all activity within RSS at a point of physical consistency • To halt RSS activity, a special RSS lock is acquired in exclusive mode which every activation of the RSS code acquires in share mode before executing an RSI operation, & releases at the end of the operation • Then Monitor issues SAVE_SEGMENT operator to bring relevant segments up to date. Then, RSS lock is released & transactions are allowed to resume • RESTORE_SEGMENT: restore contents of all saved segments System Checkpoints & Restart
Described the overall architecture of System R and two main component: RDS and RSS. • RSS is a concurrent user, data management subsystem which provides underlying support for System R. • RSI has operation at single tuple level, with maintenance of images, based on the values in one or more fields. • RSS supports dynamic addition and deletion of relations, indexes and links, with full space reclamation, and the addition of new fields to existing relations – all without special utilities or database reorganization. • Optimizer makes plans for efficient execution of high level operations using the RSS access path primitives. Summary and Conclusion